inference
v1.1.1

Xinference Cloud · Xinference Enterprise · Hosting · Documentation
L'inférence Xorbits (Xinference) est une bibliothèque puissante et polyvalente conçue pour servir le langage, la reconnaissance vocale et les modèles multimodaux. Avec l'inférence Xorbits, vous pouvez déployer et servir sans effort vos modèles intégrés ou de pointe en utilisant une seule commande. Que vous soyez chercheur, développeur ou scientifique des données, l'inférence Xorbits vous permet de libérer le plein potentiel des modèles d'IA de pointe.
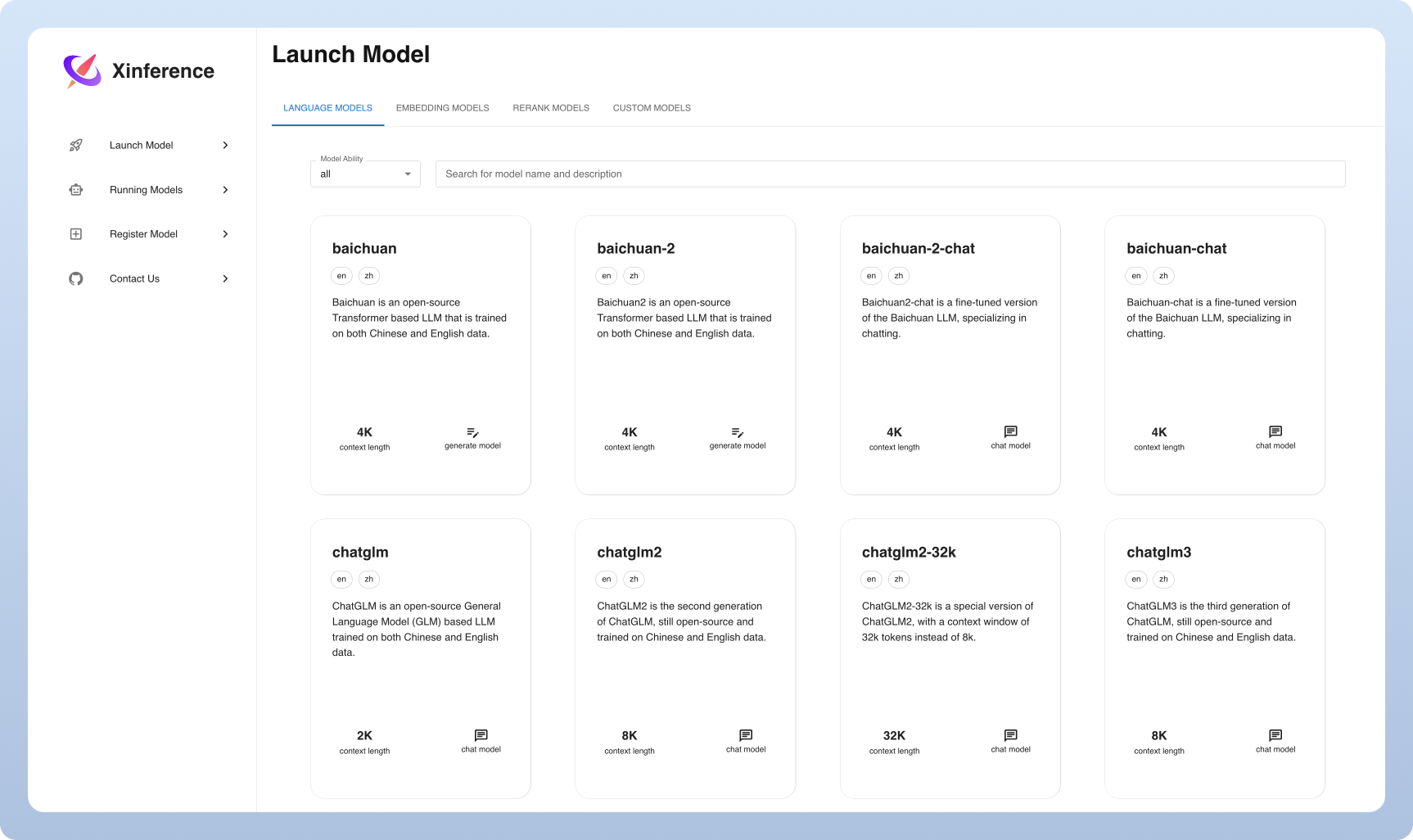
? Le service de modèle est facilité : simplifiez le processus de service de grande langue, de reconnaissance vocale et de modèles multimodaux. Vous pouvez configurer et déployer vos modèles d'expérimentation et de production avec une seule commande.
⚡️ Modèles de pointe : Expérimentez avec des modèles intégrés de pointe en utilisant une seule commande. L'inférence donne accès aux modèles open-source de pointe!
? Utilisation du matériel hétérogène : profitez de vos ressources matérielles avec GGML. Xorbits Inférence utilise intelligemment le matériel hétérogène, y compris les GPU et les CPU, pour accélérer les tâches d'inférence de votre modèle.
API et interfaces flexibles : offrez plusieurs interfaces pour interagir avec vos modèles, en prenant en charge l'API RESTful compatible OpenAI (y compris une API d'appel de fonction), RPC, CLI et WebUI pour la gestion et l'interaction des modèles transparents.
Déploiement distribué : Excel dans les scénarios de déploiement distribués, permettant la distribution transparente de l'inférence du modèle sur plusieurs appareils ou machines.
? Intégration intégrée avec des bibliothèques tierces : Xorbits Inference s'intègre parfaitement aux bibliothèques tierces populaires, notamment Langchain, Llamaindex, Dify et Chatbox.
| Fonctionnalité | Xinference | Fastchat | OpenLlm | Rayllm |
|---|---|---|---|---|
| API RESTFul compatible Openai | ✅ | ✅ | ✅ | ✅ |
| intégrations vllm | ✅ | ✅ | ✅ | ✅ |
| Plus de moteurs d'inférence (GGML, Tensorrt) | ✅ | ✅ | ✅ | |
| Plus de plates-formes (CPU, métal) | ✅ | ✅ | ||
| Déploiement de grappes multi-nœuds | ✅ | ✅ | ||
| Modèles d'image (texte à l'image) | ✅ | ✅ | ||
| Modèles d'intégration de texte | ✅ | |||
| Modèles multimodaux | ✅ | |||
| Modèles audio | ✅ | |||
| Plus de fonctionnalités ouvertes (appel de fonction) | ✅ |
Nuage
Nous hébergeons un service cloud Xinference pour que quiconque puisse essayer avec une configuration zéro.
Édition communautaire d'auto-hébergement Xinference
Obtenez rapidement la xinference dans votre environnement avec ce guide de démarrage. Utilisez notre documentation pour d'autres références et des instructions plus approfondies.
Xinférence pour l'entreprise / les organisations
Nous fournissons des fonctionnalités supplémentaires centrées sur l'entreprise. Envoyez-nous un e-mail pour discuter des besoins en entreprise.
Star Xinference sur Github et être instantanément informé des nouvelles versions.
La façon la plus légère de découvrir la xinference est d'essayer notre cahier Jupyter sur Google Colab.
Les utilisateurs de NVIDIA GPU peuvent démarrer Xinference Server à l'aide de Xinference Docker Image. Avant d'exécuter la commande d'installation, assurez-vous que Docker et Cuda sont configurés sur votre système.
docker run --name xinference -d -p 9997:9997 -e XINFERENCE_HOME=/data -v < /on/your/host > :/data --gpus all xprobe/xinference:latest xinference-local -H 0.0.0.0Assurez-vous que vous avez une prise en charge GPU dans votre cluster Kubernetes, puis installez comme suit.
# add repo
helm repo add xinference https://xorbitsai.github.io/xinference-helm-charts
# update indexes and query xinference versions
helm repo update xinference
helm search repo xinference/xinference --devel --versions
# install xinference
helm install xinference xinference/xinference -n xinference --version 0.0.1-v<xinference_release_version>
Pour des méthodes d'installation plus personnalisées sur K8S, veuillez vous référer à la documentation.
Installez Xinference en utilisant PIP comme suit. (Pour plus d'options, voir la page d'installation.)
pip install " xinference[all] "Pour démarrer une instance locale de Xinference, exécutez la commande suivante:
$ xinference-localUne fois la xinference en cours d'exécution, il existe plusieurs façons de l'essayer: via l'interface utilisateur Web, via Curl, via la ligne de commande ou via le client Python de Xinference. Consultez nos documents pour le guide.
| Plate-forme | But |
|---|---|
| Problèmes de github | Reportation de bogues et de demandes de fonctionnalités de dépôt. |
| Mou | Collaborant avec d'autres utilisateurs de Xorbits. |
| Gazouillement | Rester à jour sur de nouvelles fonctionnalités. |
Si ce travail est utile, veuillez citer comme:
@inproceedings { lu2024xinference ,
title = " Xinference: Making Large Model Serving Easy " ,
author = " Lu, Weizheng and Xiong, Lingfeng and Zhang, Feng and Qin, Xuye and Chen, Yueguo " ,
booktitle = " Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing: System Demonstrations " ,
month = nov,
year = " 2024 " ,
address = " Miami, Florida, USA " ,
publisher = " Association for Computational Linguistics " ,
url = " https://aclanthology.org/2024.emnlp-demo.30 " ,
pages = " 291--300 " ,
}

