Whisper WebUI
1.0.0
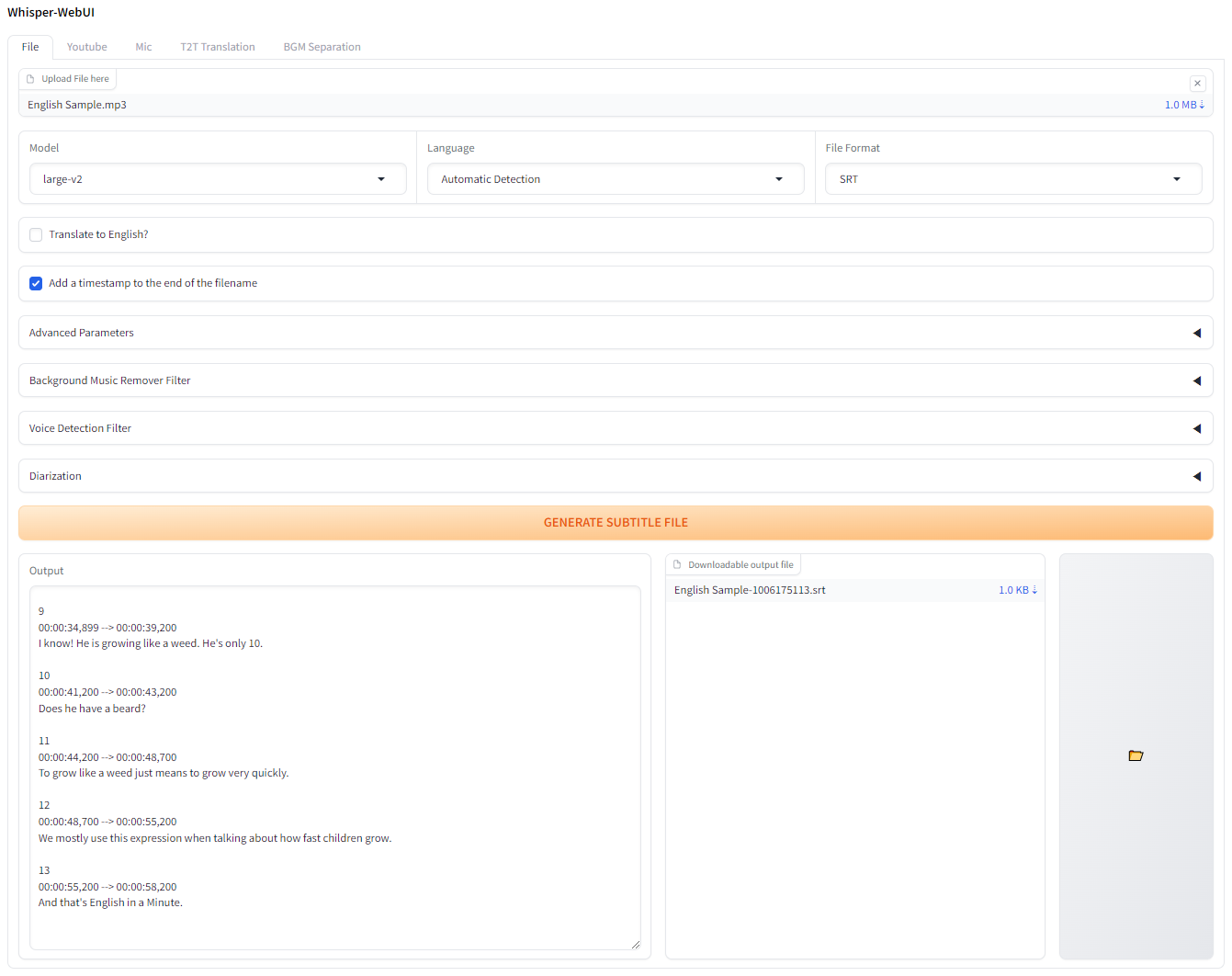
ささやき用のグラデーションベースのブラウザインターフェイス。簡単な字幕ジェネレーターとして使用できます!
Colabでこれを試してみたい場合は、ここでそれをすることができます!
アプリはPinokioで実行できます。
http://localhost:7860に接続します。 Docker-desktopをインストールして起動します。
gitリポジトリをクローンします
git clone https://github.com/jhj0517/Whisper-WebUI.gitdocker compose build docker compose uphttp://localhost:7860でブラウザでWebUIに接続します必要に応じて、 docker-compose.yamlを更新して、環境に一致します。
このWebUIを実行するには、 git 、 3.10 <= python <= 3.12 、 FFmpegが必要です。
また、NVIDA GPUを使用していない場合、または12.4とは異なるCUDAバージョンを使用していない場合は、環境と一致するようにrequirements.txtを編集してください。
必要なソフトウェアをインストールするには、以下のリンクに従ってください。
3.10 ~ 3.12お勧めします。 FFMPEGをインストールしたら、 FFmpeg/binフォルダーをシステムパスに追加してください!
git clone https://github.com/jhj0517/Whisper-WebUI.gitinstall.batまたはinstall.shを実行して、依存関係をインストールします。 ( venvディレクトリを作成し、そこに依存関係をインストールします。)start-webui.batまたはstart-webui.shでWebUIを開始します(venvをアクティブにした後、 python app.pyを実行します)また、コマンドラインの引数でプロジェクトを実行することもできます。
このプロジェクトは、VRAMの使用速度と転写速度を向上させるために、デフォルトでより速いウィスパーと統合されています。
より速いウィスパーによると、最適化されたささやきモデルの効率は次のとおりです。
| 実装 | 精度 | ビームサイズ | 時間 | マックス。 GPUメモリ | マックス。 CPUメモリ |
|---|---|---|---|---|---|
| Openai/Whisper | FP16 | 5 | 4m30s | 11325MB | 9439MB |
| より速いウィスパー | FP16 | 5 | 54s | 4755MB | 3244MB |
より速いウィスパー以外の実装を使用する場合は、 --whisper_type argとリポジトリ名を使用します。
CLI Argsの詳細については、Wikiをお読みください。
これは、モデル用のWhisperのオリジナルVRAM使用テーブルです。
| サイズ | パラメーター | 英語のみのモデル | 多言語モデル | 必要なvram | 相対速度 |
|---|---|---|---|---|---|
| 小さい | 39 m | tiny.en | tiny | 〜1 gb | 〜32x |
| ベース | 74 m | base.en | base | 〜1 gb | 〜16x |
| 小さい | 244 m | small.en | small | 〜2 gb | 〜6x |
| 中くらい | 769 m | medium.en | medium | 〜5 gb | 〜2x |
| 大きい | 1550 m | n/a | large | 〜10 gb | 1x |
.enモデルは英語のみであり、クールなことは、「大規模」モデルのTranslate to Englishオプションを使用できることです!
言語を翻訳に翻訳するPRS.yamlは大歓迎です!


