Periplus
v0.1.0-alpha.1
Periplus ist derzeit in Alpha und ist nicht produktionsbereit. Das Projekt befindet sich in aktiver Entwicklung und wird noch nicht für den Einsatz in Produktionssystemen empfohlen.
Periplus ist ein Open-Source-In-Memory-Vektor-Datenbank-Cache, das auf der Vector-Ähnlichkeitssorgungsbibliothek von Meta basiert. Das Projekt kann am besten als "Redis für Vektordatenbanken" betrachtet werden. Es wurde entwickelt, um eine dynamisch aktualisierte Teilmenge einer großen Vektorsammlung vollständig im Speicher zu speichern, während Abfragen nicht mit allen anderen Knoten zu interagieren. Wenn Periplus eine Anfrage erhält, wird zunächst bewertet, ob es den relevanten Teil des Index-In-Residence hat. Wenn dies der Fall ist, wird die Abfrage mit der entsprechenden Antwort gelöst. Wenn dies nicht der Fall ist, gibt es einen Cache -Miss zurück und lässt den Querier die Daten aus der Datenbank abrufen. Periplus ist nicht so konzipiert, dass er isoliert funktioniert. Stattdessen soll es eine modulare und flexible Caching -Schicht für eine separate Vektordatenbank bilden, die die Persistenanzschicht bildet. Der Zweck davon ist es, eine geringere Latenz und eine einfache horizontale Skalierung zur Erhöhung des Durchsatzes zu ermöglichen. Für eine detailliertere Beschreibung der Inspiration hinter Periplus und der Funktionsweise können Sie den Ankündigungsblog lesen: Einführung von Periplus: Ein neuer Ansatz zur Vektor -Datenbank -Caching.
Periplus verwendet einen invertierten Dateiindex (IVF) als Grundlage für die Cache -Verwaltung. Inverted File Indizes Partition Der Vektorraum in zusammenhängende Zellen, die durch eine Reihe von Zentroidvektoren definiert sind, in denen jede Zelle als die Region definiert ist, die näher an ihrem Schwerpunkt liegt als an jedem anderen Zentroid. Abfragen werden dann aufgelöst, indem zuerst die Entfernungen vom Abfragevektor zum Zentroidsatz berechnet werden und dann nur die vom N_PROBE (Suchhyperparameter) definierten Zellen am nächsten standen. Periplus nutzt dies aus, indem er zu einem bestimmten Zeitpunkt eine Untergruppe dieser Zellen im Wohnsitz aufnimmt und nur Abfragen auflöst, die für diese Teilmenge relevant sind, während sie diejenigen ablehnen, die nicht als Cache -Fehler sind. Periplus lädt und rägt ganze IVF -Zellen gleichzeitig, um die Integrität des Index aufrechtzuerhalten und einen äquivalenten Rückruf (bei Cache -Treffern) für einen Standard -IVF -Index sicherzustellen. IVF -Zellen werden durch Abfragen der Vektordatenbank über einen Proxy mit einer Liste von IDs von Vektoren geladen, die Periplus behauptet, die Vektoren zu verfolgen, welche Zellen. Diese Operationen können vom Benutzer mithilfe von Befehlen laden , such und räumen aufgerufen werden. Weitere Informationen finden Sie im Abschnitt Periplus Commands unten.
Periplus kann entweder als Docker -Container ausgeführt oder aus der Quelle erstellt und als ausführbare Datei ausgeführt werden. Derzeit sind keine offiziellen Binärdateien verfügbar. Das Ausführen von Periplus als Container ist der empfohlene Ansatz, aber beide sind praktikable Optionen.
Derzeit unterstützt das Docker -Bild nur AMD64 -Architekturen. Diese Einschränkung ergibt sich aus dem Basisbild, aber in naher Zukunft werden mehr Architekturen unterstützt. Es gibt zwei Möglichkeiten, Periplus als Container auszuführen: Laden Sie das offizielle Docker -Bild von DockerHub (empfohlen) herunter oder erstellen Sie das Bild selbst. Der erste Schritt in beiden Fällen besteht darin, Docker zu installieren, wenn Sie es noch nicht getan haben. Die Anweisungen, die dies tun, finden Sie hier.
docker image pull qdl123/periplus:latest .docker run -p 3000:3000 qdl123/periplus:latest git clone https://github.com/QDL123/Periplus.gitcd <path-to-periplus-repo>/Periplusdocker build -t periplus-image .docker run -p 3000:3000 periplus-image .Periplus verwendet CMake für sein Build -System. Es wird erwartet, dass alle Abhängigkeiten vorbereitete Binärdateien über Homebrew installiert haben. Homebrew wird von MacOS, Ubuntu und WSL unterstützt, wenn Sie unter Windows sind. Periplus wurde auf MacOS/ARM64 und Ubuntu/AMD64 gebaut. Alle anderen Betriebssysteme und Architekturkombinationen sind nicht getestet. Befolgen Sie die folgenden Schritte, um Periplus aus der Quelle zu erstellen:
brew install faiss curl cpr rapidjson libomp catch2 cmakegit clone https://github.com/QDL123/Periplus.gitcd <path-to-periplus-repo>/Peripluscmake -S . -B buildcmake --build build./build/periplus -p 3000 Jedes System, das Periplus verwendet, besteht aus 4 Komponenten: der Vektor -Datenbank, einem Datenbankproxy, mit dem Periplus Daten aus der Datenbank, eine Periplus -Instanz und eine Clientanwendung laden kann.
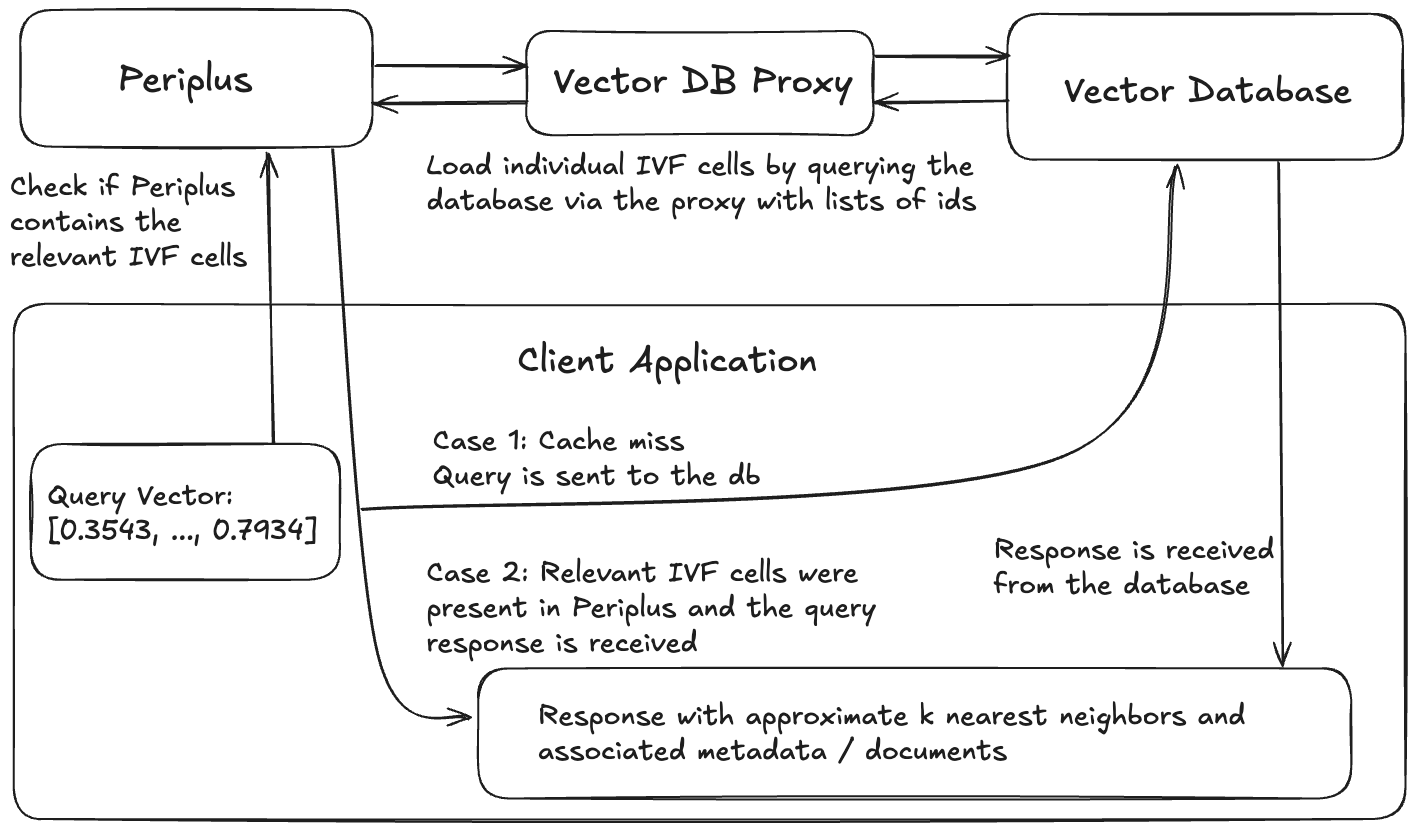
Beispielarchitektur einer Anwendung mit Periplus.
Jede Vektor -Datenbank, die die Suche nach Daten nach einer eindeutigen Kennung (praktisch alle) ermöglicht, funktioniert. Periplus ist für die Arbeit mit wirklich großen Vektor-Sammeln (Milliarden) am vorteilhaftesten ausgelegt, wobei der Index auf dem Dateisystem im Gegensatz zu RAM leben muss, obwohl dies keine Anforderung ist.
Der Zweck des Vector Database Proxy ist es, eine konsistente Schnittstelle für Periplus bereitzustellen, um mit der Vektor -Datenbank durchzusetzen. Der Proxy muss eine REST -Schnittstelle implementieren, die Postanforderungen des folgenden Formulars akzeptiert:
URL: Dies ist flexibel und kann vom Periplus -Kunden angegeben werden.
Header: "Content-Type": "application/json
Körper:
{
"ids" : [ " id-1 " , " id-2 " , " id-3 " ]
}Antwort:
{
"results" : [
{
"id" : " String " ,
"embedding" : [ 0.1 , 0.2 , 0.3 ],
"document" : " String " ,
"metdata" : " String "
}
]
}Um diesen Endpunkt zu vereinfachen, können Sie das Python-Paket Periplus-Proxy verwenden, mit dem Fastapi alles einstellt. Der Benutzer muss nur die folgende Funktion implementieren und als Argument übergeben:
async def fetch_ids(request: Query) -> QueryResult
Weitere Informationen dazu finden Sie im Periplus-Proxy-Paket Readme.md.
Befolgen Sie die obigen Anweisungen, um eine Periplus -Instanz zu starten.
Verwenden Sie die Periplus -Kundenbibliothek, um mit Ihrer Periplus -Instanz zu interagieren. Derzeit wird nur Python unterstützt. Weitere Informationen in der Client -Bibliothek finden Sie in Readme.md.
from periplus_client import Periplus
# host, port
client = Periplus ( "localhost" , 13 )
# vector dimensionality, database proxy url, options: (nTotal)
await client . initialize ( d = d , db_url = url , options = { "nTotal" : 50000 })
training_data = [[ 0.43456 , ..., 0.38759 ], ...]
await client . train ( training_data )
ids = [ "0" , ..., "n" ]
embeddings = [[ 0.43456 , ..., 0.38759 ], ...]
await client . add ( ids = ids , embeddings = embeddings )
load_options = { "n_load" : 2 }
# query_vector, optional: options object
await client . load ([ embeddings [ 0 ]] load_options )
# k, query_vector
response = await client . search ( 5 , [ embeddings [ 0 ]])
print ( response )
'''
[ // Results for each of the n query vectors in xq
[ // K nearest neighbors to this corresponding index in the xq list
(
id="n",
embedding=[0.43456, ..., 0.38759],
document="",
metadata="{}"
),
...
],
...
]
'''
# query_vector
await client . evict ( embeddings [ 0 ])Wir begrüßen Beiträge zum Periplus! Um zu lernen, wie man anfängt, schauen Sie sich den Beitragsführer an.
Dieses Projekt ist unter der MIT -Lizenz lizenziert - Einzelheiten finden Sie in der Lizenzdatei.


