Whisper WebUI
1.0.0
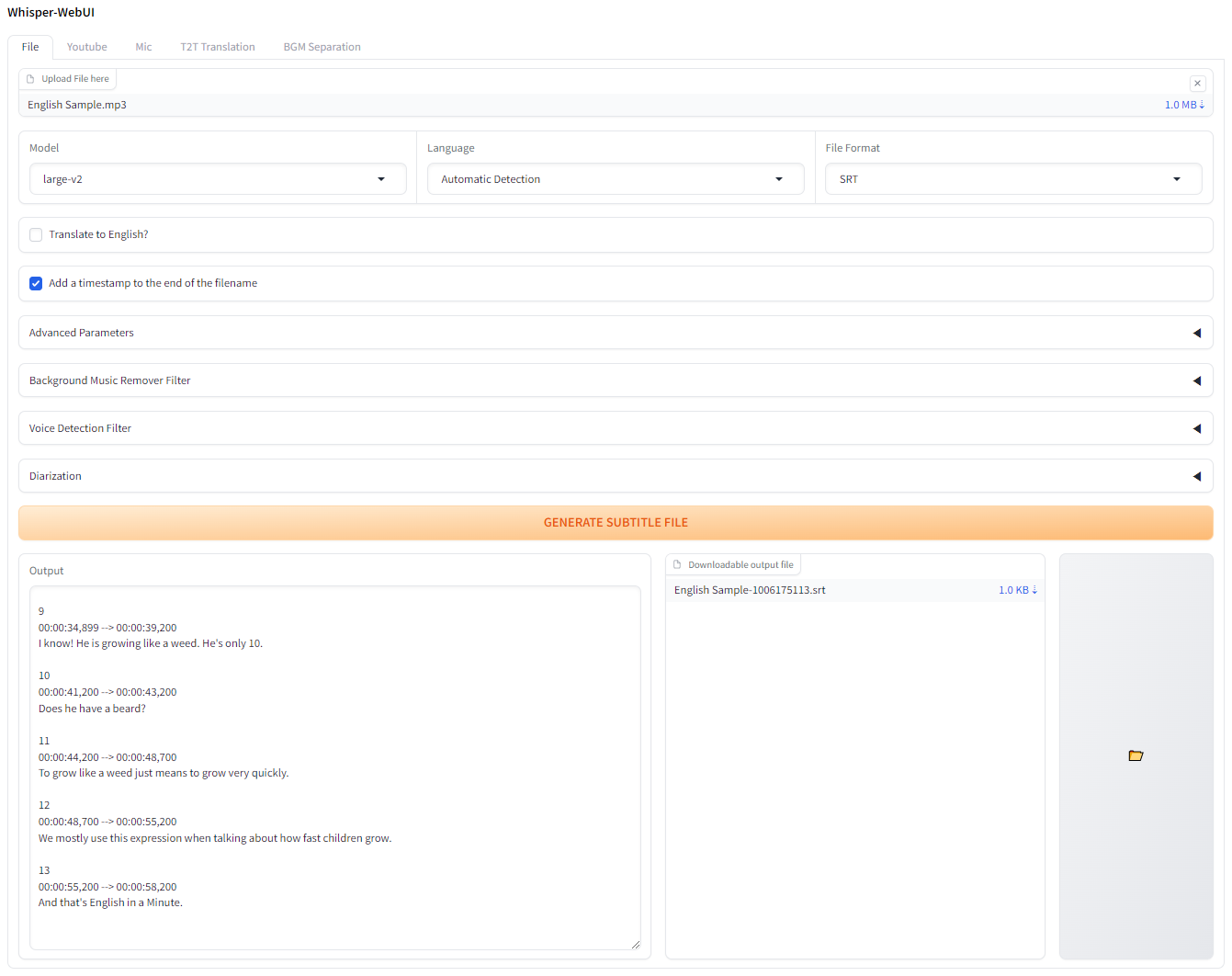
Whisper를위한 Gradio 기반 브라우저 인터페이스. 쉬운 자막 발전기로 사용할 수 있습니다!
Colab에서 이것을 시도하고 싶다면 여기에서 할 수 있습니다!
이 앱은 Pinokio와 함께 실행할 수 있습니다.
http://localhost:7860 에 연결하십시오. Docker-Desktop을 설치하고 시작하십시오.
git 복제 저장소를 복제합니다
git clone https://github.com/jhj0517/Whisper-WebUI.gitdocker compose build docker compose uphttp://localhost:7860 사용하여 Webui에 연결하십시오 필요한 경우 docker-compose.yaml 업데이트하여 환경과 일치하십시오.
이 webui를 실행하려면 git , 3.10 <= python <= 3.12 , FFmpeg 있어야합니다.
NVIDA GPU를 사용하지 않거나 12.4 이상의 다른 CUDA 버전을 사용하는 경우 requirements.txt 편집하여 환경과 일치합니다.
필요한 소프트웨어를 설치하려면 아래 링크를 따르십시오.
3.10 ~ 3.12 권장됩니다. FFMPEG를 설치 한 후 FFmpeg/bin 폴더를 시스템 경로에 추가하십시오!
git clone https://github.com/jhj0517/Whisper-WebUI.gitinstall.bat 또는 install.sh 실행합니다. ( venv 디렉토리를 만들고 종속성을 설치합니다.)start-webui.bat 또는 start-webui.sh 로 webui를 시작하십시오 (Venv를 활성화 한 후 python app.py 실행합니다)또한 원하는 경우 명령 줄 인수로 프로젝트를 실행할 수 있습니다. Wiki를 참조하십시오.
이 프로젝트는 더 나은 VRAM 사용 및 전사 속도를 위해 기본적으로 더 빠른 whisper와 통합됩니다.
Faster-Whisper에 따르면, 최적화 된 Whisper 모델의 효율성은 다음과 같습니다.
| 구현 | 정도 | 빔 크기 | 시간 | 맥스. GPU 메모리 | 맥스. CPU 메모리 |
|---|---|---|---|---|---|
| Openai/Whisper | FP16 | 5 | 4M30S | 11325MB | 9439MB |
| 더 빠른-whisper | FP16 | 5 | 54S | 4755MB | 3244MB |
더 빠른 위스퍼 이외의 구현을 사용하려면 --whisper_type arg 및 리포지토리 이름을 사용하십시오.
Cli Args에 대한 자세한 내용은 Wiki를 읽으십시오.
이것은 모델 용 Whisper의 원래 VRAM 사용 테이블입니다.
| 크기 | 매개 변수 | 영어 전용 모델 | 다국어 모델 | 필수 VRAM | 상대 속도 |
|---|---|---|---|---|---|
| 매우 작은 | 39m | tiny.en | tiny | ~ 1GB | ~ 32x |
| 베이스 | 74m | base.en | base | ~ 1GB | ~ 16x |
| 작은 | 244m | small.en | small | ~ 2GB | ~ 6x |
| 중간 | 769m | medium.en | medium | ~ 5GB | ~ 2x |
| 크기가 큰 | 1550m | N/A | large | ~ 10GB | 1x |
.en 모델은 영어 전용이며 멋진 것은 "큰"모델에서 Translate to English 옵션을 사용할 수 있다는 것입니다!
언어를 번역으로 변환하는 모든 PR. YAML은 대단히 감사하겠습니다!


