Periplus
v0.1.0-alpha.1
Periplus est actuellement en alpha et n'est pas prêt pour la production. Le projet est en cours de développement actif et n'est pas encore recommandé pour une utilisation dans les systèmes de production.
Periplus est un cache de base de données vectoriel en mémoire open source construit sur la bibliothèque de recherche de similitude vectorielle de META FAISS. Le projet peut être considéré comme "Redis pour les bases de données vectorielles". Il est conçu pour stocker un sous-ensemble dynamiquement mis à jour d'une grande collection de vecteurs entièrement en mémoire tout en servant des requêtes sans interagir avec d'autres nœuds au moment de la requête. Lorsque Periplus reçoit une requête, il évalue d'abord s'il a la partie pertinente de l'indice en résidence. Si c'est le cas, il résout la requête avec la réponse appropriée. Si ce n'est pas le cas, il renvoie un cache manche et laisse le questionnaire pour récupérer les données de la base de données. Periplus n'est pas conçu pour fonctionner isolément. Au lieu de cela, il est destiné à former une couche de mise en cache modulaire et flexible pour une base de données vectorielle distincte qui forme la couche de persistance. Le but de cela est de permettre une latence plus faible et une échelle horizontale facile pour l'augmentation du débit. Pour une description plus détaillée de l'inspiration derrière Periplus et comment cela fonctionne, vous pouvez lire le blog d'annonce: Présentation de Periplus: une nouvelle approche de la mise en cache de base de données vectorielle.
Periplus utilise un indice de fichiers inversé (FIV) comme base de la gestion du cache. Index de fichiers inversés partitionner l'espace vectoriel en cellules contiguës définies par un ensemble de vecteurs centroïdes où chaque cellule est définie comme la région qui est plus proche de son centroïde que de tout autre centroïde. Les requêtes sont ensuite résolues en calculant d'abord les distances du vecteur de requête à l'ensemble des centroïdes, puis en ne recherchant que les cellules définies par le N_Probe (Hyperparamètre de recherche) les centroïdes les plus proches. Periplus en profite en gardant un sous-ensemble de ces cellules dans la résidence à tout moment et en résolvant uniquement les requêtes qui sont pertinentes pour ce sous-ensemble tout en rejetant celles qui ne sont pas au cache. Periplus charge et expulse des cellules de FIV entières à la fois pour maintenir l'intégrité de l'indice et assurer un rappel équivalent (sur des coups de cache) à un indice de FIV standard. Les cellules de FIV sont chargées en interrogeant la base de données vectorielle via un proxy avec une liste d'identifices de vecteurs que périplus maintient pour suivre les vecteurs qui occupent les cellules. Ces opérations peuvent être invoquées par l'utilisateur à l'aide de commandes de charge , de recherche et d'expulsion . Pour plus de détails, consultez la section des commandes Periplus ci-dessous.
Periplus peut être exécuté en tant que conteneur Docker, soit il peut être construit à partir de Source et s'exécuter en tant qu'exécutable. Aucun binaire officiel n'est actuellement disponible. L'exécution de périplus en tant que conteneur est l'approche recommandée, mais les deux sont des options viables.
Actuellement, l'image Docker ne prend en charge que les architectures AMD64. Cette contrainte découle de l'image de base, mais davantage d'architectures seront prises en charge dans un avenir proche. Il existe 2 façons d'exécuter Periplus en tant que conteneur: téléchargez l'image Docker officielle de Dockerhub (recommandé) ou créez l'image vous-même. La première étape dans les deux cas consiste à installer Docker si vous ne l'avez pas déjà fait. Les instructions pour le faire peuvent être trouvées ici.
docker image pull qdl123/periplus:latest .docker run -p 3000:3000 qdl123/periplus:latest git clone https://github.com/QDL123/Periplus.gitcd <path-to-periplus-repo>/Periplusdocker build -t periplus-image .docker run -p 3000:3000 periplus-image .Periplus utilise Cmake pour son système de construction. Il s'attend à ce que toutes les dépendances aient installé des binaires pré-compilés via Homebrew. Homebrew est pris en charge par MacOS, Ubuntu et WSL si vous êtes sous Windows. Periplus a été construit sur MacOS / ARM64 et Ubuntu / AMD64. Toutes les autres combinaisons de système d'exploitation et d'architecture ne sont pas testées. Pour construire Periplus à partir de la source, suivez les étapes suivantes:
brew install faiss curl cpr rapidjson libomp catch2 cmakegit clone https://github.com/QDL123/Periplus.gitcd <path-to-periplus-repo>/Peripluscmake -S . -B buildcmake --build build./build/periplus -p 3000 Tout système utilisant Periplus sera composé de 4 composants: la base de données vectorielle, un proxy de base de données qui permet à Periplus de charger des données à partir de la base de données, une instance Periplus et une application client.
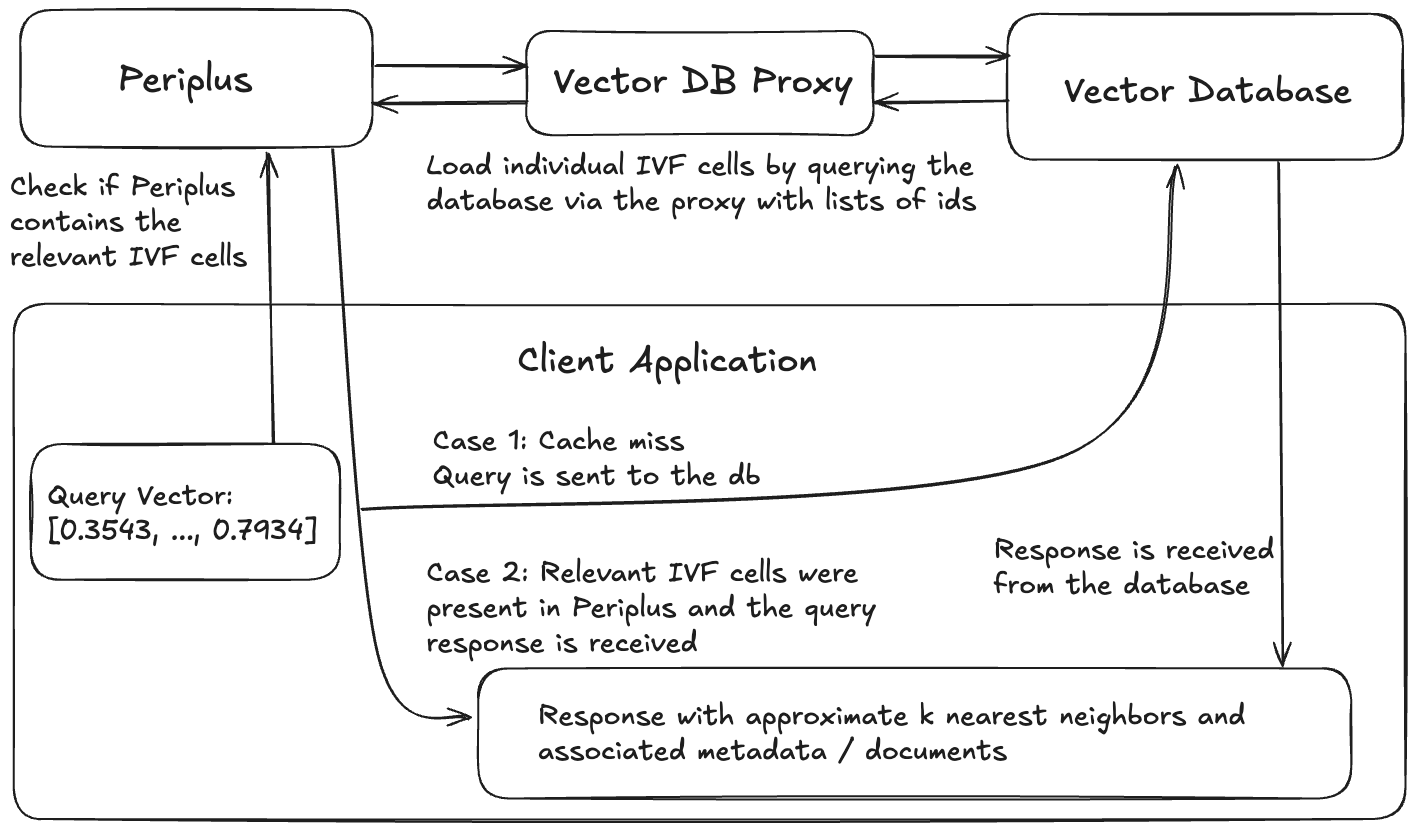
Exemple d'architecture d'une application utilisant Periplus.
Toute base de données vectorielle qui permet de rechercher des données par un identifiant unique (pratiquement toutes) fonctionnera. Periplus est conçu pour être le plus bénéfique lorsque vous travaillez avec de très grandes collections de vecteurs (milliards à l'échelle) où l'indice doit vivre sur le système de fichiers par opposition à RAM, bien que ce ne soit pas une exigence.
L'objectif de la base de données vectorielle est de fournir une interface cohérente pour que Periplus interagisse avec la base de données vectorielle. Le proxy doit implémenter une interface de repos qui accepte les demandes de poste du formulaire suivant:
URL: Ceci est flexible et peut être spécifié par le client Periplus.
En-têtes: "Content-Type": "application/json
Corps:
{
"ids" : [ " id-1 " , " id-2 " , " id-3 " ]
}Réponse:
{
"results" : [
{
"id" : " String " ,
"embedding" : [ 0.1 , 0.2 , 0.3 ],
"document" : " String " ,
"metdata" : " String "
}
]
}Pour faciliter la mise en œuvre de ce point de terminaison, vous pouvez utiliser le package Periplus-Proxy Python qui utilise Fastapi pour tout configurer. Tout ce que l'utilisateur a à faire est d'implémenter la fonction suivante et de la passer comme argument:
async def fetch_ids(request: Query) -> QueryResult
Pour plus de détails sur la façon de procéder, vous pouvez consulter le package Periplus-Proxy Readme.md.
Suivez les instructions ci-dessus pour démarrer une instance Periplus.
Pour interagir avec votre instance Periplus, utilisez la bibliothèque client Periplus. Actuellement, seul Python est pris en charge. Pour plus de détails sur la bibliothèque client, vous pouvez afficher sa lecture.md.
from periplus_client import Periplus
# host, port
client = Periplus ( "localhost" , 13 )
# vector dimensionality, database proxy url, options: (nTotal)
await client . initialize ( d = d , db_url = url , options = { "nTotal" : 50000 })
training_data = [[ 0.43456 , ..., 0.38759 ], ...]
await client . train ( training_data )
ids = [ "0" , ..., "n" ]
embeddings = [[ 0.43456 , ..., 0.38759 ], ...]
await client . add ( ids = ids , embeddings = embeddings )
load_options = { "n_load" : 2 }
# query_vector, optional: options object
await client . load ([ embeddings [ 0 ]] load_options )
# k, query_vector
response = await client . search ( 5 , [ embeddings [ 0 ]])
print ( response )
'''
[ // Results for each of the n query vectors in xq
[ // K nearest neighbors to this corresponding index in the xq list
(
id="n",
embedding=[0.43456, ..., 0.38759],
document="",
metadata="{}"
),
...
],
...
]
'''
# query_vector
await client . evict ( embeddings [ 0 ])Nous saluons les contributions à Periplus! Pour apprendre à commencer, jetez un œil au guide de contribution.
Ce projet est autorisé en vertu de la licence MIT - voir le fichier de licence pour plus de détails.


