โมเดลความหมายที่ยอดเยี่ยมสำหรับการดึงข้อมูลระยะแรก
บันทึก:
- รายการเอกสารที่ยอดเยี่ยมสำหรับ การดึงความหมาย รวมถึงวิธีการบางอย่างและแบบจำลองระบบประสาทล่าสุดสำหรับงานดึงข้อมูล (เช่นการดึงข้อมูลแบบ Ad-Hoc, QA แบบเปิดโดเมน, QA ที่ใช้ชุมชนและการสนทนาอัตโนมัติ)
- สำหรับนักวิจัยที่ต้องการได้รับแบบจำลองความหมายสำหรับขั้นตอนการจัดอันดับใหม่เราแนะนำผู้อ่านไปยังการสำรวจ Neuir ที่ยอดเยี่ยมโดย Guo Et.al
- ยินดีต้อนรับข้อเสนอแนะและการบริจาคโปรดเปิดปัญหาหรือติดต่อฉัน
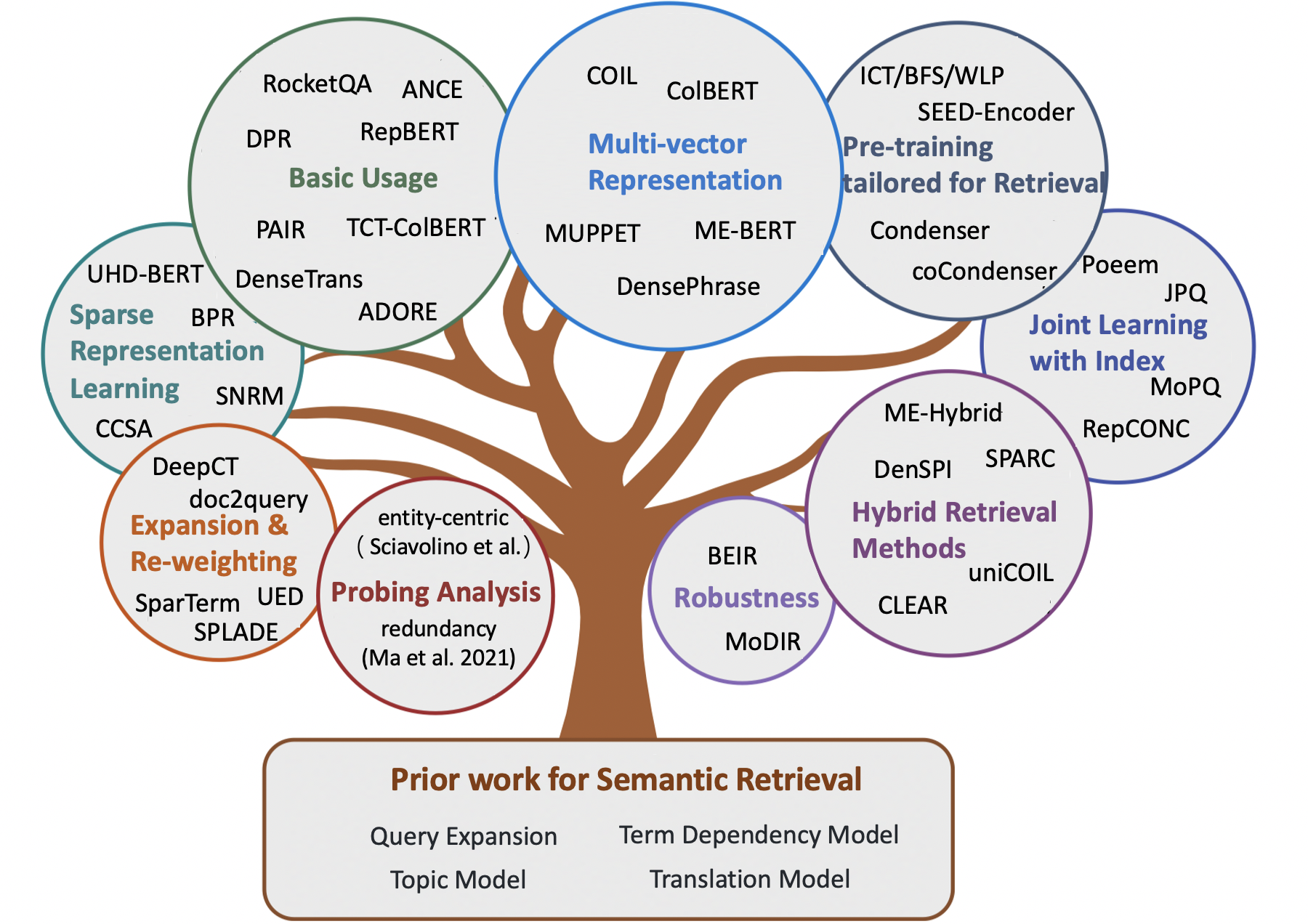
สารบัญ
- กระดาษสำรวจ
- บทที่ 1: การดึงคำศัพท์แบบคลาสสิก
- บทที่ 2: วิธีการเริ่มต้นสำหรับการดึงความหมาย
- การขยายการสอบถาม
- การขยายเอกสาร
- รูปแบบการพึ่งพา
- รูปแบบหัวข้อ
- รูปแบบการแปล
- บทที่ 3: วิธีประสาทสำหรับการดึงความหมาย
- วิธีการดึงข้อมูลแบบเบาบาง
- วิธีการดึงข้อมูลหนาแน่น
- วิธีการดึงแบบไฮบริด
- บทที่ 4: ทรัพยากรอื่น ๆ
- งานอื่น ๆ
- ชุดข้อมูล
- วิธีการจัดทำดัชนี
กระดาษสำรวจ
- การจับคู่ความหมายในการค้นหา (li et al., 2014)
- หม้อแปลงที่ผ่านการฝึกอบรมสำหรับการจัดอันดับข้อความ: เบิร์ตและเกินกว่า (Lin et al., 2021, arxiv)
- โมเดลความหมายสำหรับการดึงข้อมูลขั้นแรก: การทบทวนที่ครอบคลุม (Guo et al., 2021, TOIs)

- กรอบแนวคิดที่เสนอสำหรับวิธีการเป็นตัวแทนในการดึงข้อมูล (Lin et al., 2021, arxiv)
- วิธีการฝึกอบรมล่วงหน้าในการดึงข้อมูล (Fan et al., 2022, arxiv)
- การดึงข้อความหนาแน่นขึ้นอยู่กับแบบจำลองภาษาที่ผ่านการฝึกอบรม: การสำรวจ (Zhao et al., 2022, arxiv)
- การดึงข้อมูลหนาแน่นทรัพยากรต่ำสำหรับการตอบคำถามแบบเปิดโดเมน: การสำรวจที่ครอบคลุม (Shen et al., 2022, arxiv)
- บันทึกการบรรยายเกี่ยวกับการดึงข้อมูลระบบประสาท (Tonellotto et al., 2022, arxiv)
การดึงคำศัพท์แบบคลาสสิก
- โมเดลพื้นที่เวกเตอร์สำหรับการจัดทำดัชนีอัตโนมัติ (1975, VSM )
- การพัฒนาในการดึงข้อความอัตโนมัติ (1991, TFIDF )
- แนวทางการถ่วงน้ำหนักในการดึงข้อความอัตโนมัติ (1988, TFIDF )
- น้ำหนักที่เกี่ยวข้องของคำค้นหา (1976, BIM )
- พื้นฐานทางทฤษฎีสำหรับการใช้ข้อมูลการเกิดร่วมในการดึงข้อมูล (1997, แบบจำลองการพึ่งพาต้นไม้ )
- กรอบความเกี่ยวข้องความน่าจะเป็น: BM25 และเกินกว่า (2010, BM25 )
- วิธีการสร้างแบบจำลองภาษาเพื่อการดึงข้อมูล (1998, QL )
- แบบจำลองภาษาทางสถิติสำหรับการดึงข้อมูล (2007, LM สำหรับ IR )
- โมเดลภาษา Hypergeometric และฟังก์ชั่นการให้คะแนนคล้าย ZIPF สำหรับเอกสารการดึงข้อมูลที่คล้ายคลึงกันของเว็บ (2010, LM สำหรับ IR )
- แบบจำลองความน่าจะเป็นของการดึงข้อมูลขึ้นอยู่กับการวัดความแตกต่างจากการสุ่ม (2002, DFR )
วิธีการเริ่มต้นสำหรับการดึงความหมาย
การขยายการสอบถาม
- รุ่นระดับโลก
- การเชื่อมโยงคำว่าคำในระบบดึงเอกสาร (1969)
- การขยายแบบสอบถามตามแนวคิด (1993)
- การขยายแบบสอบถามโดยใช้ความสัมพันธ์แบบคำศัพท์-ศาสตร์ (1994)
- การใช้บริบทแบบสอบถามในการดึงข้อมูล (2007)
- รุ่นท้องถิ่น
- ข้อเสนอแนะที่เกี่ยวข้องในการดึงข้อมูล (1971, Rocchio PRF )
- ข้อเสนอแนะแบบจำลองแบบในวิธีการสร้างแบบจำลองภาษาเพื่อการดึงข้อมูล (2001, โมเดลการย่อขนาด Divergence )
- UMass ที่ TREC 2004: ความแปลกใหม่และยาก (2004, RM3 สำหรับ PRF )
- การเลือกเงื่อนไขการขยายตัวที่ดีสำหรับข้อเสนอแนะแบบหลอกเทียม (2008, PRF)
- การศึกษาเปรียบเทียบวิธีการประเมินแบบจำลองภาษาแบบสอบถามด้วยคำติชมแบบหลอก (2009)
- คำติชมแบบ Pseudo-RELEVANCE ตามการแยกตัวประกอบเมทริกซ์ (2016)
- ลดความเสี่ยงของการขยายตัวของการสืบค้นผ่านการปรับให้เหมาะสมที่ จำกัด ( ปัญหาการดริฟท์แบบสอบถาม, คำถามดริฟท์แบบสอบถาม )
- การขยายแบบสอบถามโดยใช้การวิเคราะห์เอกสารในท้องถิ่นและระดับโลก (2017)
การขยายเอกสาร
- โครงสร้างคลังข้อมูลแบบจำลองภาษาและการดึงข้อมูลเฉพาะกิจ (2004)
- การดึงข้อมูลแบบคลัสเตอร์โดยใช้แบบจำลองภาษา (2004)
- การดึงข้อมูลรูปแบบภาษาพร้อมการขยายเอกสาร (2549)
- การขยายเอกสารขึ้นอยู่กับ WordNet สำหรับ IR ที่แข็งแกร่ง (2010)
- การปรับปรุงการดึงข้อความสั้น ๆ ผ่านการขยายเอกสาร (2012)
- การขยายเอกสารโดยใช้คอลเลกชันภายนอก (2017, WordNet-based )
- การขยายเอกสารเทียบกับการขยายแบบสอบถามสำหรับการดึงข้อมูลแบบ Ad-Hoc (2005)
รูปแบบการพึ่งพา
- การทดลองในการจัดทำดัชนีวลีอัตโนมัติสำหรับการดึงเอกสาร: การเปรียบเทียบวิธีการทางวากยสัมพันธ์และวิธีการไม่ syntactic (1987, VSM + การพึ่งพาคำศัพท์ )
- แนวทางการชั่งน้ำหนักคำศัพท์ในการดึงข้อความอัตโนมัติ (1988, VSM + การพึ่งพาคำศัพท์ )
- การวิเคราะห์วลีทางสถิติและวากยสัมพันธ์ (1997, VSM + การพึ่งพาระยะยาว )
- รูปแบบความน่าจะเป็นของการดึงข้อมูล: การพัฒนาและการทดลองเปรียบเทียบ (2000, VSM + การพึ่งพาคำศัพท์ )
- การจัดอันดับความเกี่ยวข้องโดยใช้เคอร์เนล (2010, BM25 + เทอมการพึ่งพา )
- รูปแบบภาษาทั่วไปสำหรับการดึงข้อมูล (1999, LM + การพึ่งพาคำศัพท์ )
- โมเดลภาษาบดสำหรับการดึงเอกสาร (2002, LM + การพึ่งพาคำศัพท์ )
- การจับคำพึ่งพาคำโดยใช้แบบจำลองภาษาตามต้นไม้ประโยค (2002, การพึ่งพาระยะยาว LM + )
- แบบจำลองภาษาพึ่งพาสำหรับการดึงข้อมูล (2004, LM + คำพึ่งพาอาศัยกัน )
- ทฤษฎีการกำเนิดของความเกี่ยวข้อง (2008)
- โมเดลฟิลด์แบบสุ่มของ Markov สำหรับการพึ่งพาคำศัพท์ (2005, SDM )
รูปแบบหัวข้อ
- แบบจำลองพื้นที่เวกเตอร์ทั่วไปในการดึงข้อมูล (1985, GVSM )
- การจัดทำดัชนีโดยการวิเคราะห์ความหมายแฝง (1990, LSI สำหรับ IR )
- การจัดทำดัชนีความหมายแฝงความน่าจะเป็น (2017, PLSA, รวมเป็นเส้นตรง )
- โครงสร้างคลังข้อมูลแบบจำลองภาษาและการดึงข้อมูลเฉพาะกิจ (2004 การปรับให้เรียบ )
- การทำให้คะแนนการดึงข้อมูลเฉพาะกิจเป็นปกติ (2005, Smoothing )
- โมเดลเอกสารที่ใช้ LDA สำหรับ Ad-Hoc Retrieval (2006, LDA สำหรับ IR และ LDA สำหรับการปรับให้เรียบ LM )
- การศึกษาเปรียบเทียบแบบจำลองหัวข้อสำหรับการดึงข้อมูล (2009, Smoothing )
- การตรวจสอบประสิทธิภาพงานของแบบจำลองหัวข้อความน่าจะเป็น: การศึกษาเชิงประจักษ์ของ PLSA และ LDA (2010)
- การจัดทำดัชนีความหมายแฝง (LSI) ล้มเหลวสำหรับคอลเลกชัน TREC (2011)
รูปแบบการแปล
- การดึงข้อมูลเป็นการแปลทางสถิติ (1999)
- การประมาณรูปแบบการแปลทางสถิติตามข้อมูลร่วมกันสำหรับการดึงข้อมูลเฉพาะกิจ (2010)
- โมเดลการแปลที่ใช้ ClickThrough สำหรับการค้นหาเว็บ: จากโมเดลคำไปจนถึงรูปแบบวลี (2010)
- การวิเคราะห์แบบ Axiomatic ของแบบจำลองภาษาการแปลสำหรับการดึงข้อมูล (2012)
- การสืบค้นใหม่โดยใช้การแปลเครื่องสถิติแบบ monolingual (2010 สำหรับการขยายแบบสอบถาม )
- สู่รูปแบบการแปลตามแนวคิดโดยใช้บันทึกการค้นหาสำหรับการขยายแบบสอบถาม (2012 สำหรับการขยายแบบสอบถาม )
วิธีประสาทสำหรับการดึงความหมาย
วิธีการดึงข้อมูลแบบเบาบาง
- คำศัพท์ใหม่
- เรียนรู้ที่จะน้ำหนักคำศัพท์ใหม่ด้วยการเป็นตัวแทนแบบกระจาย (Zheng et al., 2015, Sigir, Deeptr )
- การบูรณาการและประเมินผลคำศัพท์ประสาทในการดึงข้อมูล (Zuccon et al., 2015, ADCS, NTLM )
- การเรียนรู้การเลือกปฏิบัติ (Frej et al, 2020, Sigir, TDV )
- ประโยคที่รับรู้บริบท/คำศัพท์ที่สำคัญสำหรับการประมาณค่าสำหรับการดึงขั้นตอนแรก (Dai et al., 2019, arxiv, deepct )
- การถ่วงน้ำหนักตามบริบทสำหรับการดึงข้อมูลขั้นตอนแรก (Dai et al., 2020, Sigir, DeepCT )
- ผลกระทบด้านประสิทธิภาพของการถ่วงน้ำหนักคำศัพท์สำหรับการดึงทาง (Mackenzie et al., 2020, SIGIR, DeepCT )
- เอกสารบริบทที่รับรู้ถ่วงน้ำหนักสำหรับการค้นหา ad-hoc (Dai et al., 2020, www, HDCT )
- บันทึกย่อสั้น ๆ เกี่ยวกับ DeepImpact, ขดลวดและกรอบแนวคิดสำหรับเทคนิคการดึงข้อมูล (Lin Lin et al., 2021, arxiv, unicoil )
- การขยายตัว
- การขยายเอกสารโดยการทำนายแบบสอบถาม (Nogueira et al., 2019, arxiv, doc2Query )
- จาก Doc2Query ถึง Doctttttquery (Nogueira et al., 2019, arxiv, Doctttttquery )
- กรอบการเตรียมการแบบครบวงจรสำหรับการจัดอันดับและการขยายตัว (Yan et al., 2021, AAAI, UED )
- การเรียกคืนการเจนเนอเรชั่นสำหรับการตอบคำถามแบบเปิดโดเมน (Mao et al., 2020, ACL, GAR , การขยายแบบสอบถาม )
- การขยายตัว + การถ่วงน้ำหนักอีกครั้ง
- การขยายตัวผ่านการทำนายความสำคัญด้วยการทำให้เป็นบริบท (Macavaney et al., 2020, Sigir, Epic )
- Sparterm: การเรียนรู้แบบเบาบางตามคำศัพท์สำหรับการดึงข้อความที่รวดเร็ว (Bai et al., 2020, arxiv, Sparterm )
- Splade: โมเดลคำศัพท์และการขยายตัวแบบเบาบางสำหรับการจัดอันดับขั้นตอนแรก (ทางการและคณะ, 2021, sigir, splade )
- Splade V2: โมเดลคำศัพท์และการขยายตัวกระจัดกระจายสำหรับการดึงข้อมูล (อย่างเป็นทางการและคณะ, 2021, arxiv, spladev2 )
- การเรียนรู้ส่งผลกระทบต่อดัชนีคว่ำ (Mallia et al., 2021, Sigir, Deepimapct )
- Tilde: รูปแบบความน่าจะเป็นแบบอิสระสำหรับการจัดอันดับใหม่ (Zhuang et al., 2021, Sigir, Tilde )
- การจัดอันดับอย่างรวดเร็วอีกครั้งด้วยการจับคู่คำที่แน่นอนตามบริบทและการขยายเส้นทางที่มีประสิทธิภาพ (Zhuang et al., 2021, arxiv, tildev2 )
- Spade: การปรับปรุงการเป็นตัวแทนแบบเบาบางโดยใช้ตัวเข้ารหัสเอกสารคู่สำหรับการดึงข้อมูลขั้นแรก (Choi et al., 2022, CIKM)
- การเรียนรู้การเป็นตัวแทนที่กระจัดกระจาย
- Semantic Hashing (Salakhutdinov et al., 2009)
- ตั้งแต่การจัดอันดับของระบบประสาทไปจนถึงการจัดอันดับประสาท: การเรียนรู้การเป็นตัวแทนแบบเบาบางสำหรับการจัดทำดัชนีกลับด้าน (Zamani et al., 2018, CIKM, SNRM )
- UHD-BERT: การเป็นตัวแทนเบาบางที่มีมิติสูงพิเศษสำหรับการจัดอันดับเต็ม (Jang et al., 2021, arxiv, uhd-bert )
- การดึงข้อความที่มีประสิทธิภาพด้วยการแฮชสำหรับคำถามแบบเปิดโดเมนตอบคำถาม (Yamada et al., 2021, ACL, BPR )
- โค้ดคอมโพสิต Sparse Autoencoders สำหรับการดึงขั้นตอนแรก (Lassance et al., 2021, Sigir, CCSA )
วิธีการดึงข้อมูลหนาแน่น
- อิงตามคำศัพท์
- การรวมคำอย่างต่อเนื่องสำหรับการดึงข้อมูล (Clinchant et al., 2013, ACL, FV )
- โมเดลการดึงข้อมูลแบบ monolingual และ cross-lingual ตาม (สองภาษา) Word Embeddings (Vulic et al., 2015, Sigir)
- ข้อความสั้น ๆ ที่คล้ายคลึงกันกับ Word Embeddings (Kenter et al., 2015, CIKM, OOB )
- โมเดลพื้นที่ฝังตัวคู่สำหรับการจัดอันดับเอกสาร (Mitra et al., 2016, arxiv, desm )
- คำแนะนำการตอบสนองภาษาธรรมชาติที่มีประสิทธิภาพสำหรับการตอบกลับอย่างชาญฉลาด (Henderson et al., 2017, arxiv)
- การดึงข้อมูลแบบ end-to-end ในพื้นที่ต่อเนื่อง (Gillick et al., 2018, arxiv)
- การตอบคำถามที่จัดทำดัชนีวลี: ความท้าทายใหม่สำหรับความเข้าใจในเอกสารที่ปรับขนาดได้ (Seo et al., 2018, Emnlp, Piqa )
- การดึงข้อความหนาแน่นสำหรับคำถามแบบเปิดโดเมนตอบคำถาม (Karpukhin et al., 2020, EMNLP, DPR )
- การค้นพบใหม่สำหรับงาน NLP ที่ใช้ความรู้อย่างเข้มข้น (Lewis et al., 2020, NIPS, RAG )
- Repbert: การฝังข้อความตามบริบทสำหรับการดึงขั้นตอนแรก (Zhan et al., 2020, arxiv, repbert )
- Cort: การจัดอันดับเสริมจาก Transformers (Wrzalik et al., 2020, NAACL, CORT )
- DC-BERT: คำถามและเอกสารสำหรับการเข้ารหัสตามบริบทที่มีประสิทธิภาพ (Nie et al., 2020, Sigir, DC-Bert )
- การดึงประสาทสำหรับการตอบคำถามด้วยการเพิ่มข้อมูลการดูแลแบบข้ามความสนใจ (Yang et al., 2021, ACL, การเพิ่มข้อมูล )
- การเรียนรู้ที่ตรงกันข้ามกับเพื่อนบ้านที่ใกล้ที่สุดโดยประมาณสำหรับการดึงข้อความหนาแน่น (Xiong et al., 2020, arxiv, ance )
- การเรียนรู้ที่จะเรียกคืน: วิธีการฝึกแบบจำลองการดึงข้อมูลหนาแน่นอย่างมีประสิทธิภาพและมีประสิทธิภาพ (Zhan et al., 2020, arxiv, ltre )
- Glow: เครือข่ายการดูแลตนเองที่มีน้ำหนักทั่วโลกสำหรับเว็บ (Shan et al, 2020, arxiv, Glow )
- วิธีการฝึกอบรมที่ดีที่สุดในการดึงเส้นทางที่หนาแน่นสำหรับคำถามแบบเปิดโดเมนตอบคำถาม (Qu et al., 2021, ACL, RocketQa )
- การสอนอย่างมีประสิทธิภาพการแก้ไขความหนาแน่นที่มีประสิทธิภาพด้วยการสุ่มตัวอย่างหัวข้อที่สมดุล (Hofstätter et al., 2021, sigir, tas-balanced )
- เพิ่มประสิทธิภาพการฝึกอบรมแบบจำลองการดึงข้อมูลหนาแน่นด้วยเชิงลบอย่างหนัก (Zhan et al., 2021, Sigir, Star/Adore )
- การเรียกร้องการสนทนาแบบหนาแน่นไม่กี่ครั้ง (Yu et al., 2021, Sigir)
- การเรียนรู้การเป็นตัวแทนของวลีที่หนาแน่นในระดับ (Lee et al., 2021, ACL, Densephrases )
- การดึงข้อมูลหนาแน่นที่แข็งแกร่งยิ่งขึ้นด้วยการเรียนรู้แบบคู่ที่ตรงกันข้าม (Lee et al., 2021, ICTIR, Dance )
- คู่: การใช้ประโยชน์จากความสัมพันธ์ที่คล้ายคลึงกันเป็นศูนย์กลางเป็นศูนย์กลางสำหรับการปรับปรุงการดึงเส้นทางหนาแน่น (ren et al., 2021, ACL, pair )
- การกำกับดูแลที่เกี่ยวข้องกับ OpenQa กับ Colbert (Khattab et al., 2021, Tacl, Colbert-Qa )
- การฝึกอบรมแบบ end-to-end ของผู้อ่านหลายเอกสารและรีทรีฟเวอร์สำหรับคำถามแบบเปิดโดเมนตอบคำถาม (Sachan et al., 2021, arxiv, emdr^2 )
- การปรับปรุงการเป็นตัวแทนแบบสอบถามสำหรับการดึงข้อมูลหนาแน่นพร้อมข้อเสนอแนะความเกี่ยวข้องแบบหลอก (Yu et al, 2021, CIKM, ANCE-PRF )
- คำติชมแบบ Pseudo-RELEVANCE สำหรับการเป็นตัวแทนหลายครั้งการดึงข้อมูลหนาแน่น (Wang et al., 2021, ICTIR, COLBERT-PRF )
- อันดับความหมายแบบแยกแยะสำหรับการดึงคำถาม (Cai et al., 2021, ICTIR, Densetrans )
- การเป็นตัวแทน decoupling สำหรับการดึงผ่านโดเมนเปิด (Wu et al., 2021, arxiv)
- ROCKETQAV2: วิธีการฝึกอบรมร่วมกันสำหรับการดึงเส้นทางหนาแน่นและการจัดอันดับใหม่ (Ren et al., 2021, EMNLP, ROCKETQAV2 )
- การฝึกอบรมแบบจำลองการดึงข้อมูลโดยใช้แคชเชิงลบ (Lindgren et al., 2021, Neurips)
- การฝึกอบรมหลายขั้นตอนที่มีความคมชัดเชิงลบที่ดีขึ้นสำหรับการดึงทางประสาท (Lu et al., 2021, EMNLP)
- การปรับปรุงการดึงขนาดใหญ่ที่ใช้การฝังผ่านการปรับปรุงฉลาก (Liu et al., 2021, EMNLP)
- การดึงลำดับชั้นหนาแน่นสำหรับคำถามแบบเปิดโดเมนตอบคำถาม (Liu et al., 2021, EMNLP)
- การแสดงเอกสารสองเม็ดที่ได้รับการปรับปรุงอย่างต่อเนื่องสำหรับการดึงที่ปรับขนาดได้ตามการดึงที่ปรับขนาดได้ (Xiao er al., 2022, www)
- LED: Retriever หนาแน่นของพจนานุกรมที่มีความหนาแน่นสำหรับการดึงขนาดใหญ่ (Zhang et al., 2023, www)
- aggretriever: วิธีง่ายๆในการรวมการเป็นตัวแทนข้อความสำหรับการดึงข้อความหนาแน่นที่แข็งแกร่ง (Lin et al., 2022, arxiv)
- การเรียนรู้ที่แตกต่างจากประโยคสำหรับการดึงข้อความแบบเปิดโดเมน (Wu et al., 2022, ACL)
- ความเชี่ยวชาญเฉพาะด้านสำหรับการดึงข้อมูลที่มีประสิทธิภาพและมีประสิทธิภาพสำหรับการตอบคำถามแบบเปิดโดเมน (Cheng et al., 2022, arxiv)
- การกลั่นความรู้
- การกลั่นความหนาแน่นของการจัดอันดับโดยใช้ครู ที่ มีคู่กันอย่างแน่น
- การกลั่นความรู้สำหรับบ็อตแชทแบบดึงมาอย่างรวดเร็ว (Tahami et al., 2020, Sigir)
- การกลั่นความรู้จากผู้อ่านไปยัง Retriever สำหรับการตอบคำถาม (Izacard et al., 2020, arxiv)
- Retriever เป็นเพียงตัวประมาณของผู้อ่านหรือไม่ (Yang et al., 2020, arxiv)
- การปรับปรุงรูปแบบการจัดอันดับเอกสาร bi-enchonder ที่มีสองอันดับและการกลั่นหลายครู (Choi et al., 2021, SIGIR, TRMD )
- การปรับปรุงแบบจำลองการจัดอันดับระบบประสาทที่มีประสิทธิภาพด้วยการกลั่นความรู้ข้ามสถาปัตยกรรม (Hofstätter et al., 2021, arxiv, การสูญเสียมาร์จิ้น-MSE )
- Twinbert: การกลั่นความรู้ไปยังแบบจำลอง Bert ที่บีบอัดแบบสองโครงสร้างสำหรับการดึงขนาดใหญ่ (Lu et al., 2022, arxiv)
- การเป็นตัวแทนหลายเวกเตอร์
- การดึงย่อหน้าหลายย่อหน้าสำหรับคำถามแบบเปิดโดเมนตอบคำถาม (Feldman et al., 2019, ACL, Muppet )
- การเป็นตัวแทนที่กระจัดกระจายมีความหนาแน่นและตั้งใจสำหรับการดึงข้อความ (Luan et al., 2020, tacl, me-bert )
- Colbert: การค้นหาทางเดินที่มีประสิทธิภาพและมีประสิทธิภาพผ่านการโต้ตอบล่าช้าตามบริบทเหนือ Bert (Khattab et al., 2020, Sigir, Colbert )
- ขดลวด: ทบทวนการจับคู่คำศัพท์ที่แน่นอนในการดึงข้อมูลด้วยรายการคว่ำบริบท (Gao et al., 2021, NaCl, ขดลวด )
- การปรับปรุงการเป็นตัวแทนเอกสารโดยการสร้างแบบสอบถามแบบค้นหาหลอกสำหรับการดึงข้อมูลหนาแน่น (Tang et al., 2021, ACL)
- การดึงวลีเรียนรู้การดึงข้อความเช่นกัน (Lee et al., 2021, EMNLP, Densephrases )
- Query Embedding การตัดแต่งกิ่งสำหรับการดึงข้อมูลหนาแน่น (Tonellotto et al., 2021, CIKM)
- การแสดงเอกสารหลายมุมมองการเรียนรู้สำหรับการดึงข้อมูลแบบเปิดโดเมน (Zhang et al., 2022, ACL)
- COLBERTV2: การดึงข้อมูลที่มีประสิทธิภาพและมีประสิทธิภาพผ่านการโต้ตอบปลายน้ำหนักเบา (Santhanam, 2022, NAACL)
- การเรียนรู้การเป็นตัวแทนเอกสารที่หลากหลายด้วยการโต้ตอบแบบสอบถามลึกสำหรับการดึงข้อมูลหนาแน่น (li et al., 2022, arxiv)
- รูปแบบการแสดงข้อความตามหัวข้อสำหรับการดึงเอกสาร (Du et al., 2022, ICANN)
- เร่งโมเดลที่อิงกับปฏิสัมพันธ์
- การรวมสมมติฐานการสอบถามระยะเวลาการสืบค้นสำหรับการดึงและการจัดอันดับที่มีประสิทธิภาพโดยใช้เครือข่ายประสาทลึก (Mitra et al., 2019, arxiv)
- การจัดอันดับระบบประสาทตามปฏิสัมพันธ์ที่มีประสิทธิภาพด้วยการแฮชที่ไวต่อท้องถิ่น (ji et al., 2019, www)
- Poly-encoders: สถาปัตยกรรมและกลยุทธ์การฝึกอบรมก่อนการให้คะแนนแบบหลายประโยคที่รวดเร็วและแม่นยำ (Humeau et al., 2020, ICLR, โพลี-เข้ารหัส )
- เฟรมเวิร์ ก การจัดอันดับที่ใช้โมดูลาร์
- เอกสารที่มีประสิทธิภาพการจัดอันดับใหม่สำหรับหม้อแปลงโดยการเป็นตัวแทนคำที่กำหนดไว้ล่วงหน้า (Macavaney et al., 2020, Sigir, Prettr )
- deformer: การย่อยสลายหม้อแปลงที่ผ่านการฝึกอบรมมาก่อนสำหรับคำถามที่ตอบคำถามเร็วขึ้น (Cao et al., 2020, ACL, DEFOFORER )
- Sparta: การตอบคำถามแบบเปิดโดเมนที่มีประสิทธิภาพผ่านการดึงหม้อแปลงแบบเบาบาง (Zhao et al., 2020, arxiv, Sparta )
- Conformer-Kernel พร้อมคำสั่งการสืบค้นสำหรับการดึงเอกสาร (Mitra et al., 2020, arxiv)
- Inttower: รุ่น Two-Tower รุ่นต่อไปสำหรับระบบการจัดอันดับก่อน (Li et al., 2022, CIKM)
- การฝึกอบรมล่วงหน้า
- การดึงข้อมูลแฝงสำหรับการตอบคำถามโดเมนแบบเปิดอย่างอ่อนระบบตอบคำถาม (Lee et al., 2019, ACL, ORQA )
- รูปแบบภาษาที่เรียกคืนก่อนการฝึกอบรม (Guu et al., 2020, ICML, Realm )
- งานฝึกอบรมล่วงหน้าสำหรับการดึงขนาดใหญ่ที่ใช้ในการฝัง (Chang et al., 2020, ICLR, BFS+WLP+MLM )
- รูปแบบภาษาของคุณพร้อมสำหรับการปรับแต่งความหนาแน่นหรือไม่ (Gao et al., 2021, EMNLP, คอนเดนเซอร์ )
- คลังข้อมูลที่ไม่ได้รับการดูแลแบบจำลองการฝึกอบรมล่วงหน้าสำหรับการดึงเส้นทางหนาแน่น (Gao et al., 2021, arxiv, cocondenser )
- น้อยกว่ามาก: การฝึกอบรมก่อนการเข้ารหัสสยามสยามที่แข็งแกร่งโดยใช้ตัวถอดรหัสที่อ่อนแอ (Lu et al., 2021, EMNLP, seed-encoder )
- รูปแบบภาษาที่ผ่านการฝึกอบรมมาล่วงหน้าสำหรับการดึงข้อมูลเว็บในการค้นหา Baidu (Liu et al., 2021, KDD)
- การฝึกอบรมล่วงหน้าสำหรับการดึงข้อมูลแบบ Ad-Hoc: การเชื่อมโยงหลายมิติก็คือคุณต้องใช้ (Ma Ma et al., 2021, CIKM, HARP )
- Pre-train ตัวเข้ารหัสข้อความที่เลือกปฏิบัติสำหรับการดึงข้อมูลหนาแน่นผ่านการทำนายช่วงความคมชัด (Ma et al., 2022, Sigir)
- TSDAE: การใช้การเข้ารหัสอัตโนมัติตามลำดับหม้อแปลงสำหรับการเข้ารหัสอัตโนมัติสำหรับการเรียนรู้ประโยคที่ไม่ได้รับการดูแล
- MASK Auto-encoder สำหรับการดึงข้อความหนาแน่น (Wu et al., 2022, arxiv)
- SIMLM: การฝึกอบรมล่วงหน้าด้วยคอขวดที่เป็นตัวแทนสำหรับการดึงเส้นทางหนาแน่น (Wang et al., 2022, arxiv)
- Lexmae: การเตรียมการพจนานุกรมพจนานุกรมสำหรับการดึงขนาดใหญ่ (Shen et al., 2022, arxiv)
- วิธีการฝึกอบรมล่วงหน้าแบบตัดกันเพื่อเรียนรู้การเลือกปฏิบัติอัตโนมัติสำหรับการดึงข้อมูลหนาแน่น (Ma et al., 2022, CIKM)
- retromae: แบบจำลองภาษาที่มุ่งเน้นการดึงข้อมูลล่วงหน้าผ่านการเข้ารหัสอัตโนมัติที่สวมหน้ากาก (Xiao และ Liu et al., 2022, EMNLP)
- แบบจำลองการใช้ภาษาที่ใช้ในการดึงข้อมูลแบบดึงข้อมูลสำหรับการดึงเส้นทางหนาแน่น (Long et al., 2022, arxiv)
- LaPrador: รีทรีฟ์หนาแน่นที่ไม่ได้รับการดูแลเป็นศูนย์สำหรับการดึงข้อความแบบไม่มีการยิง (Xu et al., 2022, ACL)
- Masked autoencoders ในฐานะผู้เรียนที่รวมเป็นหนึ่งสำหรับการเป็นตัวแทนประโยคที่ผ่านการฝึกอบรมมาก่อน (Liu et al., 2022, arxiv)
- Master: Multi-Task ที่ผ่านการฝึกอบรมมาแล้วที่ได้รับการฝึกฝนมาส
- COT-MAE V2: การเข้ารหัสอัตโนมัติแบบสวมหน้ากากตามบริบทพร้อมการสร้างแบบจำลองหลายมุมมองสำหรับการดึงข้อความ (Wu et al., 2023, arxiv)
- COT-MOTE: การสำรวจบริบท Masked Auto-Encoder Pre-Training ด้วยการผสมผสานระหว่าง Experts แบบผสมผสานสำหรับการดึงข้อความ (Ma et al., 2023, arxiv)
- การเรียนรู้ร่วมกับดัชนี
- การเรียนรู้ร่วมกันของแบบจำลองการดึงข้อมูลเชิงลึกและดัชนีการฝังเชิงปริมาณเชิงปริมาณ (Zhang et al., 2021, Sigir, Poeem )
- การเพิ่มประสิทธิภาพการเข้ารหัสแบบสอบถามและการหาปริมาณผลิตภัณฑ์เพื่อปรับปรุงประสิทธิภาพการดึง (Zhan et al., 2021, CIKM, JPQ )
- การจับคู่ผลิตภัณฑ์ที่มุ่งเน้นการจับคู่สำหรับการดึงข้อมูล ad-hoc (Xiao et al., 2021, EMNLP, MOPQ )
- การเรียนรู้การเป็นตัวแทนที่ไม่ต่อเนื่องผ่านการจัดกลุ่มแบบ จำกัด เพื่อการดึงข้อมูลที่มีประสิทธิภาพและมีประสิทธิภาพ (Zhan et al, 2022, WSDM, RepConc )
- การเรียนรู้ร่วมกับ Ranker
- การฝึกอบรมแบบ end-to-end ของการดึงประสาทสำหรับคำถามแบบเปิดโดเมน (Sachan et al., 2021, ACL)
- ฝ่ายตรงข้าม Retriever-Ranker สำหรับการดึงข้อความหนาแน่น (Zhang et al., 2022, ICLR)
- debias
- การเรียนรู้แบบจำลองการดึงข้อมูลหนาแน่นที่แข็งแกร่งจากฉลากความเกี่ยวข้องที่ไม่สมบูรณ์ (Prakash et al., 2021, Sigir, Rance )
- เชิงลบอย่างหนักหรือเชิงลบที่ผิดพลาด: การแก้ไขอคติในการฝึกอบรมแบบจำลองการจัดอันดับระบบประสาท (Cai et al., 2022, CIKM)
- Simans: การสุ่มตัวอย่างเชิงลบที่คลุมเครืออย่างง่ายสำหรับการดึงข้อความหนาแน่น (Zhou et al., 2022, EMNLP)
- การเรียนรู้ที่แตกต่างของการเป็นตัวแทนประโยคที่ไม่ได้รับการดูแล (Zhou et al., 2022, ACL)
- การกู้คืนทองคำจากหาดทรายสีดำ: การดึงข้อความที่มีความหนาแน่นหลายภาษาด้วยตัวอย่างเชิงลบที่ยากและเท็จ (Shen et al., 2022, EMNLP)
- zero-shot/ไม่กี่นัด
- การดึงการดึงแบบศูนย์การช็อตผ่านการสร้างแบบสอบถาม (Liang et al., 2020, arxiv)
- การเรียกคืนระบบประสาทแบบไม่มีการยิงผ่านการสร้างคำถามสังเคราะห์ที่กำหนดเป้าหมายโดเมน (Ma et al., 2020, qgen , arxiv)
- ไปสู่แบบจำลองการดึงประสาทที่แข็งแกร่งด้วยการฝึกอบรมก่อนการสังเคราะห์ (Reddy et al., 2021, arxiv)
- Beir: เกณฑ์มาตรฐานที่แตกต่างกันสำหรับการประเมินผลแบบไม่มีการยิงของแบบจำลองการดึงข้อมูล (Thakur et al., 2021, Neurips)
- การ ดึง ข้อมูลหนาแน่นเป็นศูนย์ด้วยการเป็นตัวแทนของการเป็นตัวแทนของโดเมนที่ไม่ได้ใช้งาน
- ตัวเข้ารหัสคู่ขนาดใหญ่เป็นตัวดึงข้อมูลทั่วไป (Ni et al., 2022, EMNLP, DTR )
- ความหมายนอกโดเมนเพื่อช่วยเหลือ! โมเดลการดึงไฮบริด Zero-shot (Chen et al., 2022, ECIR)
- Inpars: การเพิ่มข้อมูลสำหรับการดึงข้อมูลโดยใช้แบบจำลองภาษาขนาดใหญ่ (Bonifacio et al., 2022, arxiv)
- สู่การดึงข้อมูลหนาแน่นที่ไม่ได้รับการดูแลด้วยการเรียนรู้แบบตัดกัน (Izacard et al., 2021, arxiv, contiever )
- GPL: การติดฉลากหลอกแบบกำเนิดสำหรับการปรับโดเมนที่ไม่ได้รับการดูแลของการดึงข้อมูลหนาแน่น (Wang et al., 2022, NAACL)
- การเรียนรู้ที่จะดึงข้อความโดยไม่มีการกำกับดูแล (Ram et al., 2021, arxiv, Spider )
- การตรวจสอบอย่างละเอียดเกี่ยวกับการดึงข้อมูลหนาแน่นเป็นศูนย์ (ren et al., 2022, arxiv)
- ข้อความและรหัสฝังตัวโดยการฝึกอบรมก่อนการฝึกอบรม (Neelakantan และคณะ, 2022, arxiv)
- การสร้างแบบจำลองโดเมนและความเกี่ยวข้องสำหรับการดึงความหนาแน่นที่ปรับได้ (Zhan et al., 2022, arxiv)
- PreftingAgator: การดึงข้อมูลหนาแน่นไม่กี่ครั้งจาก 8 ตัวอย่าง (Dai et al., 2022, arxiv)
- คำถามคือทั้งหมดที่คุณต้องฝึกอบรมทางเดินที่หนาแน่น (Sachan et al., 2022, tacl)
- Hyper: การฝึกอบรมแบบมัลติทาสก์ไฮเปอร์ที่ได้รับการฝึกอบรมช่วยให้การดึงข้อมูลทั่วไปขนาดใหญ่ (Cai et al., 2023, ICLR)
- COCO-DR: การต่อสู้การกระจายการเปลี่ยนแปลงในการดึงข้อมูลหนาแน่นเป็นศูนย์ด้วยการเรียนรู้ที่ตรงกันข้าม
- ความท้าทายในการวางนัยทั่วไปในการตอบคำถามโดเมนแบบเปิด (Liu et al., 2022, NAACL)
- ความทนทาน
- สู่การดึงข้อมูลหนาแน่นที่แข็งแกร่งผ่านการจัดอันดับท้องถิ่น (Chen et al., 2022, IJCAI)
- การจัดการกับการพิมพ์ผิดสำหรับการดึงข้อความและการจัดอันดับที่ใช้ Bert (Zhuang et al., 2021, EMNLP)
- การประเมินความทนทานของท่อเรียกคืนด้วยเครื่องกำเนิดความแปรปรวนแบบสอบถาม (Penha et al., 2022, ECIR)
- การวิเคราะห์ความทนทานของตัวเข้ารหัสคู่สำหรับการดึงข้อมูลหนาแน่นต่อการสะกดผิด (Sidiropoulos et al., 2022, Sigir)
- ตัวละครและการสอนตัวเองเพื่อปรับปรุงความทนทานของการดึงข้อมูลหนาแน่นในการสอบถามด้วยการพิมพ์ผิด (Zhuang et al., 2022, Sigir)
- Bert Rankers มีความเปราะบาง: การศึกษาโดยใช้การก่อกวนเอกสารที่เป็นปฏิปักษ์ (Wang et al., 2022, ICTIR)
- คำสั่งซื้อ: การเลียนแบบการโจมตีที่เป็นปฏิปักษ์ต่อแบล็กบ็อกซ์โมเดลการจัดอันดับระบบประสาท blackbox (Liu et al., 2022, arxiv)
- Pre-training Pre-Training สำหรับการดึงข้อมูลที่มีความหนาแน่นสูง (Zhuang et al., 2023, arxiv)
- การวิเคราะห์การตรวจสอบ
- คำสาปของการดึงข้อมูลมิติต่ำหนาแน่นสำหรับดัชนีขนาดใหญ่ (Reimers et al., 2021, ACL)
- การกำจัดความซ้ำซ้อนที่ไม่ได้รับการสนับสนุนอย่างง่ายและมีประสิทธิภาพในการบีบอัดเวกเตอร์หนาแน่นสำหรับการดึงเส้นทาง (Ma et al., Emnlp, 2021, ซ้ำซ้อน )
- Beir: เกณฑ์มาตรฐานที่แตกต่างกันสำหรับการประเมินผลแบบไม่มีการยิงของแบบจำลองการดึงข้อมูล (Thakur et al., 2021, Neurips, การถ่ายโอน )
- วลีสำคัญตระหนักถึงการดึงข้อมูลหนาแน่น: ผู้แก้ไขความหนาแน่นสามารถเลียนแบบหนึ่งได้หรือไม่ (Chen et al., 2021, arxiv)
- คำถามที่เป็นศูนย์กลางอย่างง่าย ๆ ท้าทายผู้ติดตามความหนาแน่น (Sciavolino et al., 2021, EMNLP)
- การตีความการดึงข้อมูลหนาแน่นเป็นส่วนผสมของหัวข้อ (Zhan et al., 2021, arxiv)
- การวิเคราะห์แหล่งที่มาของตัวเข้ารหัสสำหรับการรีทรีเออร์ที่มีความหนาแน่น
- การเป็นตัวแทน isotropic สามารถปรับปรุงการดึงข้อมูลหนาแน่น (Jung et al., 2022, arxiv)
- การเรียนรู้อย่างรวดเร็ว
- รูปแบบการจัดอันดับระบบประสาทแบบกึ่งเซียวโซมาสโดยใช้การปรับแต่งน้ำหนักเบา (Jung et al., 2022, www)
- กระจัดกระจายหรือเชื่อมต่อ? วิธีการปรับแต่งพารามิเตอร์ที่มีประสิทธิภาพที่ดีที่สุดสำหรับการดึงข้อมูล (Ma et al., 2022, CIKM)
- DPTDR: การปรับแต่งอย่างลึกซึ้งสำหรับการดึงเส้นทางหนาแน่น (Tang et al., 2022, arxiv)
- การปรับแต่งพารามิเตอร์-ef fi cient ทำให้การดึงข้อความทางประสาททั่วไปและสอบเทียบ (Tam et al., 2022, arxiv)
- NIR-PROMPT: กรอบการฝึกอบรมการดึงข้อมูลทั่วไปแบบทั่วไปที่ทำงานร่วมกัน (Xu et al., 2022, arxiv)
- แบบจำลองภาษาขนาดใหญ่สำหรับการดึงข้อมูล
- การดึงข้อมูลหนาแน่นเป็นศูนย์อย่างแม่นยำโดยไม่มีฉลากที่เกี่ยวข้อง (Gao et al., 2022, arxiv)
- คนอื่น
- HLATR: ปรับปรุงการดึงข้อความหลายขั้นตอนด้วยรายการไฮบริดรับรู้การเปลี่ยนเส้นทางการวิ่งซ้ำ (Zhang et al., 2022, arxiv)
- ASYNCVAL: ชุดเครื่องมือสำหรับการตรวจสอบจุดตรวจสอบความหนาแน่นแบบอะซิงโครนัสในระหว่างการฝึกอบรม (Zhuang et al., 2022, Sigir)
วิธีการดึงแบบไฮบริด
- อิงตามคำศัพท์
- โมเดลการดึงข้อมูลแบบ monolingual และ cross-lingual โดยใช้คำว่าการฝังคำ (สองภาษา) (Vulic et al., 2015, Sigir, การรวมเชิงเส้น )
- แบบจำลองภาษาทั่วไปที่ใช้การฝังคำสำหรับการดึงข้อมูล (Ganguly et al., 2015, Sigir, GLM )
- เป็นตัวแทนของเอกสารและการสืบค้นเป็นชุดของคำที่ฝังตัวของเวกเตอร์สำหรับการดึงข้อมูล (Roy et al., 2016, Sigir, Linearly Combine )
- โมเดลพื้นที่ฝังตัวคู่สำหรับการจัดอันดับเอกสาร (Mitra et al., 2016, WWW, DESM_MIXTURE , การรวมเชิงเส้น ))
- ปิดเส้นทางที่ถูกตี: ลองแทนที่การดึงข้อมูลตามคำศัพท์ด้วยการค้นหา K-NN (Boytsov et al., 2016, CIKM, BM25+รูปแบบการแปล )
- การเรียนรู้การเป็นตัวแทนไฮบริดเพื่อดึงคำถามที่เทียบเท่ากับความหมาย (Santos et al., 2015, ACL, Bow-CNN )
- คำถามแบบเปิดโดเมนแบบเรียลไทม์ตอบด้วยดัชนีวลีหนาแน่น (Seo et al., 2019, ACL, Denspi )
- การเป็นตัวแทนแบบเบาบางตามบริบทสำหรับคำถามแบบเปิดโดเมนแบบเรียลไทม์ (Lee et al., 2020, ACL, SPARC )
- Cort: การจัดอันดับเสริมจาก Transformers (Wrzalik et al., 2020, NAACL, Cort_BM25 )
- การเป็นตัวแทนที่กระจัดกระจายหนาแน่นและตั้งใจสำหรับการดึงข้อความ (Luan et al., 2020, TaCl, ME-HYBRID )
- เติมเต็มรูปแบบการดึงคำศัพท์ด้วยการฝังตัวที่เหลืออยู่ (Gao et al., 2020, ECIR, Clear )
- ใช้ประโยชน์จากการจับคู่ความหมายและคำศัพท์เพื่อปรับปรุงการเรียกคืนระบบดึงเอกสาร: วิธีการไฮบริด (Kuzi et al., 2020, arxiv, ไฮบริด )
- บันทึกย่อสั้น ๆ เกี่ยวกับ DeepImpact, ขดลวดและกรอบแนวคิดสำหรับเทคนิคการดึงข้อมูล (Lin Lin et al., 2021, arxiv, unicoil )
- ถ่วงน้ำหนักแบบออฟไลน์แบบออฟไลน์ตามบริบทสำหรับการดึงประสาทที่มีประสิทธิภาพและมีประสิทธิภาพ (Chen et al., 2021, Sigir)
- การทำนายประสิทธิภาพ/ประสิทธิผลการแลกเปลี่ยนสำหรับการเลือกกลยุทธ์การดึงข้อมูลที่หนาแน่นและเบาบาง (Arabzadeh et al., 2021, CIKM)
- ดัชนีไปข้างหน้าอย่างรวดเร็วสำหรับการจัดอันดับเอกสารที่มีประสิทธิภาพ (Leonhardt et al., 2021, arxiv)
- การเป็นตัวแทนแบบเบาบางสำหรับการดึงข้อความโดยการแบ่งเป็นตัวแทน (Lin et al., 2021, arxiv)
- Uni fi er: retriever uni fi ed สำหรับการดึงขนาดใหญ่ (Shen et al., 2022, arxiv)
ทรัพยากรอื่น ๆ
งานอื่น ๆ
- การค้นหาอีคอมเมิร์ซ
- เครือข่ายที่น่าสนใจลึกสำหรับการทำนายอัตราการคลิกผ่าน (Zhou et al., 2018, KDD, DIN )
- ตั้งแต่การดึงความหมายไปจนถึงการจัดอันดับคู่: การเรียนรู้อย่างลึกซึ้งในการค้นหาอีคอมเมิร์ซ (Li et al., 2019, Sigir, Jingdong)
- เครือข่ายหลายดอกเบี้ยพร้อมการกำหนดเส้นทางแบบไดนามิกสำหรับคำแนะนำที่ Tmall (li et al., 2019, cikm, mind , tmall)
- สู่การดึงข้อมูลส่วนบุคคลและความหมาย: โซลูชันแบบ end-to-end สำหรับการค้นหาอีคอมเมิร์ซผ่านการฝังการเรียนรู้แบบฝัง (Zhang et al., 2020, Sigir, DPSR , Jingdong)
- เครือข่ายหลายดอกเบี้ยที่ลึกสำหรับการทำนายอัตราการคลิกผ่าน (Xiao et al., 2020, CIKM, DMIN )
- การดึงข้อมูลลึก: โมเดลโครงสร้างที่เรียนรู้แบบ end-to-end สำหรับคำแนะนำขนาดใหญ่ (Gao et al., 2020, arxiv)
- การดึงผลิตภัณฑ์แบบฝังในการค้นหา Taobao (Li et al., 2021, KDD, Taobao)
- การรวบรวมโครงสร้างในข้อมูลสำหรับการค้นหาผลิตภัณฑ์ความหมายหลายพันล้านครั้ง (Lakshman et al., 2021, arxiv, Amazon)
- การค้นหาที่ได้รับการสนับสนุน
- Mobius: ไปสู่การจับคู่แบบสอบถามรุ่นต่อไปในการค้นหาที่ได้รับการสนับสนุนจาก Baidu (Fan Fan et al., 2019, KDD, Baidu)
- การดึงภาพ
- เครือข่ายระบบประสาทไบนารีสำหรับการดึงภาพ (Zhang et al., 2021, Sigir, Bnnh )
- การแฮชแบบปรับตัวเองลึกสำหรับการดึงภาพ (Lin et al., 2021, CIKM, DSAH )
- รายงานการประชุมเชิงปฏิบัติการ Hipstir ครั้งแรกเกี่ยวกับอนาคตของการดึงข้อมูล (Dietz et al., 2019, Sigir, Workshop)
- มาวัดเวลาทำงานกันเถอะ! การขยายโครงสร้างพื้นฐานการจำลองแบบ IR เพื่อรวมถึงด้านประสิทธิภาพ (Hofstätter et al., 2019, Sigir)
- การค้นพบแบบฝังใน Facebook Search (Huang et al., 2020, KDD, EBR )
- การเรียนรู้รหัสไม่ต่อเนื่อง K-Way D-dimensional สำหรับการเป็นตัวแทนการฝังตัวขนาดกะทัดรัด (Chen et al., 2018, ICML)
ชุดข้อมูล
- 【 MS Marco 】 MS Marco: ชุดข้อมูลความเข้าใจในการอ่านของเครื่องจักรมนุษย์ที่สร้างขึ้น
- 【 TREC Car 】 TREC Complex คำตอบภาพรวมการดึงข้อมูล
- 【 TREC DL 】ภาพรวมของ TREC 2019 Deep Learning Track
- 【 trec covid 】 trec-covid: การสร้างคอลเลกชันการทดสอบการดึงข้อมูลการระบาด
วิธีการจัดทำดัชนี
- เกี่ยวกับต้นไม้
- ต้นไม้ค้นหาไบนารีหลายมิติที่ใช้สำหรับการค้นหาแบบเชื่อมโยง (1975, KD Tree )
- รบกวน
- ที่ใช้แฮช
- เพื่อนบ้านที่ใกล้ที่สุดโดยประมาณ: เพื่อลบคำสาปของมิติ (1998, LSH )
- ตามปริมาณ
- ปริมาณผลิตภัณฑ์สำหรับการค้นหาเพื่อนบ้านที่ใกล้ที่สุด (2010, PQ )
- ปริมาณผลิตภัณฑ์ที่ดีที่สุด (2013, OPQ )
- อิงกับกราฟ
- การนำทางในโลกเล็ก ๆ (2000, NSW )
- การค้นหาเพื่อนบ้านที่ใกล้ที่สุดที่มีประสิทธิภาพและมีประสิทธิภาพโดยประมาณโดยใช้กราฟโลกขนาดเล็กที่นำทางได้ตามลำดับชั้น (2018, HNSW )
- ชุดเครื่องมือ
- FAISS: ห้องสมุดสำหรับการค้นหาความคล้ายคลึงกันอย่างมีประสิทธิภาพและการจัดกลุ่มของเวกเตอร์หนาแน่น
- Sptag: ห้องสมุดสำหรับการค้นหาเพื่อนบ้านที่ใกล้ที่สุดโดยประมาณที่รวดเร็ว
- OpenMatch: แพ็คเกจโอเพนซอร์ซสำหรับการดึงข้อมูล
- Pyserini: ชุดเครื่องมือ Python สำหรับการวิจัยการดึงข้อมูลที่ทำซ้ำได้ด้วยการเป็นตัวแทนที่กระจัดกระจายและหนาแน่น
- Elasticsearch


