Impresionantes modelos semánticos para la recuperación de la primera etapa
Nota:
- Una lista curada de documentos increíbles para la recuperación semántica , incluidos algunos métodos tempranos y modelos neuronales recientes para tareas de recuperación de información (por ejemplo, recuperación ad-hoc, control de calidad de dominio abierto, control de calidad comunitario y conversación automática).
- Para los investigadores que desean adquirir modelos semánticos para un reanicación de etapas, remitimos a los lectores a la impresionante encuesta Neuir de Guo et.al.
- Cualquier comentario y contribución es bienvenido, por favor abra un problema o contácteme.
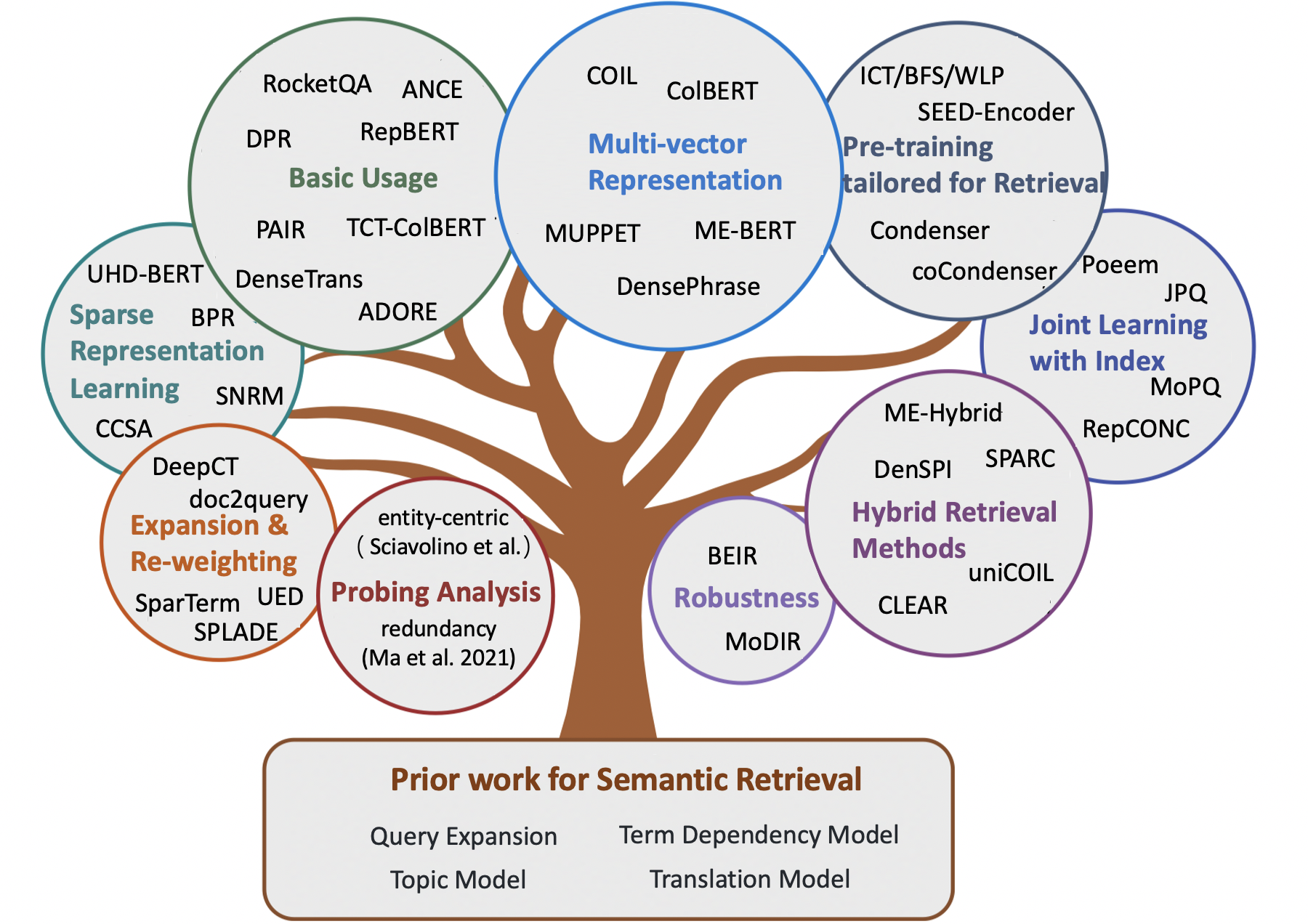
Contenido
- Documento de encuesta
- Capítulo 1: Recuperación clásica basada en términos
- Capítulo 2: Métodos tempranos para la recuperación semántica
- Expansión de la consulta
- Expansión de documentos
- Modelo de dependencia
- Modelo de tema
- Modelo de traducción
- Capítulo 3: Métodos neuronales para la recuperación semántica
- Métodos de recuperación escasa
- Métodos de recuperación densa
- Métodos de recuperación híbridos
- Capítulo 4: Otros recursos
- Otras tareas
- Conjuntos de datos
- Métodos de indexación
Documento de encuesta
- Matricia semántica en la búsqueda (Li et al., 2014)
- Transformadores previos a la clasificación de texto: Bert y más allá (Lin et al., 2021, Arxiv)
- Modelos semánticos para la recuperación de la primera etapa: una revisión exhaustiva (Guo et al., 2021, tois)

- Un marco conceptual propuesto para un enfoque representativo para la recuperación de información (Lin et al., 2021, ARXIV)
- Métodos previos al entrenamiento en la recuperación de información (Fan et al., 2022, ARXIV)
- Recuperación de texto denso basado en modelos de lenguaje previos a la aparición: una encuesta (Zhao et al., 2022, ARXIV)
- Recuperación densa de baja recepción para la respuesta de las preguntas de dominio abierto: una encuesta integral (Shen et al., 2022, ARXIV)
- Notas de conferencia sobre la recuperación de información neural (Tonellotto et al., 2022, ARXIV)
Recuperación clásica basada en términos
- Un modelo de espacio vectorial para la indexación automática (1975, VSM )
- Desarrollos en recuperación de texto automático (1991, TFIDF )
- Enfoques de peso de término en la recuperación de texto automático (1988, TFIDF )
- Ponderación de relevancia de los términos de búsqueda (1976, BIM )
- Una base teórica para el uso de datos de concurrencia en la recuperación de información (1997, Modelo de dependencia de árboles )
- El marco de relevancia probabilística: BM25 y más allá de (2010, BM25 )
- Un enfoque de modelado de idiomas para la recuperación de información (1998, QL )
- Modelos de lenguaje estadístico para la recuperación de información (2007, LM para IR )
- Modelo de lenguaje hipergeométrico y función de puntuación similar a ZIPF para la recuperación de similitud de documentos web (2010, LM para IR )
- Modelos probabilísticos de recuperación de información basados en medir la divergencia de la aleatoriedad (2002, DFR )
Métodos tempranos para la recuperación semántica
Expansión de la consulta
- Modelo global
- Asociaciones de palabras de palabras en sistemas de recuperación de documentos (1969)
- Expansión de consultas basada en el concepto (1993)
- Expansión de consulta utilizando relaciones léxicas semánticas (1994)
- Uso de contextos de consulta en la recuperación de información (2007)
- Modelo local
- Comentarios de relevancia en la recuperación de información (1971, Rocchio PRF )
- Comentarios basados en modelos en el enfoque de modelado de idiomas para la recuperación de información (2001, Modelo de minimización de divergencia )
- UMass en Trec 2004: Novedad y duro (2004, RM3 para PRF )
- Selección de buenos términos de expansión para la retroalimentación de pseudo-relevancia (2008, PRF)
- Un estudio comparativo de métodos para estimar modelos de lenguaje de consulta con pseudo retroalimentación (2009)
- Comentarios de pseudo-relevancia basado en la factorización de matriz (2016)
- Reducción del riesgo de expansión de consulta a través de una optimización limitada robusta (2009, problema de deriva de consultas )
- Expansión de consulta utilizando análisis de documentos locales y globales (2017)
Expansión de documentos
- Estructura del corpus, modelos de idiomas y recuperación de información ad hoc (2004)
- Recuperación basada en clúster utilizando modelos de lenguaje (2004)
- Recuperación de información del modelo de idioma con expansión de documentos (2006)
- Expansión de documentos basada en WordNet para ROBUSTI IR (2010)
- Mejora de la recuperación de textos cortos a través de la expansión de documentos (2012)
- Expansión del documento utilizando colecciones externas (2017, Basado en WordNet ))
- Expansión de documentos versus expansión de consulta para recuperación ad-hoc (2005)
Modelo de dependencia
- Experimentos en indexación de frases automáticas para la recuperación de documentos: una comparación de métodos sintácticos y no sintácticos (1987, VSM + Dependencia de términos )
- Enfoques de peso de término en la recuperación de texto automático (1988, VSM + Dependencia del término )
- Un análisis de frases estadísticas y sintácticas (1997, VSM + Dependencia del término )
- Un modelo probabilístico de recuperación de información: desarrollo y experimentos comparativos (2000, VSM + Term Dependency )
- Ranking de relevancia utilizando los núcleos (2010, dependencia del término BM25 + )
- Un modelo de idioma general para la recuperación de información (1999, LM + Dependencia del término )
- Modelos de lenguaje Biterm para la recuperación de documentos (2002, LM + Term Dependency )
- Captura de dependencias de términos utilizando un modelo de lenguaje basado en árboles de oraciones (2002, dependencia de términos LM + )
- Modelo de lenguaje de dependencia para la recuperación de información (2004, LM + Término Dependencia )
- Una teoría generativa de relevancia (2008)
- Un modelo de campo aleatorio de Markov para dependencias de términos (2005, SDM )
Modelo de tema
- Modelo de espacio vectorial generalizado en recuperación de información (1985, GVSM )
- Indexación por análisis semántico latente (1990, LSI para IR )
- Indexación semántica latente probabilística (2017, PLSA, Combine linealmente )
- Estructura del corpus, modelos de idiomas y recuperación de información ad hoc (2004, suavizado )
- Regularización de puntajes de recuperación ad hoc (2005, suavizado )
- Modelos de documentos basados en LDA para la recuperación ad-hoc (2006, LDA para IR y LDA para suavizado de LM )
- Un estudio comparativo sobre la utilización de modelos temáticos para la recuperación de información (2009, suavizado )
- Investigación del desempeño de la tarea de los modelos de temas probabilísticos: un estudio empírico de PLSA y LDA (2010)
- La indexación semántica latente (LSI) falla para las colecciones TREC (2011)
Modelo de traducción
- Recuperación de información como traducción estadística (1999)
- Estimación de modelos de traducción estadística basados en información mutua para la recuperación de información ad hoc (2010)
- Modelos de traducción basados en clic a través de la búsqueda web: desde modelos de palabras hasta modelos de frases (2010)
- Análisis axiomático del modelo de lenguaje de traducción para la recuperación de información (2012)
- Reescritura de consulta utilizando traducción de máquina estadística monolingüe (2010, para la expansión de la consulta )
- Hacia modelos de traducción basados en conceptos utilizando registros de búsqueda para la expansión de consultas (2012, para la expansión de consultas )
Métodos neuronales para la recuperación semántica
Métodos de recuperación escasa
- Término re-peso
- Aprendiendo a rehacer los términos con representaciones distribuidas (Zheng et al., 2015, Sigir, DeepTR )
- Integración y evaluación de incrustaciones de palabras neuronales en la recuperación de información (Zuccon et al., 2015, ADCS, NTLM )
- Término de aprendizaje Discriminación (Frej et al, 2020, Sigir, TDV )
- Context-Conteurado de oración/pasaje Estimación de importancia para la recuperación de la primera etapa (Dai et al., 2019, ARXIV, DeepCT )
- Ponderación de términos conscientes del contexto para la recuperación de pasaje en la primera etapa (Dai et al., 2020, Sigir, Deepct )
- Implicaciones de eficiencia de la ponderación del término para la recuperación del pasaje (Mackenzie et al., 2020, Sigir, DeepCT )
- Ponderación de término de documento consciente de contexto para la búsqueda ad-hoc (Dai et al., 2020, www, HDCT )
- Algunas notas breves sobre Deepimpact, Coil y un marco conceptual para las técnicas de recuperación de información (Lin et al., 2021, Arxiv, UniCoil )
- Expansión
- Expansión de documentos por Predicción de consultas (Nogueira et al., 2019, ARXIV, DOC2Query )
- De Doc2Query a Doctttttory (Nogueira et al., 2019, Arxiv, DocttttQuery )
- Un marco de previación unificado para la clasificación y expansión del paso (Yan et al., 2021, AAAI, UED )
- Recuperación de la generación de la generación para la respuesta de las preguntas de dominio abierto (Mao et al., 2020, ACL, GAR , Consulta Expansión )
- Expansión + re-pescado de término
- Expansión a través de la predicción de importancia con la contextualización (Macavaney et al., 2020, Sigir, Epic )
- SPARMER: Aprendizaje de representación escasa basada en términos para recuperación de texto rápido (Bai et al., 2020, ARXIV, SPARMERT )
- Flade: modelo de expansión y léxico escaso para la clasificación de la primera etapa (Formal et al., 2021, Sigir, Splade )
- Splade V2: modelo de expansión y léxico escaso para la recuperación de información (Formal et al., 2021, ARXIV, Spladev2 )
- Impactos de pasaje de aprendizaje para índices invertidos (Mallia et al., 2021, Sigir, Deepimapct )
- Tilde: Modelo de probabilidad independiente de término para el re-rango de pasaje (Zhuang et al., 2021, Sigir, Tilde )
- Re-rango de pasaje rápido con coincidencia de término exacto contextualizado y expansión de pasaje eficiente (Zhuang et al., 2021, Arxiv, Tildev2 )
- Spade: Mejora de representaciones dispersas utilizando un codificador de documentos dual para la recuperación de la primera etapa (Choi et al., 2022, CIKM)
- Aprendizaje de representación escasa
- Hashing semántico (Salakhutdinov et al., 2009)
- Desde la clasificación neuronal hasta la clasificación neural: aprendiendo una representación escasa para la indexación invertida (Zamani et al., 2018, CIKM, SNRM )
- UHD-Bert: representaciones escasas ultra altas dimensionales para la clasificación completa (Jang et al., 2021, Arxiv, Uhd-Bert )
- Recuperación de pasaje eficiente con hashing para preguntas de dominio abierto (Yamada et al., 2021, ACL, BPR )
- Código compuesto Autoencoders escasos para la recuperación de la primera etapa (Lassance et al., 2021, Sigir, CCSA )
Métodos de recuperación densa
- Basado en palabras
- Agregando incrustaciones de palabras continuas para la recuperación de información (Clinchant et al., 2013, ACL, FV )
- Modelos de recuperación de información monolingües e interlingües basados en incrustaciones de palabras (bilingües) (Vulic et al., 2015, Sigir)
- Similitud de texto corto con incrustaciones de palabras (Kenter et al., 2015, CIKM, OOB )
- Un modelo espacial de doble incrustación para la clasificación de documentos (Mitra et al., 2016, ARXIV, DESM )
- Sugerencia eficiente de respuesta del lenguaje natural para la respuesta inteligente (Henderson et al., 2017, ARXIV)
- Recuperación de extremo a extremo en el espacio continuo (Gillick et al., 2018, Arxiv)
- Respuesta de preguntas indexadas por frase: un nuevo desafío para la comprensión de documentos escalables (Seo et al., 2018, EMNLP, PIQA )
- Recuperación de pasaje denso para preguntas de dominio abierto (Karpukhin et al., 2020, EMNLP, DPR )
- Generación de recuperación auggada para tareas de PNL intensivas en conocimiento (Lewis et al., 2020, NIPS, RAG )
- Repbert: Incrustos de texto contextualizados para la recuperación de la primera etapa (Zhan et al., 2020, Arxiv, Repbert )
- Cort: clasificaciones complementarias de Transformers (Wrzalik et al., 2020, Naacl, Cort )
- DC-Bert: Pregunta y documento de desacoplamiento para una codificación contextual eficiente (Nie et al., 2020, Sigir, DC-Bert )
- Recuperación neural para la respuesta de preguntas con el aumento de datos supervisado de atención cruzada (Yang et al., 2021, ACL, Aumento de datos )
- Aprendizaje de contraste negativo más cercano vecino más cercano para la recuperación de texto denso (Xiong et al., 2020, Arxiv, Ance )
- Aprender a recuperar: cómo entrenar un modelo de recuperación densa de manera efectiva y eficiente (Zhan et al., 2020, ARXIV, LTRE )
- GLOW: Red de autoatensión ponderada global para Web (Shan et al, 2020, ARXIV, GLOW )
- Un enfoque de entrenamiento optimizado para la recuperación densa del pasaje para la respuesta de las preguntas de dominio abierto (Qu et al., 2021, ACL, Rocketqa )
- Enseñando eficientemente un retriever denso efectivo con muestreo de temas equilibrados (Hofstätter et al., 2021, Sigir, Tas-equilibrado )))))
- Optimización del entrenamiento del modelo de recuperación densa con negativos duros (Zhan et al., 2021, Sigir, Star/Adore )
- Recuperación densa conversacional de pocos disparos (Yu et al., 2021, Sigir)
- Aprendiendo representaciones densas de frases a escala (Lee et al., 2021, ACL, Frases densas )
- Recuperación densa más robusta con doble aprendizaje contrastante (Lee et al., 2021, Ictir, Dance )
- Par: aprovechando la relación de similitud centrada en el paso para mejorar la recuperación densa del pasaje (Ren et al., 2021, ACL, Par )
- Supervisión guiada por relevancia para OpenQA con Colbert (Khattab et al., 2021, TACL, Colbert-QA )
- Entrenamiento de extremo a extremo del lector y retriever de múltiples documentos para la respuesta de las preguntas de dominio abierto (Sachan et al., 2021, ARXIV, EMDR^2 )
- Mejora de las representaciones de consultas para la recuperación densa con retroalimentación de pseudo relevancia (Yu et al, 2021, CIKM, ANCE-PRF )
- Comentarios de pseudo-relevancia para representación densa de representación múltiple (Wang et al., 2021, Ictir, Colbert-PRF )
- Un ranker semántico discriminativo para la recuperación de preguntas (Cai et al., 2021, Ictir, Densetrans )
- Desacoplamiento de representación para la recuperación de pasaje de dominio abierto (Wu et al., 2021, ARXIV)
- Rocketqav2: un método de entrenamiento conjunto para la recuperación densa del pasaje y el reanejo de pasaje (Ren et al., 2021, EMNLP, Rocketqav2 )
- Entrenamiento eficiente de modelos de recuperación utilizando caché negativo (Lindgren et al., 2021, Neurips)
- Entrenamiento en varias etapas con contraste negativo mejorado para la recuperación de pasos neuronales (Lu et al., 2021, EMNLP)
- Mejora de la recuperación a gran escala basada en la incrustación a través de la mejora de la etiqueta (Liu et al., 2021, EMNLP)
- Recuperación jerárquica densa para la respuesta de las preguntas de dominio abierto (Liu et al., 2021, EMNLP)
- Representación de documentos bio-granulares optimizados progresivamente para recuperación basada en incrustaciones escalables (Xiao er al., 2022, www)
- LED: Retriever denso iluminado con léxico para la recuperación a gran escala (Zhang et al., 2023, www)
- Aggreso: un enfoque simple para la representación textual agregada para la recuperación sólida de pasaje denso (Lin et al., 2022, ARXIV)
- Aprendizaje contrastante consciente de la oración para la recuperación de pasaje de dominio abierto (Wu et al., 2022, ACL)
- Especialización con consumo de tareas para una recuperación densa eficiente y robusta para la respuesta de preguntas de dominio abierto (Cheng et al., 2022, ARXIV)
- Destilación de conocimiento
- Destilar representaciones densas para la clasificación utilizando maestros estrechamente acoplados (Lin et al., 2020, ARXIV, TCT-COLBERT )
- Destilar conocimiento para los botos de chat de recuperación rápida (Tahami et al., 2020, Sigir)
- Destilar el conocimiento del lector a la recuperación para la respuesta de las preguntas (Izacard et al., 2020, Arxiv)
- ¿Es Retriever simplemente un aproximador del lector? (Yang et al., 2020, Arxiv)
- Mejora de los modelos de clasificación de documentos bi-codificadores con dos rankers y la destilación de múltiples maestros (Choi et al., 2021, Sigir, TRMD )
- Mejora de modelos de clasificación neuronal eficientes con destilación de conocimiento entre arquitectura (Hofstätter et al., 2021, ARXIV, Pérdida de margen-MSE )
- Twinbert: Destila de conocimiento a los modelos Bert comprimidos estructurados de gemelo para la recuperación a gran escala (Lu et al., 2022, ARXIV)
- Representación múltiple
- Recuperación de párrafos de múltiples saltos para preguntas de dominio abierto (Feldman et al., 2019, ACL, Muppet )
- Representaciones escasas, densas y atencionales para la recuperación de texto (Luan et al., 2020, Tacl, Me-Bert )
- Colbert: búsqueda eficiente y efectiva de pasaje a través de la interacción tardía contextualizada sobre Bert (Khattab et al., 2020, Sigir, Colbert )
- Coil: revise la coincidencia léxica exacta en la recuperación de información con una lista invertida contextualizada (Gao et al., 2021, NaCl, bobina )
- Mejora de las representaciones de documentos generando incrustaciones de consultas de pseudo para la recuperación densa (Tang et al., 2021, ACL)
- La recuperación de frases aprende la recuperación del pasaje, también (Lee et al., 2021, EMNLP, Frases densas )
- Consulta incrustación de la poda para la recuperación densa (Tonellotto et al., 2021, CIKM)
- Aprendizaje de representación de documentos de visión múltiple para la recuperación densa del dominio abierto (Zhang et al., 2022, ACL)
- Colbertv2: recuperación efectiva y eficiente a través de la interacción tardía liviana (Santhanam, 2022, NAACL)
- Aprendiendo diversas representaciones de documentos con interacciones de consulta profunda para la recuperación densa (Li et al., 2022, ARXIV)
- Modelo basado en la representación de texto de grano de tema para la recuperación de documentos (Du et al., 2022, ICANN)
- Acelerar modelos basados en interacciones
- Incorporación de la suposición de independencia del término de consulta para recuperación y clasificación eficientes utilizando redes neuronales profundas (Mitra et al., 2019, ARXIV)
- Clasificación neuronal basada en interacción eficiente con hashing sensible a la localidad (Ji et al., 2019, www)
- Poly-Enders: Arquitecturas y estrategias de pre-entrenamiento para la puntuación rápida y precisa de la orientación múltiple (Humeau et al., 2020, ICLR, Poly-Enders )
- Marco de clasificación basado en transfoméricos modularizado (Gao et al., 2020, EMNLP, Mores )
- Re-rango de documentos eficientes para transformadores mediante la precomputación de representaciones de términos (Macavaney et al., 2020, Sigir, Prettr )
- Deformador: descomposición de transformadores previamente capacitados para una pregunta más rápida respondiendo (Cao et al., 2020, ACL, deformador )
- Sparta: Respuesta de preguntas de dominio abierto eficiente a través de la recuperación de coincidencia de transformador disperso (Zhao et al., 2020, Arxiv, Sparta )
- Conformador-kernel con el término de consulta Independencia para la recuperación de documentos (Mitra et al., 2020, Arxiv)
- IntTower: la próxima generación de modelo de dos torres para el sistema de rango previo al sistema (Li et al., 2022, CIKM)
- Pre-entrenamiento
- Recuperación latente para la respuesta del dominio abierto débilmente supervisado (Lee et al., 2019, ACL, ORQA )
- Modelo de lenguaje de recuperación de recuperación previa al entrenamiento (Guu et al., 2020, ICML, Reino )
- Tareas previas al entrenamiento para la recuperación a gran escala basada en la incrustación (Chang et al., 2020, ICLR, BFS+WLP+MLM )
- ¿Está su modelo de idioma listo para la representación densa ajustada? (Gao et al., 2021, EMNLP, Condenser )
- Modelo de lenguaje consciente del corpus sin supervisión previa para la recuperación de pasaje denso (Gao et al., 2021, Arxiv, Cocondenser )
- Menos es más: previamente entrenando un codificador siamés fuerte usando un decodificador débil (Lu et al., 2021, EMNLP, codificador de semillas )
- Modelo de lenguaje previamente capacitado para la recuperación a escala web en Baidu Search (Liu et al., 2021, KDD)
- Presentamiento previo para la recuperación ad-hoc: Hyperlink es también que necesita (Ma et al., 2021, CIKM, HARP )
- Presena un codificador de texto discriminativo para la recuperación densa a través de la predicción del tramo contrastante (Ma et al., 2022, Sigir)
- TSDAE: Uso de la secuencia secuencial basada en transformador de la auto-codificadora para el aprendizaje de incrustación de oraciones no supervisadas (Wang et al., 2021, EMNLP)
- Masca contextual Auto-codificador para recuperación de pasaje denso (Wu et al., 2022, Arxiv)
- SIMLM: Pre-capacitación con cuello de botella de representación para recuperación de pasaje denso (Wang et al., 2022, ARXIV)
- LEXMAE: Pretratenamiento con cuello de léxico para la recuperación a gran escala (Shen et al., 2022, ARXIV)
- Un enfoque contrastante previo al entrenamiento para aprender autoencoder discriminativo para la recuperación densa (Ma et al., 2022, CIKM)
- RETROMAE: modelos de lenguaje orientado a la recuperación previa al entrenamiento a través de un codificador automático enmascarado (Xiao y Liu et al., 2022, EMNLP)
- Modelo de lenguaje de pre-entrenamiento orientado a la recuperación para la recuperación de pasaje denso (Long et al., 2022, Arxiv)
- Laprador: Retriever denso previamente supervestado para la recuperación de texto de disparo cero (Xu et al., 2022, ACL)
- Autoencoders enmascarados como estudiantes unificados para la representación de oraciones previamente capacitada (Liu et al., 2022, ARXIV)
- Maestro: los autoencoders enmascarados con cuello de botella de varias tareas de tarea son mejores retrievers densos (Zhou et al., 2023, ICLR)
- Cot-mae v2: codificador automático enmascarado contextual con modelado de visión múltiple para la recuperación de pasaje (Wu et al., 2023, ARXIV)
- Cot-Mote: Explorando el pre-entrenador autoenvestible contextual enmascarado con experiencia de mezcla de texto textual para la recuperación de pasaje (Ma et al., 2023, ARXIV)
- Aprendizaje conjunto con índice
- Aprendizaje conjunto del modelo de recuperación profunda y el índice de incrustación basado en cuantificación de productos (Zhang et al., 2021, Sigir, Poeem )
- Optimización conjunta del codificador de consultas y cuantificación del producto para mejorar el rendimiento de la recuperación (Zhan et al., 2021, CIKM, JPQ )
- Cuantización de productos orientado a la coincidencia para la recuperación ad-hoc (Xiao et al., 2021, EMNLP, MOPQ )
- Aprendiendo representaciones discretas a través de una agrupación restringida para una recuperación densa efectiva y eficiente (Zhan et al, 2022, WSDM, Repconc )
- Aprendizaje conjunto con Ranker
- Entrenamiento de extremo a extremo de retriever neural para la respuesta de las preguntas de dominio abierto (Sachan et al., 2021, ACL)
- Ranker de retriever adversario para recuperación de texto denso (Zhang et al., 2022, ICLR)
- Debias
- Aprendiendo modelos de recuperación densa robustos de etiquetas de relevancia incompleta (Prakash et al., 2021, Sigir, Rance )
- Negativos duros o falsos negativos: corrección de sesgo de agrupación en el entrenamiento de modelos de clasificación neuronal (Cai et al., 2022, CIKM)
- SIMANS: Muestreo de negativos ambiguos simples para la recuperación de texto denso (Zhou et al., 2022, EMNLP)
- Aprendizaje contrastante de debiaje de representaciones de oraciones no supervisadas (Zhou et al., 2022, ACL)
- Recuperación del oro de la arena negra: recuperación de pasaje denso multilingüe con muestras dura y falsas negativas (Shen et al., 2022, EMNLP)
- Shot cero/pocos disparos
- Recuperación de disparo cero basado en incrustaciones a través de la generación de consultas (Liang et al., 2020, ARXIV)
- Recuperación de pasaje neural de disparo cero a través de la generación de preguntas sintéticas dirigidas al dominio (Ma et al., 2020, Qgen , ARXIV)
- Hacia modelos robustos de recuperación neuronal con pre-entrenamiento sintético (Reddy et al., 2021, ARXIV)
- Beir: un punto de referencia heterogéneo para la evaluación de disparos cero de los modelos de recuperación de información (Thakur et al., 2021, Neurips)
- Recuperación densa de disparo cero con representaciones invariantes de dominio adversario de impulso (Xin et al., 2021, Arxiv, Modir )
- Los grandes codificadores duales son retrievers generalizables (Ni et al., 2022, EMNLP, DTR )
- ¡Semántica fuera de dominio al rescate! Modelos de recuperación híbrida de disparo cero (Chen et al., 2022, ECIR)
- INPARS: Aumento de datos para la recuperación de información utilizando modelos de idiomas grandes (Bonifacio et al., 2022, ARXIV)
- Hacia la recuperación de información densa no supervisada con aprendizaje contrastante (Izacard et al., 2021, ARXIV, contrario )
- GPL: etiquetado pseudo generativo para la adaptación del dominio no supervisado de la recuperación densa (Wang et al., 2022, NAACL)
- Aprender a recuperar pasajes sin supervisión (Ram et al., 2021, ARXIV, Spider )
- Un examen exhaustivo sobre la recuperación densa de cero (Ren et al., 2022, ARXIV)
- Incrustos de texto y código por pre-entrenamiento contrastante (Neelakantan et al., 2022, ARXIV)
- Modelado desactivado del dominio y relevancia para la recuperación densa adaptable (Zhan et al., 2022, ARXIV)
- PractAgator: recuperación densa de pocos disparos de 8 ejemplos (Dai et al., 2022, Arxiv)
- Las preguntas son todo lo que necesita para entrenar a un pasaje denso Retriever (Sachan et al., 2022, TACL)
- Hyper: el entrenamiento hiper-prompitado multitarea permite la generalización de recuperación a gran escala (Cai et al., 2023, ICLR)
- COCO-DR: combatir los cambios de distribución en recuperación densa de disparo cero con aprendizaje contrastante y distributionalmente robusto (Yu et al., 2022, EMNLP)
- Desafíos en la generalización en la respuesta de las preguntas de dominio abierto (Liu et al., 2022, NAACL)
- Robustez
- Hacia una robusta recuperación densa a través de la alineación de clasificación local (Chen et al., 2022, Ijcai)
- Tratando con errores tipográficos para la recuperación y clasificación de pasos basados en Bert (Zhuang et al., 2021, EMNLP)
- Evaluación de la robustez de las tuberías de recuperación con los generadores de variación de consultas (Penha et al., 2022, ECIR)
- Analizando la robustez de los codificadores duales para la recuperación densa contra las ortográficas (Sidiropoulos et al., 2022, Sigir)
- CARACTERBERT y Auto-enseñanza para mejorar la robustez de los densos retrievers en consultas con errores tipográficos (Zhuang et al., 2022, Sigir)
- Los rankers de Bert son frágiles: un estudio que utiliza perturbaciones de documentos adversos (Wang et al., 2022, Ictir)
- Trastorno de pedido: ataques adversos de imitación para modelos de clasificación neuronal de BlackBox (Liu et al., 2022, ARXIV)
- El pre-entrenamiento con cuello de botella con un tipo de botella para una recuperación densa robusta (Zhuang et al., 2023, ARXIV)
- Análisis de sondeo
- La maldición de la densa recuperación de información de baja dimensión para tamaños de índice grandes (Reimers et al., 2021, ACL)
- Eliminación de redundancia no supervisada simple y efectiva para comprimir vectores densos para la recuperación de pasaje (Ma et al., EMNLP, 2021, redundancia )
- Beir: un punto de referencia heterogéneo para la evaluación de disparos cero de los modelos de recuperación de información (Thakur et al., 2021, Neurips, Transferabilidad )
- Frase saliente consciente de recuperación densa: ¿puede un denso retriever imitar uno escaso? (Chen et al., 2021, Arxiv)
- Preguntas simples centradas en la entidad Desafío Dense Retrievers (Sciavolino et al., 2021, EMNLP)
- Interpretación de la recuperación densa como mezcla de temas (Zhan et al., 2021, Arxiv)
- Un análisis de atribución de codificadores para el retriever de pasaje denso en preguntas de dominio abierto (Li et al., 2022, Trustnlp)
- La representación isotrópica puede mejorar la recuperación densa (Jung et al., 2022, Arxiv)
- Aprendizaje rápido
- Modelo de clasificación neural biéndica semi-siamesa utilizando un ajuste ligero (Jung et al., 2022, www)
- Disperso o conectado? Un enfoque de sintonización eficiente de parámetros optimizado para la recuperación de información (Ma et al., 2022, CIKM)
- DPTDR: Añada rápida profunda para la recuperación densa del pasaje (Tang et al., 2022, ARXIV)
- La sintonización rápida de parámetros y los retrievers de texto neuronal generalizado y calibrado (Tam et al., 2022, ARXIV)
- NIR-PROMPT: un marco de capacitación de recuperación de información neuronal generalizada de varias tareas (Xu et al., 2022, ARXIV)
- Modelo de lenguaje grande para la recuperación
- Recuperación densa precisa de disparo cero sin relevancia (Gao et al., 2022, ARXIV)
- Otros
- HLATR: Mejore la recuperación de texto de múltiples etapas con la lista híbrida consciente del transformador Reranking (Zhang et al., 2022, ARXIV)
- Asyncval: un conjunto de herramientas para validación asíncronamente de densos puntos de control de retriever durante el entrenamiento (Zhuang et al., 2022, Sigir)
Métodos de recuperación híbridos
- Basado en palabras
- Modelos de recuperación de información monolingües e interlingües basados en incrustaciones de palabras (bilingües) (Vulic et al., 2015, Sigir, combinan linealmente )
- Modelo de lenguaje generalizado basado en la incrustación de palabras para la recuperación de información (Ganguly et al., 2015, Sigir, GLM )
- Representar documentos y consultas como conjuntos de vectores integrados de palabras para la recuperación de información (Roy et al., 2016, Sigir, combinan linealmente )
- Un modelo espacial de doble incrustación para la clasificación de documentos (Mitra et al., 2016, www, desm_mixture , combina linealmente )
- Off the Beaten Rath: reemplazamos la recuperación basada en términos con K-Nn Search (Boytsov et al., 2016, CIKM, BM25+Modelo de traducción )
- Aprender representaciones híbridas para recuperar preguntas semánticamente equivalentes (Santos et al., 2015, ACL, Bow-CNN )
- Pregunta de dominio abierto en tiempo real respondiendo con índice de frase de la espada densa (Seo et al., 2019, ACL, Denspi )
- Representaciones dispersas contextualizadas para la respuesta de preguntas abiertas en tiempo real (Lee et al., 2020, ACL, SPARC )
- Cort: clasificaciones complementarias de Transformers (Wrzalik et al., 2020, NAACL, Cort_BM25 )
- Representaciones dispersas, densas y atencionales para la recuperación de texto (Luan et al., 2020, TaCl, Me-Hybrid )
- Complemento Modelo de recuperación léxica con integridades residuales semánticas (Gao et al., 2020, ECIR, Clear )
- Aprovechando la coincidencia semántica y léxica para mejorar el retiro de los sistemas de recuperación de documentos: un enfoque híbrido (Kuzi et al., 2020, ARXIV, Hybrid )
- Algunas notas breves sobre Deepimpact, Coil y un marco conceptual para las técnicas de recuperación de información (Lin et al., 2021, ARXIV, UniCoil )
- Ponderación de relevancia fuera de línea contextualizada para recuperación neuronal eficiente y efectiva (Chen et al., 2021, Sigir)
- Predecir la eficiencia/efectividad compensaciones para la selección de estrategia de recuperación densa frente a escasez (Arabzadeh et al., 2021, CIKM)
- Índices de avance rápido para la clasificación eficiente de documentos (Leonhardt et al., 2021, ARXIV)
- Densificación de representaciones dispersas para la recuperación de pasos mediante el corte de representación (Lin et al., 2021, Arxiv)
- UNIFOR: un recipiente unificado para la recuperación a gran escala (Shen et al., 2022, ARXIV)
Otros recursos
Otras tareas
- Búsqueda de comercio electrónico
- Red de interés profundo para la predicción de tasas de clics (Zhou et al., 2018, KDD, DIN )
- Desde la recuperación semántica hasta la clasificación por pares: aplicar el aprendizaje profundo en la búsqueda de comercio electrónico (Li et al., 2019, Sigir, Jingdong)
- Red múltiple de interés con enrutamiento dinámico para recomendación en Tmall (Li et al., 2019, CIKM, Mind , Tmall)
- Hacia la recuperación personalizada y semántica: una solución de extremo a extremo para la búsqueda de comercio electrónico a través de la incrustación del aprendizaje (Zhang et al., 2020, Sigir, DPSR , Jingdong)
- Red de múltiples intereses profundos para la predicción de la tasa de clics (Xiao et al., 2020, CIKM, Dmin )
- Recuperación profunda: un modelo de estructura aprendible de extremo a extremo para recomendaciones a gran escala (Gao et al., 2020, ARXIV)
- Recuperación de productos basado en la incrustación en la búsqueda de Taobao (Li et al., 2021, KDD, Taobao)
- Estructura de abrazo en los datos para la búsqueda de productos semánticos a escala de miles de millones (Lakshman et al., 2021, Arxiv, Amazon)
- Búsqueda patrocinada
- Mobius: Hacia la próxima generación de coincidencia de consultas en la búsqueda patrocinada por Baidu (Fan et al., 2019, KDD, Baidu)
- Recuperación de imágenes
- NUCHA BARINARIA NETA NURAL PARA RECUPERACIÓN DE IMAGEN (ZHANG ET AL., 2021, SIGIR, BNNH )
- Hasfilado autoadaptativo profundo para la recuperación de imágenes (Lin et al., 2021, CIKM, DSAH )
- Informe sobre el primer taller de hipstir sobre el futuro de la recuperación de información (Dietz et al., 2019, Sigir, taller)
- ¡Medimos el tiempo de ejecución! Extender la infraestructura de replicabilidad IR para incluir aspectos de rendimiento (Hofstätter et al., 2019, Sigir)
- Recuperación basada en la incrustación en la búsqueda de Facebook (Huang et al., 2020, KDD, EBR )
- Aprendizaje de códigos discretos D-Dimensionales K-Way para representaciones de incrustación compactas (Chen et al., 2018, ICML)
Conjuntos de datos
- 【MS Marco】 MS Marco: un conjunto de datos de comprensión de lectura en máquina generada por humanos
- 【CAR TREC】 Descripción general de la recuperación de respuestas complejas TREC
- 【TREC DL】 Descripción general de la pista de aprendizaje profundo TREC 2019
- 【TREC Covid】 Trec-Covid: Construcción de una recopilación de pruebas de recuperación de información de pandemia
Métodos de indexación
- Basado en árboles
- Árboles de búsqueda binarios multidimensionales utilizados para la búsqueda asociativa (1975, KD Tree )
- Enojarse
- Basado en el hash
- Vecinos aproximados más cercanos: hacia la eliminación de la maldición de la dimensionalidad (1998, LSH )
- Basado en cuantización
- Cuantización de productos para la búsqueda de vecinos más cercanos (2010, PQ )
- Cuantización de productos optimizado (2013, OPQ )
- Basado en gráficos
- Navegación en un mundo pequeño (2000, NSW )
- Búsqueda de vecinos más cercanos más eficientes y robustos utilizando gráficos jerárquicos de Werchical Navigable Small World (2018, HNSW )
- Kilets de herramientas
- FAISS: una biblioteca para una búsqueda y agrupación de similitud eficientes de vectores densos
- SPTAG: una biblioteca para la búsqueda rápida de vecinos más cercanos.
- OpenMatch: un paquete de código abierto para la recuperación de información
- Pyserini: un conjunto de herramientas de Python para la investigación de recuperación de información reproducible con representaciones escasas y densas
- Elasticsearch


