HPT
1.0.0
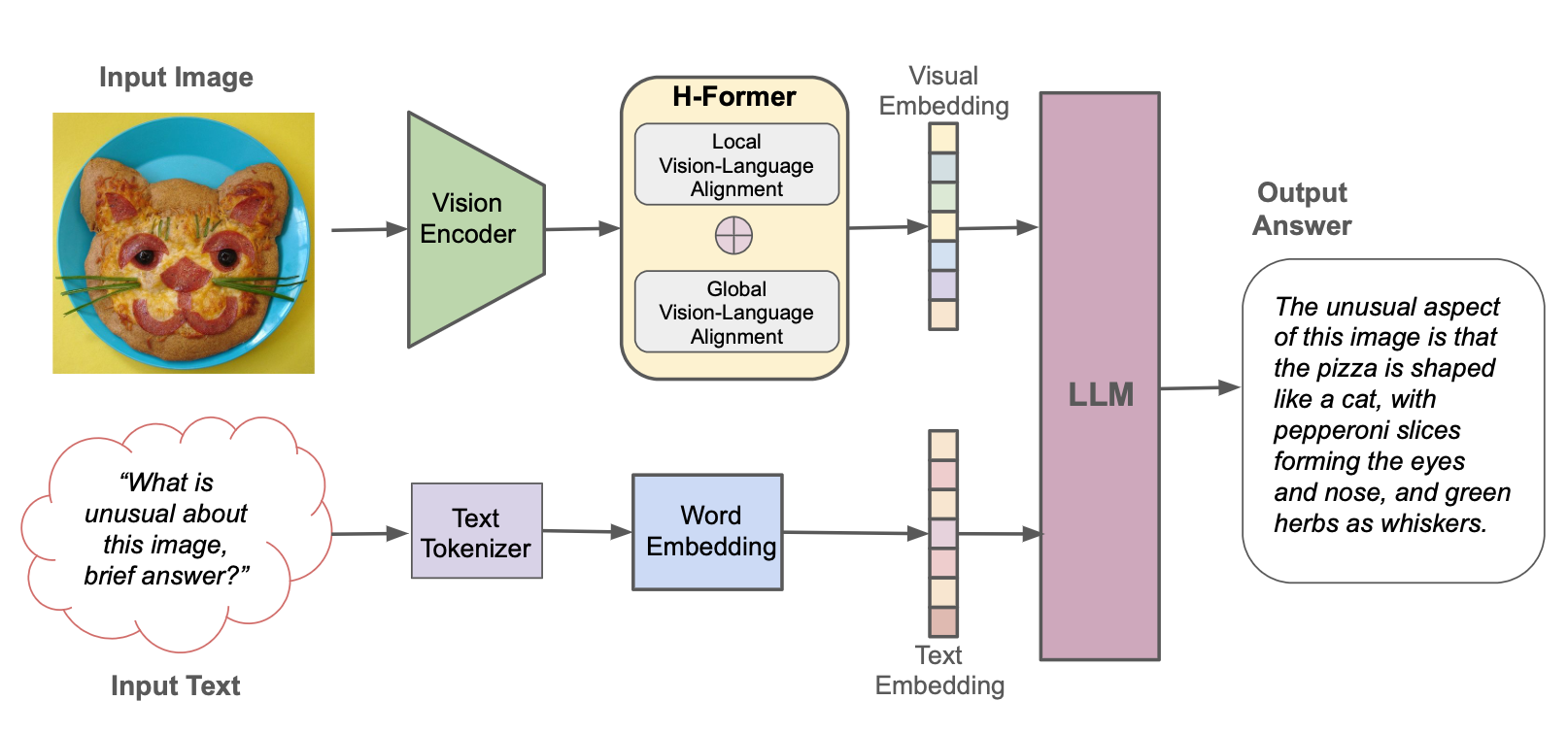
Hyper-Prestrained Transformers(HPT)は、Hypergaiの新しいマルチモーダルLLMフレームワークであり、テキストと視覚の両方の入力を理解できる視覚言語モデル向けに訓練されています。 HPTは、さまざまなマルチモーダルLLMベンチマークで最先端のモデルで非常に競争力のある結果を達成しています。このリポジトリには、異なるベンチマークでHPTの評価結果を再現するための推論コードのオープンソースの実装が含まれています。
Edgeデバイスに合わせた最新のオープンソースモデルとして、HPT 1.5 Edgeをリリースします。そのサイズ(<5b)にもかかわらず、Edgeは非常に効率的である一方で印象的な能力を示しています。 Apache 2.0ライセンスの下で、HuggingfaceとGithubでHPT 1.5 Edgeを公開します。
pip install -r requirements.txt
pip install -e .
HFからモデルの重みを[ローカルパス]にダウンロードし、モデル構成ファイルの[ローカルパス]としてglobal_model_pathを設定できます。
git lfs install
git clone https://huggingface.co/HyperGAI/HPT1_5-Edge [Local Path]
デフォルト設定とは異なる構成ファイルに、他の戦略を設定することもできます。
構成ファイルを設定した後、クイックトライアルのためにモデルデモを起動します。
python demo/demo.py --image_path [Image] --text [Text] --model [Config]
例:
python demo/demo.py --image_path demo/einstein.jpg --text 'What is unusual about this image?' --model hpt-edge-1-5
評価のためにモデルを起動します:
torchrun --nproc-per-node=8 run.py --data [Dataset] --model [Config]
HPT 1.5エッジの例:
torchrun --nproc-per-node=8 run.py --data MMMU_DEV_VAL --model hpt-edge-1-5
HPT 1.5エッジの場合
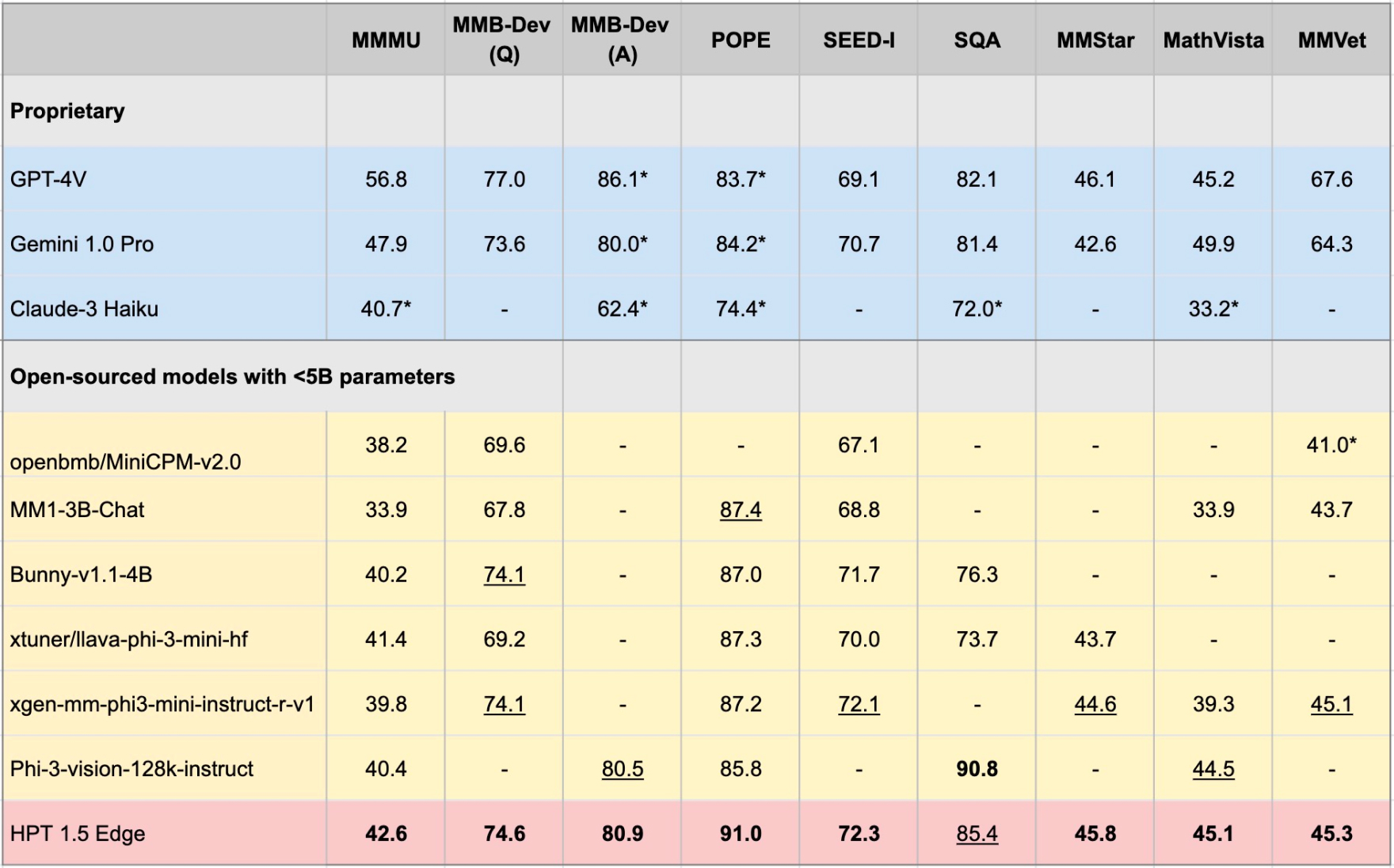
HPT 1.5エッジ
前処理されたLLM:PHI-3-MINI-4K-Instruct
前処理された視覚エンコーダー:Siglip-So400M-Patch14-384
HPT 1.5 Air
前処理されたLLM:llama3-8b-instruct
前処理された視覚エンコーダー:Siglip-So400M-Patch14-384
HPT 1.0エア
前処理されたLLM:YI-6B-chat
前処理された視覚エンコーダー:Clip-vit-large-patch14-336
HPT Airは、オープンで責任あるAIの研究とコミュニティ開発を促進するためのモデルのクイックオープンリリースであることに注意してください。節度のメカニズムはなく、結果に保証を提供しません。私たちは、モデルがガードレールを細かく尊重し、モデル化された出力を必要とする現実世界のアプリケーションでの実際の採用を可能にするために、コミュニティと関わりたいと考えています。
このプロジェクトは、Apache 2.0ライセンスの下でリリースされます。このプロジェクトの一部には、それぞれのライセンスの対象となる他のソースのコードとモデルが含まれており、商業目的で使用する場合は、それぞれのライセンスを適用する必要があります。
このデモを実行するための評価コードは、VLMevalkitプロジェクトに基づいて拡張されました。また、視覚エンコーダモデル01.AI、Meta、Microsoftのオープンソースをオープンソーシングして、大規模な言語モデルをオープンソーシングしてくれたOpenaiに感謝します。


