Periplus
v0.1.0-alpha.1
Periplus saat ini berada di Alpha dan tidak siap-produksi. Proyek ini sedang dalam pengembangan aktif, dan belum direkomendasikan untuk digunakan dalam sistem produksi.
Periplus adalah cache basis data vektor in-memori open-source yang dibangun di atas pustaka pencarian kesamaan vektor meta FAISS. Proyek ini dapat dianggap sebagai "redis untuk database vektor". Ini dirancang untuk menyimpan subset yang diperbarui secara dinamis dari koleksi vektor besar sepenuhnya dalam memori sambil menyajikan kueri tanpa berinteraksi dengan node lain pada waktu kueri. Ketika Periplus menerima kueri, pertama-tama menilai apakah ia memiliki bagian yang relevan dari indeks di tempat tinggal. Jika ya, itu menyelesaikan kueri dengan respons yang sesuai. Jika tidak, ia mengembalikan cache miss dan meninggalkan querier untuk mengambil data dari database. Periplus tidak dirancang untuk berfungsi secara terpisah. Sebaliknya, ini dimaksudkan untuk membentuk lapisan caching modular dan fleksibel untuk database vektor terpisah yang membentuk lapisan persistensi. Tujuannya adalah untuk memungkinkan latensi yang lebih rendah dan penskalaan horizontal yang mudah untuk meningkatkan throughput. Untuk deskripsi yang lebih rinci tentang inspirasi di balik Periplus dan cara kerjanya, Anda dapat membaca blog pengumuman: Memperkenalkan Periplus: Pendekatan baru untuk caching basis data vektor.
Periplus menggunakan indeks file terbalik (IVF) sebagai dasar untuk manajemen cache. Indeks File Terbalik Partisi Ruang vektor ke dalam sel yang berdekatan yang ditentukan oleh satu set vektor centroid di mana setiap sel didefinisikan sebagai wilayah yang lebih dekat dengan centroid daripada centroid lainnya. Kueri kemudian diselesaikan dengan terlebih dahulu menghitung jarak dari vektor kueri ke set centroid dan kemudian mencari hanya sel yang ditentukan oleh centroid n_probe (pencarian hiperparameter) terdekat. Periplus mengambil keuntungan dari ini dengan menyimpan subset dari sel -sel ini di tempat tinggal pada waktu tertentu dan hanya menyelesaikan kueri yang relevan dengan subset itu sambil menolak yang tidak seperti cache tidak hilang. Periplus memuat dan mengusir seluruh sel IVF pada satu waktu untuk mempertahankan integritas indeks dan memastikan penarikan yang setara (pada hit cache) ke indeks IVF standar. Sel IVF dimuat dengan menanyakan database vektor melalui proksi dengan daftar ID vektor yang dipertahankan Periplus untuk melacak vektor mana yang menempati sel -sel mana. Operasi ini dapat dipanggil oleh pengguna menggunakan perintah Load , Search , dan Excict . Untuk detailnya, lihat bagian Perintah Periplus di bawah ini.
Periplus dapat dijalankan sebagai wadah Docker atau dapat dibangun dari sumber dan dijalankan sebagai yang dapat dieksekusi. Tidak ada binari resmi saat ini tersedia. Menjalankan Periplus sebagai wadah adalah pendekatan yang direkomendasikan, tetapi keduanya adalah opsi yang layak.
Saat ini, gambar Docker hanya mendukung arsitektur AMD64. Kendala ini berasal dari gambar dasar, tetapi lebih banyak arsitektur akan didukung dalam waktu dekat. Ada 2 cara untuk menjalankan Periplus sebagai wadah: Unduh gambar Docker resmi dari Dockerhub (disarankan) atau bangun sendiri. Langkah pertama dalam kedua kasus adalah menginstal Docker jika Anda belum melakukannya. Instruksi untuk melakukannya dapat ditemukan di sini.
docker image pull qdl123/periplus:latest .docker run -p 3000:3000 qdl123/periplus:latest git clone https://github.com/QDL123/Periplus.gitcd <path-to-periplus-repo>/Periplusdocker build -t periplus-image .docker run -p 3000:3000 periplus-image .Periplus menggunakan cmake untuk sistem pembuatannya. Ini mengharapkan semua dependensi untuk menginstal binari yang telah dikompilasi sebelumnya melalui homebrew. Homebrew didukung oleh MacOS, Ubuntu, dan WSL jika Anda menggunakan Windows. Periplus telah dibangun di MacOS/ARM64 dan Ubuntu/AMD64. Semua kombinasi sistem operasi dan arsitektur lainnya belum teruji. Untuk membangun periplus dari sumber, ikuti langkah -langkah berikut:
brew install faiss curl cpr rapidjson libomp catch2 cmakegit clone https://github.com/QDL123/Periplus.gitcd <path-to-periplus-repo>/Peripluscmake -S . -B buildcmake --build build./build/periplus -p 3000 Sistem apa pun yang menggunakan Periplus akan terdiri dari 4 komponen: database vektor, proxy database yang memungkinkan Periplus memuat data dari database, instance Periplus, dan aplikasi klien.
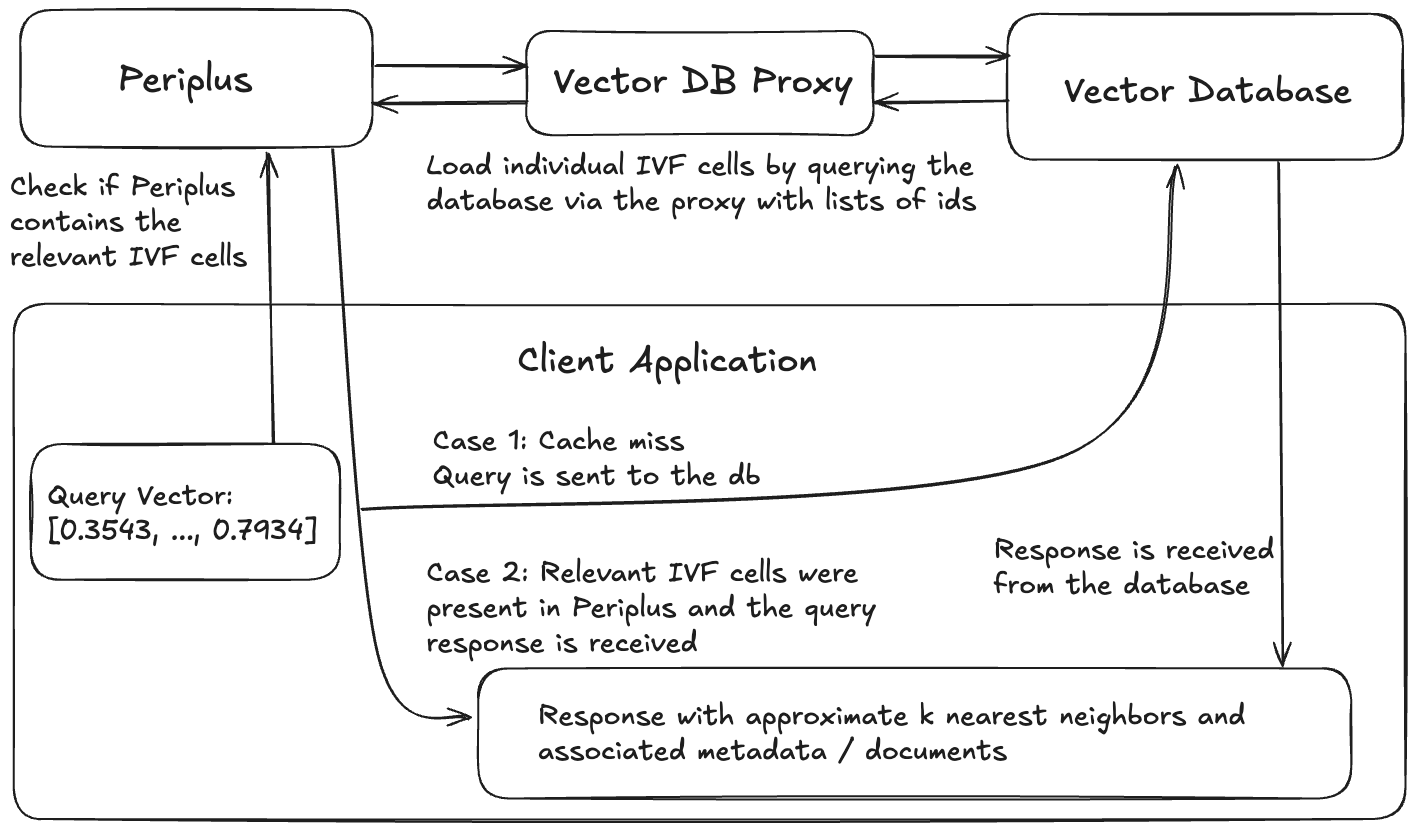
Contoh arsitektur aplikasi menggunakan Periplus.
Setiap basis data vektor yang memungkinkan untuk mencari data oleh pengidentifikasi unik (hampir semuanya) akan berfungsi. Periplus dirancang untuk menjadi yang paling bermanfaat ketika bekerja dengan kolekton vektor yang sangat besar (skala miliar) di mana indeks harus hidup di sistem file sebagai lawan RAM, meskipun itu bukan persyaratan.
Tujuan proxy vektor basis data adalah untuk menyediakan antarmuka yang konsisten untuk periplus untuk berinteraksi dengan database vektor melalui. Proxy harus mengimplementasikan antarmuka REST yang menerima permintaan pasca dari formulir berikut:
URL: Ini fleksibel dan dapat ditentukan oleh klien Periplus.
Header: "Content-Type": "application/json
Tubuh:
{
"ids" : [ " id-1 " , " id-2 " , " id-3 " ]
}Tanggapan:
{
"results" : [
{
"id" : " String " ,
"embedding" : [ 0.1 , 0.2 , 0.3 ],
"document" : " String " ,
"metdata" : " String "
}
]
}Untuk membuat implementasi titik akhir ini lebih mudah, Anda dapat menggunakan paket Python periplus-proxy yang menggunakan FASTAPI untuk mengatur semuanya. Yang harus dilakukan pengguna hanyalah mengimplementasikan fungsi berikut dan meneruskannya sebagai argumen:
async def fetch_ids(request: Query) -> QueryResult
Untuk detail tentang cara melakukan ini, Anda dapat memeriksa paket periplus-proxy ReadMe.md.
Ikuti instruksi di atas untuk memulai instance Periplus.
Untuk berinteraksi dengan instance Periplus Anda, gunakan Perpustakaan Klien Periplus. Saat ini hanya Python yang didukung. Untuk detail di Perpustakaan Klien, Anda dapat melihatnya ReadMe.md.
from periplus_client import Periplus
# host, port
client = Periplus ( "localhost" , 13 )
# vector dimensionality, database proxy url, options: (nTotal)
await client . initialize ( d = d , db_url = url , options = { "nTotal" : 50000 })
training_data = [[ 0.43456 , ..., 0.38759 ], ...]
await client . train ( training_data )
ids = [ "0" , ..., "n" ]
embeddings = [[ 0.43456 , ..., 0.38759 ], ...]
await client . add ( ids = ids , embeddings = embeddings )
load_options = { "n_load" : 2 }
# query_vector, optional: options object
await client . load ([ embeddings [ 0 ]] load_options )
# k, query_vector
response = await client . search ( 5 , [ embeddings [ 0 ]])
print ( response )
'''
[ // Results for each of the n query vectors in xq
[ // K nearest neighbors to this corresponding index in the xq list
(
id="n",
embedding=[0.43456, ..., 0.38759],
document="",
metadata="{}"
),
...
],
...
]
'''
# query_vector
await client . evict ( embeddings [ 0 ])Kami menyambut kontribusi untuk Periplus! Untuk mempelajari cara memulai, lihat panduan kontribusi.
Proyek ini dilisensikan di bawah lisensi MIT - lihat file lisensi untuk detailnya.


