inference
v1.1.1

Xinferenz-Cloud · Xinferenzunternehmen · Selbsthostierung · Dokumentation
Xorbits Inference (Xinferenz) ist eine leistungsstarke und vielseitige Bibliothek, mit der Sprach-, Spracherkennung und multimodale Modelle dienen. Mit Xorbits Inference können Sie mühelos Ihre oder modernsten integrierten Modelle mit nur einem einzigen Befehl einsetzen und bedienen. Egal, ob Sie Forscher, Entwickler oder Datenwissenschaftler sind, Xorbits Inferenz befähigt Sie, das volle Potenzial von hochmodernen KI-Modellen auszulösen.
? Einfaches Modell . Sie können Ihre Modelle für Experimente und Produktion mit einem einzigen Befehl einrichten und bereitstellen.
⚡️ hochmoderne Modelle : Experimentieren Sie mit modernsten integrierten Modellen mit einem einzigen Befehl. Inferenz bietet Zugang zu hochmodernen Open-Source-Modellen!
? Heterogene Hardware -Auslastung : Machen Sie mit GGML das Beste Ihrer Hardware -Ressourcen. Xorbits Inferenz verwendet intelligent heterogene Hardware, einschließlich GPUs und CPUs, um Ihre Modellinferenzaufgaben zu beschleunigen.
Flexible API und Schnittstellen : Bieten Sie mehrere Schnittstellen für die Interaktion mit Ihren Modellen an und unterstützen Sie die openAI -kompatible Rastful -API (einschließlich Funktionsaufruf -API), RPC, CLI und Webui für die nahtlose Modellverwaltung und -interaktion.
Verteilte Bereitstellung : Excel in verteilten Bereitstellungsszenarien, die die nahtlose Verteilung der Modellinferenz über mehrere Geräte oder Maschinen hinweg ermöglicht.
? Integrierte Integration in Bibliotheken von Drittanbietern : Xorbits Inference integriert sich nahtlos in beliebte Bibliotheken von Drittanbietern, darunter Langchain, Llamaindex, Dify und Chatbox.
| Besonderheit | Xinferenz | Fastchat | Openllm | Rayllm |
|---|---|---|---|---|
| OpenAI-kompatible erholsame API | ✅ | ✅ | ✅ | ✅ |
| VLLM -Integrationen | ✅ | ✅ | ✅ | ✅ |
| Mehr Inferenzmotoren (GGML, Tensorrt) | ✅ | ✅ | ✅ | |
| Weitere Plattformen (CPU, Metall) | ✅ | ✅ | ||
| Multi-Knoten-Cluster-Bereitstellung | ✅ | ✅ | ||
| Bildmodelle (Text-zu-Image) | ✅ | ✅ | ||
| Texteinbettungsmodelle | ✅ | |||
| Multimodale Modelle | ✅ | |||
| Audiomodelle | ✅ | |||
| Weitere OpenAI -Funktionen (Funktionsaufruf) | ✅ |
Wolke
Wir hosten einen Xinferenz -Cloud -Dienst, den jeder mit Null -Setup ausprobieren kann.
Self-Hosting Xinferenz Community Edition
Erhalten Sie mit diesem Starterführer schnell Xinferenz in Ihrer Umgebung. Verwenden Sie unsere Dokumentation für weitere Referenzen und eingehende Anweisungen.
Xinferenz für Unternehmen / Organisationen
Wir bieten zusätzliche unternehmenszentrierte Funktionen. Senden Sie uns eine E -Mail, um Unternehmensanforderungen zu besprechen.
Stern Xinference auf GitHub und werden sofort über neue Veröffentlichungen informiert.
Der leichteste Weg, um Xinference zu erleben, besteht darin, unser Jupyter -Notebook in Google Colab auszuprobieren.
NVIDIA -GPU -Benutzer können den Xinferenzserver mithilfe des Xinferenz -Docker -Images starten. Stellen Sie vor der Ausführung des Installationsbefehls sicher, dass sowohl Docker als auch CUDA in Ihrem System eingerichtet werden.
docker run --name xinference -d -p 9997:9997 -e XINFERENCE_HOME=/data -v < /on/your/host > :/data --gpus all xprobe/xinference:latest xinference-local -H 0.0.0.0Stellen Sie sicher, dass Sie in Ihrem Kubernetes -Cluster eine GPU -Unterstützung haben und dann wie folgt installieren.
# add repo
helm repo add xinference https://xorbitsai.github.io/xinference-helm-charts
# update indexes and query xinference versions
helm repo update xinference
helm search repo xinference/xinference --devel --versions
# install xinference
helm install xinference xinference/xinference -n xinference --version 0.0.1-v<xinference_release_version>
Weitere maßgeschneiderte Installationsmethoden auf K8s finden Sie in der Dokumentation.
Installieren Sie die Xinferenz mit PIP wie folgt. (Weitere Optionen finden Sie in der Installationsseite.)
pip install " xinference[all] "Führen Sie den folgenden Befehl aus, um eine lokale Instanz von Xinference zu starten:
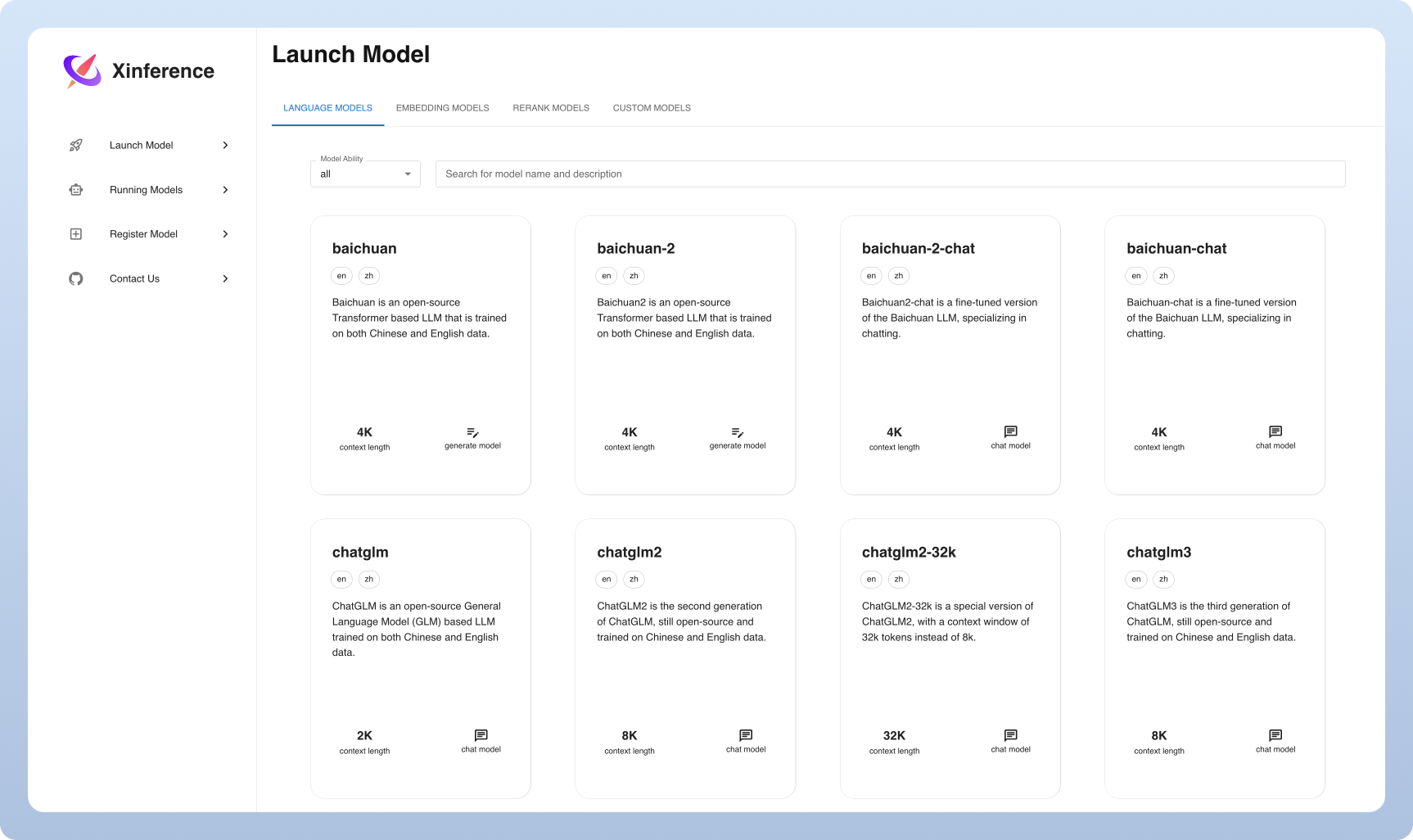
$ xinference-localSobald Xinference ausgeführt wird, können Sie es mit mehreren Möglichkeiten versuchen: über die Web -Benutzeroberfläche, über Curl, über die Befehlszeile oder über den Python -Client der Xinferenz. Schauen Sie sich unsere Dokumente für den Leitfaden an.
| Plattform | Zweck |
|---|---|
| Github -Probleme | Meldung von Fehler und Anmeldungsanfragen. |
| Locker | Zusammenarbeit mit anderen Xorbits -Benutzern. |
| Auf dem Laufenden über neue Funktionen auf dem Laufenden bleiben. |
Wenn diese Arbeit hilfreich ist, zitieren Sie bitte bitte:
@inproceedings { lu2024xinference ,
title = " Xinference: Making Large Model Serving Easy " ,
author = " Lu, Weizheng and Xiong, Lingfeng and Zhang, Feng and Qin, Xuye and Chen, Yueguo " ,
booktitle = " Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing: System Demonstrations " ,
month = nov,
year = " 2024 " ,
address = " Miami, Florida, USA " ,
publisher = " Association for Computational Linguistics " ,
url = " https://aclanthology.org/2024.emnlp-demo.30 " ,
pages = " 291--300 " ,
}

