One Click VITS Training
1.0.0
Alat ini memungkinkan Anda untuk menyelesaikan seluruh proses VIT (preprocessing data + Whisper ASR + teks preprocessing + modifikasi config.json + pelatihan, inferensi) dengan satu klik!
16GB .12GB VRAM.Pytorch Install Command:
pip install torch==1.13.1+cu117 torchvision==0.14.1+cu117 torchaudio==0.13.1 --extra-index-url https://download.pytorch.org/whl/cu117 CUDA 11.7 Instal: https://developer.nvidia.com/cuda-11-7-0-download-archive
Zlib dll instal: https://docs.nvidia.com/deeplearning/cudnn/install-guide/index.html#install-zlib-windows
Instal Pyopenjtalk secara manual: pip install -U pyopenjtalk --no-build-isolation
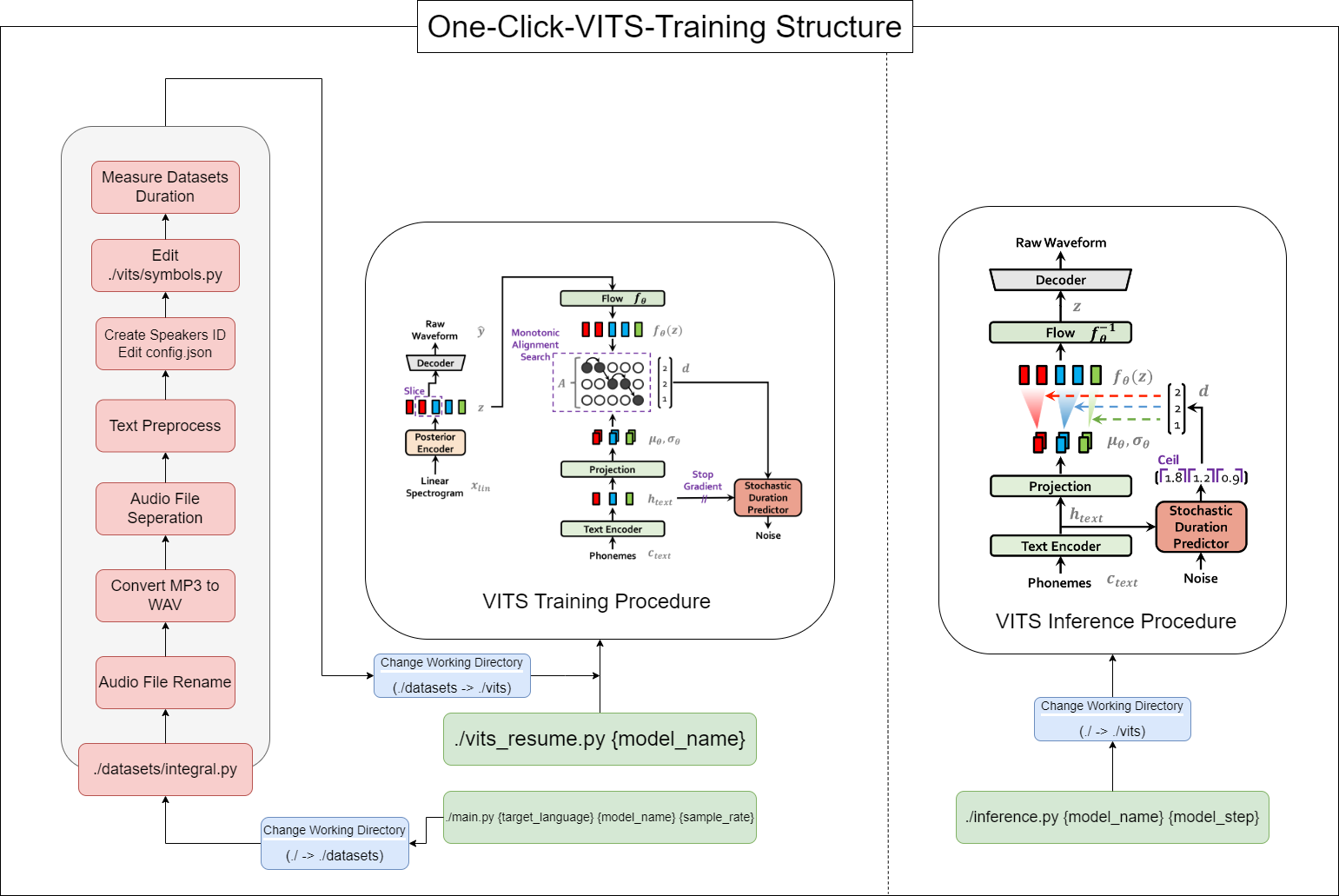
conda create -n one-click-vits python=3.8conda activate one-click-vitsgit clone https://github.com/ORI-Muchim/One-Click-VITS-Training.git cd One-Click-VITS-Trainingpip install -r requirements.txtTempatkan file audio sebagai berikut.
file .mp3 atau .wav baik -baik saja.
One-Click-VITS-Training
├────datasets
│ ├───speaker0
│ │ ├────1.mp3
│ │ └────1.wav
│ └───speaker1
│ │ ├───1.mp3
│ │ └───1.wav
│ ├integral.py
│ └integral_low.py
│
├────vits
├────inference.py
├────main_low.py
├────main_resume.py
├────main.py
├────Readme.md
└────requirements.txt
Ini hanya sebuah contoh, dan tidak apa -apa untuk menambahkan lebih banyak speaker.
Untuk memulai alat ini, gunakan perintah berikut, ganti {bahasa}, {model_name}, dan {sample_rate} dengan nilai masing -masing ({bahasa: ko, ja, en, zh} / {sample_rate: 22050 /44100}):
python main.py {language} {model_name} {sample_rate}Bagi mereka yang memiliki spesifikasi rendah (VRAM <12GB), silakan gunakan kode ini:
python main_low.py {language} {model_name} {sample_rate}Jika konfigurasi data selesai dan Anda ingin melanjutkan pelatihan, masukkan kode ini:
python main_resume.py {model_name}Setelah model dilatih, Anda dapat menghasilkan prediksi dengan menggunakan perintah berikut, mengganti {model_name} dan {model_step} dengan nilai masing -masing:
python inference.py {model_name} {model_step}Atau periksa ./vits/inference.ipynb.
Jika Anda ingin mengubah contoh teks yang digunakan dalam referensi, ubah ./vits/inferencems.py bagian text .
Dalam repositori cjangcjengh/vits, saya membuat beberapa modifikasi pada metode pembersihan teks Korea. Proses pembersihan lainnya adalah sama dengan mempostingnya ke repositori Cjangcjengh, tetapi file yang lebih bersih dimodifikasi menggunakan pustaka Tenebo/G2PK2 seperti yang diucapkan Korea.
Untuk informasi lebih lanjut, silakan merujuk ke repositori berikut:


