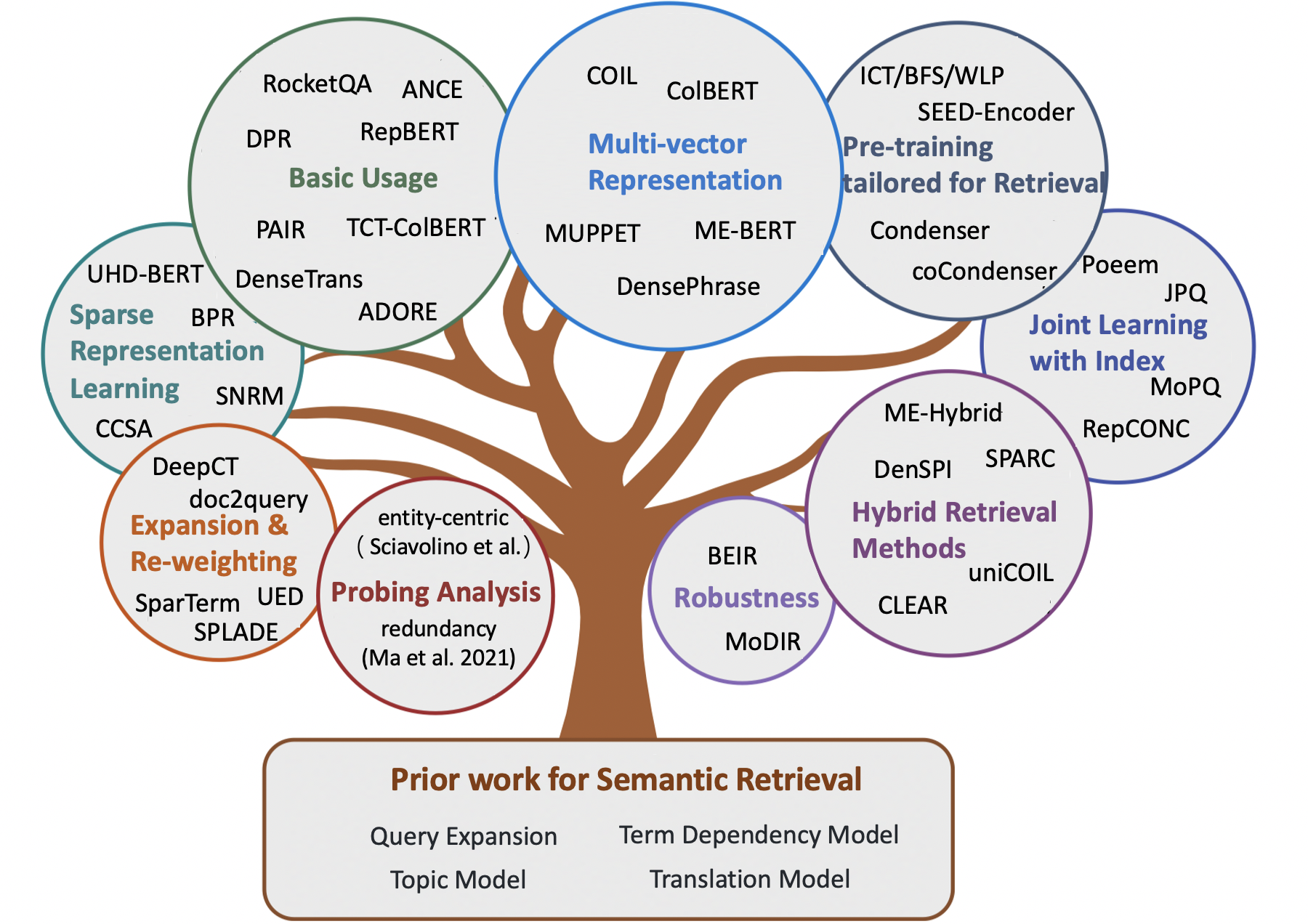
Tolle semantische Modelle für das Abrufen der ersten Stufe
Notiz:
- Eine kuratierte Liste großartiger Artikel zum semantischen Abrufen , darunter einige frühe Methoden und jüngste neuronale Modelle für Informationsabrufaufgaben (z.
- Für Forscher, die semantische Modelle für die Wiederaufnahme von Stadien erwerben möchten, verweisen wir die Leser an die Awesome Neuir-Umfrage von Guo ET.al.
- Jedes Feedback und Beitrag sind willkommen. Bitte öffnen Sie ein Problem oder kontaktieren Sie mich.
Inhalt
- Vermessungspapier
- Kapitel 1: Klassikalisches Abruf basierend
- Kapitel 2: Frühe Methoden zum semantischen Abrufen
- Abfragebehandlung
- Dokumentausweiterung
- Begriffsabhängigkeitsmodell
- Themenmodell
- Übersetzungsmodell
- Kapitel 3: Neuronale Methoden für das semantische Abruf
- Spärliche Abrufmethoden
- Dichte Abrufmethoden
- Hybrid -Abrufmethoden
- Kapitel 4: Andere Ressourcen
- Andere Aufgaben
- Datensätze
- Indizierungsmethoden
Vermessungspapier
- Semantische Übereinstimmung in der Suche (Li et al., 2014)
- Vorbereitete Transformatoren für Textranking: Bert und Beyond (Lin et al., 2021, Arxiv)
- Semantische Modelle für das Abrufen der ersten Stufe: Eine umfassende Übersicht (Guo et al., 2021, tois)

- Ein vorgeschlagener konzeptioneller Rahmen für einen Repräsentationsansatz zum Abrufen von Informationen (Lin et al., 2021, Arxiv)
- Pre-Training-Methoden im Informationsabruf (Fan et al., 2022, Arxiv)
- Dichte Textabruf basierend auf vorbereiteten Sprachmodellen: Eine Umfrage (Zhao et al., 2022, Arxiv)
- Niedrigressourcen-dichte Wiederholung für die Beantwortung von Fragen zur Beantwortung von Open-Domänen: Eine umfassende Umfrage (Shen et al., 2022, Arxiv)
- Vorlesungen zum Abrufen neuronaler Informationen (Tonellotto et al., 2022, Arxiv)
Klassiker emrembasiertes Abruf
- Ein Vektorraummodell für die automatische Indexierung (1975, VSM )
- Entwicklungen im automatischen Textabruf (1991, tfidf )
- Termgewichtsansätze im automatischen Textabruf (1988, tfidf )
- Relevanzgewichtung der Suchbegriffe (1976, BIM )
- Eine theoretische Grundlage für die Verwendung von Co-Occurrence-Daten im Informationsabruf (1997, Baumabhängigkeitsmodell )
- Das probabilistische Relevanz -Rahmen: BM25 und darüber hinaus (2010, BM25 )
- Ein Sprachmodellierungsansatz zum Abrufen von Informationen (1998, ql )
- Statistische Sprachmodelle zum Abrufen von Informationen (2007, LM für Ir )
- Hypergeometrisches Sprachmodell und zipf-ähnliche Bewertungsfunktion für das Abrufen von Webdokumenten Ähnlichkeit (2010, LM für Ir )
- Probabilistische Modelle des Informationsabrufs basierend auf der Messung der Divergenz von Zufälligkeit (2002, DFR )
Frühe Methoden zum semantischen Abrufen
Abfragebehandlung
- Globales Modell
- Wortwortverbände in Dokumentenabrufsystemen (1969)
- Konzeptbasierte Abfrageerweiterung (1993)
- Abfrageerweiterung mit lexikalisch-semantischen Beziehungen (1994)
- Verwenden von Abfragebegluchen im Informationsabruf (2007)
- Lokales Modell
- Relevanz -Feedback zum Abruf von Informationen (1971, Rocchio PRF )
- Modellbasiertes Feedback im Sprachmodellierungsansatz zum Abrufen von Informationen (2001, Divergence-Minimierungsmodell )
- UMass bei TREC 2004: Neuheit und hart (2004, RM3 für PRF )
- Auswählen guter Expansionsbegriffe für Pseudo-Relevance-Feedback (2008, PRF)
- Eine vergleichende Untersuchung von Methoden zur Schätzung von Abfragsprachmodellen mit Pseudo -Feedback (2009)
- Pseudo-Relevanz-Feedback basierend auf der Matrixfaktorisierung (2016)
- Reduzierung des Risikos einer Abfrageerweiterung durch robuste eingeschränkte Optimierung (2009 , Problem mit Abfrage -Drift )
- Abfrageerweiterung unter Verwendung der lokalen und globalen Dokumentenanalyse (2017)
Dokumentausweiterung
- Korpusstruktur, Sprachmodelle und Ad -hoc -Informationen Abruf (2004)
- Cluster-basiertes Abruf unter Verwendung von Sprachmodellen (2004)
- Abrufen von Sprachmodellinformationen mit Dokumentenerweiterung (2006)
- Dokumenterweiterung basierend auf WordNet für robustes ir (2010)
- Verbesserung des Abrufs von kurzen Texten durch Dokumentenerweiterung (2012)
- Dokumentenerweiterung mit externen Sammlungen (2017, WordNet-basiert )
- Expansion von Dokumenten gegen Abfrage für das Ad-hoc-Abruf (2005)
Begriffsabhängigkeitsmodell
- Experimente zur automatischen Phrase-Indexierung zum Abrufen von Dokumenten: Ein Vergleich der syntaktischen und nicht syntaktischen Methoden (1987, VSM + Term Dependent )
- Termgewichtsansätze in automatischer Textabnahme (1988, VSM + Begriffsabhängigkeit )
- Eine Analyse statistischer und syntaktischer Phrasen (1997, VSM + Term Dependent )
- Ein probabilistisches Modell des Informationsabrufs: Entwicklung und vergleichende Experimente (2000, VSM + Termabhängigkeit )
- Relevanzranking mit Kernel (2010, BM25 + Begriffsabhängigkeit )
- Ein allgemeines Sprachmodell zum Abrufen von Informationen (1999, LM + Begriff Abhängigkeit )
- Bitm -Sprachmodelle für das Abrufen von Dokumenten (2002, LM + Begriff Abhängigkeit )
- Erfassen von Begriffsabhängigkeiten unter Verwendung eines Sprachmodells basierend auf Satzbäumen (2002, LM + Begriffsabhängigkeit )
- Abhängigkeitssprachmodell zum Abrufen von Informationen (2004, LM + Begriff Abhängigkeit )
- Eine generative Relevanztheorie (2008)
- Ein Markov -Zufallsfeldmodell für Termabhängigkeiten (2005, SDM )
Themenmodell
- Generalisiertes Vektorraummodell im Informationsabruf (1985, GVSM )
- Indexierung durch latente semantische Analyse (1990, LSI für Ir )
- Probabilistische latente semantische Indexierung (2017, PLSA, linear kombinieren )
- Korpusstruktur, Sprachmodelle und Ad -hoc -Informationen Abrufen (2004, Glättung )
- Regularisierung von Ad -hoc -Abrufwerten regulieren (2005, Glättung )
- LDA-basierte Dokumentmodelle für Ad-hoc-Abruf (2006, LDA für IR und LDA für LM Glättung )
- Eine vergleichende Studie zur Verwendung von Themenmodellen zum Abrufen von Informationen (2009, Glättung )
- Untersuchung der Aufgabenleistung probabilistischer Themenmodelle: Eine empirische Studie von PLSA und LDA (2010)
- Latente semantische Indexierung (LSI) fällt für TREC -Sammlungen aus (2011)
Übersetzungsmodell
- Informationsabruf als statistische Übersetzung (1999)
- Schätzung statistischer Übersetzungsmodelle basierend auf gegenseitigen Informationen zum Abrufen von Ad -hoc -Informationen (2010)
- Klick-basierte Übersetzungsmodelle für Websuche: Von Wortmodellen zu Phrasenmodellen (2010)
- Axiomatische Analyse des Übersetzungssprachmodells zum Abrufen von Informationen (2012)
- Umschreibung von Abfragen mit monolingual statistischer maschineller Übersetzung (2010 für Abfrageerweiterung )
- Auf konzeptbasierten Übersetzungsmodellen, die Suchprotokolle für die Abfrageerweiterung verwenden (2012, für die Abfrageerweiterung )
Neuronale Methoden für das semantische Abruf
Spärliche Abrufmethoden
- Begriff Wiederbelebung
- Lernen, Begriffe mit verteilten Darstellungen neu zu gewichten (Zheng et al., 2015, Sigir, Deeptr )
- Integration und Bewertung neuronaler Worteinbettungen in das Informationsabruf (Zuccon et al., 2015, ADCS, NTLM )
- Lernbegriff Diskriminierung (Frej et al., 2020, Sigir, TDV )
- Kontextbewusster Satz/Passage Begriff Wichtigkeitsschätzung für den Abruf der ersten Stufe (Dai et al., 2019, Arxiv, Deepct )
- Kontextbewusster Begriff Gewichtung für die Abholung der ersten Stufe (Dai et al., 2020, Sigir, Deepct )
- Effizienz Implikationen der Termgewichtung für die Durchgangsabnahme (Mackenzie et al., 2020, Sigir, Deepct )
- Kontextbewusstes Dokumentbegriff für AD-hoc-Suche (Dai et al., 2020, www, hdct )
- Ein paar kurze Hinweise zu Deepimpact, Coil und einem konzeptionellen Rahmen für Informationsabruftechniken (Lin et al., 2021, Arxiv, Unicoil )
- Erweiterung
- Dokumentenerweiterung durch Abfragevorhersage (Nogueira et al., 2019, Arxiv, doc2query )
- Von Doc2Query nach DocttttTQuery (Nogueira et al., 2019, Arxiv, DoctttttQuery )
- Ein einheitlicher Vorab -Rahmen für die Durchgangsrangierung und -ausweitung (Yan et al., 2021, aaai, ued )
- Generation-Augmented Abruf für die Beantwortung von Open-Domain-Frage (Mao et al., 2020, ACL, GAR , Abfrageerweiterung )
- Expansion + Begriff Umgewichtung
- Expansion durch Vorhersage von Bedeutung mit der Kontextualisierung (Macavaney et al., 2020, Sigir, Epic )
- Sparterm: Lernbegriff basierte spärliche Darstellung für das schnelle Textabruf (Bai et al., 2020, Arxiv, Sparterm )
- Splade: Spärliches lexikalisches und Expansionsmodell für das Rang im ersten Stufe (Formal et al., 2021, Sigir, Splade )
- Splade V2: Spärliches lexikalisches und Expansionsmodell für Informationsabruf (Formal et al., 2021, Arxiv, Spladev2 )
- Lernpassage Auswirkungen auf umgekehrte Indizes (Mallia et al., 2021, Sigir, Deepimapct )
- Tilde: Begriff Independent Likelihood-Modell für die Durchgangsranierung (Zhuang et al., 2021, Sigir, Tilde )
- Schnellpassage-Ranging mit kontextualisiertem exakten Begriff Matching und effizienter Durchgangserweiterung (Zhuang et al., 2021, Arxiv, Tildev2 )
- Spade: Verbesserung der spärlichen Darstellungen mit einem doppelten Dokumentencodierer für den Abruf der ersten Stufe (Choi et al., 2022, Cikm)
- Spärmer Repräsentationslernen
- Semantisches Hashing (Salakhutdinov et al., 2009)
- Vom neuronalen Neuanlagen bis zum neuronalen Ranking: Erlernen einer spärlichen Darstellung für die invertierte Indexierung (Zamani et al., 2018, CIKM, SNRM )
- UHD-Bert: Eimered Ultra-hohe dimensionale spärliche Darstellungen für die vollständige Rangliste (Jang et al., 2021, Arxiv, Uhd-Bert )
- Effizite Durchgangsabnahme mit Hashing für offene Fragen zur Beantwortung von (Yamada et al., 2021, ACL, BPR )
- Composite Code Sparse AutoCoders für den Abruf der ersten Stufe (Lassance et al., 2021, Sigir, CCSA )
Dichte Abrufmethoden
- Wortembedingbasiert
- Aggregation Continuous Word -Einbettungen zum Abrufen von Informationen (Clinchanch et al., 2013, ACL, FV )
- Einsprachige und bringliche Informations-Abrufmodelle basierend auf (zweisprachigen) Wortbettendings (Vulic et al., 2015, Sigir)
- Kurztext Ähnlichkeit mit Wortbettendings (Kenter et al., 2015, Cikm, OOB )
- Ein Doppelbettungsraummodell für das Dokumentenranking (Mitra et al., 2016, Arxiv, Desm )
- Effizienter Vorschlag für die natürliche Sprache für die intelligente Antwort (Henderson et al., 2017, Arxiv)
- End-to-End-Abruf im kontinuierlichen Raum (Gillick et al., 2018, Arxiv)
- Phrase-Indexed Frage Beantwortung: Eine neue Herausforderung für das skalierbare Dokumentverständnis (Seo et al., 2018, EMNLP, Piqa )
- Dichte Durchgangsabnahme für offene Domänenfragebedingungen (Karpukhin et al., 2020, EMNLP, DPR )
- Retrieval-Augmented Generation für wissensintensive NLP-Aufgaben (Lewis et al., 2020, Nips, Rag )
- Repbert: Kontextualisierte Texteinbettungen für den Abruf der ersten Stufe (Zhan et al., 2020, Arxiv, Repbert )
- CORT: Komplementäre Ranglisten von Transformatoren (Wrzalik et al., 2020, Naacl, Cort )
- DC-Bert: Entkopplung von Frage und Dokument für eine effiziente Kontextcodierung (Nie et al., 2020, Sigir, DC-Bert )
- Neuronales Abruf für die Beantwortung von Fragen mit kreuzbewusster Datenvergrößerung (Yang et al., 2021, ACL, Datenvergrößerung )
- Ungefähr dem nächsten Nachbarn Negatives kontrastives Lernen für dichte Textabnahme (Xiong et al., 2020, Arxiv, Ance )
- Erlernen des Abrufens: Wie man ein dichter Abrufmodell effektiv und effizient trainiert (Zhan et al., 2020, Arxiv, Ltre )
- Glow: Global gewichtete Selbstbekämpfungsnetzwerk für Web (Shan et al., 2020, Arxiv, Glow )
- Ein optimierter Trainingsansatz für die Abnahme des dichten Durchgangs für die Beantwortung von Open-Domain-Frage (Qu et al., 2021, ACL, Rocketqa )
- Effizientes Unterrichten eines effektiven dichten Retrievers mit ausgewogenem Thema Awesare Probenahme (Hofstätter et al., 2021, Sigir, Tas-Balanced )
- Optimieren dichtes Abrufmodell Training mit harten Negativen (Zhan et al., 2021, Sigir, Stern/Adore )
- Wenige Schuss-Konversationsdicht-Rückruf (Yu et al., 2021, Sigir)
- Lerndichte Darstellungen von Phrasen in Skala (Lee et al., 2021, ACL, Denphrasen )
- Robuster dichtes Abruf mit kontrastivem Doppellernen (Lee et al., 2021, ICTIR, Tanz )
- Paar: Nutzung der passungszentrierten Ähnlichkeitsbeziehung zur Verbesserung der Abnahme der dichten Passage (Ren et al., 2021, ACL, Paar )
- Relevanzgeführte Aufsicht für OpenQA mit Colbert (Khattab et al., 2021, TaCl, Colbert-Qa )
- End-to-End-Training von Multi-Dokument-Leser und Retriever für die Beantwortung von Open-Domain-Frage (Sachan et al., 2021, Arxiv, EMDR^2 )
- Verbesserung der Abfrageverträge für den dichten Abruf mit Pseudo-Relevanz-Feedback (Yu et al., 2021, CIKM, ANCE-PRF )
- Pseudo-Relevanz-Feedback für die multiple Repräsentation Dichtes Abruf (Wang et al., 2021, ICTIR, Colbert-PRF )
- Ein diskriminierender semantischer Ranger für die Rückruf von Fragen (Cai et al., 2021, ICTIR, Densetrans )
- Repräsentation Entkopplung für die Abholung der Open-Domänen-Passage (Wu et al., 2021, Arxiv)
- Rocketqav2: Eine gemeinsame Trainingsmethode für den Abruf und die Durchgangsüberwachung des Durchgangs (Ren et al., 2021, EMNLP, Rocketqav2 )
- Effektives Training von Abrufmodellen unter Verwendung negativer Cache (Lindgren et al., 2021, Neurips)
- Mehrstufiges Training mit einem verbesserten negativen Kontrast für die Abnahme des neuronalen Durchgangs (Lu et al., 2021, EMNLP)
- Verbesserung der Einbettungsbasis groß angelegte Abruf durch Kennzeichnungsverstärkung (Liu et al., 2021, EMNLP)
- Dichte hierarchische Abruf für die Beantwortung von Open-Domain-Frage (Liu et al., 2021, EMNLP)
- Progressiv optimierte bi-granulare Dokumentdarstellung für skalierbare Einbettungsbasis (xiao er al., 2022 , www)
- LED: Lexikon-aufgeleuchtete dichte Retriever für das groß angelegte Abruf (Zhang et al., 2023, www)
- Aggretriever: Ein einfacher Ansatz zur aggregierten textuellen Darstellung für eine robuste Durchgangsabnahme (Lin et al., 2022, Arxiv)
- Satzbewusstes kontrastives Lernen für die Abholung der Open-Domänen-Passage (Wu et al., 2022, ACL)
- Aufgabenbewusste Spezialisierung für effiziente und robuste dichte Wiederholung für offene Domänen-Frage zur Beantwortung von (Cheng et al., 2022, Arxiv)
- Wissensdestillation
- Destillieren dichte Darstellungen für das Ranking mit eng gekoppelten Lehrern (Lin et al., 2020, Arxiv, TCT-Colbert )
- Destillieren von Wissen für schnelle Abrufbasis Chat-Bots (Tahami et al., 2020, Sigir)
- Destillieren von Wissen vom Leser zu Retriever für die Beantwortung von Fragen (Izacard et al., 2020, Arxiv)
- Ist Retriever lediglich ein Approximator des Lesers? (Yang et al., 2020, Arxiv)
- Verbesserung des BI-Coder-Dokumentranking-Ranking-Modelle mit zwei Rankern und Destillation mit mehreren Lehrern (Choi et al., 2021, Sigir, TRMD )
- Verbesserung effizienter neuronaler Ranking-Modelle mit Cross-Architecture-Wissensdestillation (Hofstätter et al., 2021, Arxiv, Margin-MSE-Verlust )
- Twinbert: Destillieren von Wissen zu zweistrukturierten komprimierten Bert-Modellen für groß angelegte Abruf (Lu et al., 2022, Arxiv)
- Multi-Vektor-Darstellung
- Multi-Hop-Absatz-Abruf für die Beantwortung von Open-Domain-Frage (Feldman et al., 2019, ACL, Muppet )
- Spärliche, dichte und Aufmerksamkeitsdarstellungen für die Textabnahme von Text (Luan et al., 2020, TaCl, Me-Bert )
- Colbert: Effiziente und effektive Durchgangssuche über kontextualisierte verspätete Interaktion über Bert (Khattab et al., 2020, Sigir, Colbert )
- Spule: Genau die genaue lexikalische Übereinstimmung im Informationsabruf mit kontextualisierter invertierter Liste (Gao et al., 2021, NaCl, Spule )
- Verbesserung der Dokumentendarstellungen durch Generierung von Pseudo -Abfragen Einbettungen für dichte Abruf (Tang et al., 2021, ACL)
- Phrase Retrieval lernt das Abrufen von Passagen auch (Lee et al., 2021, EMNLP, Denphrasen )
- Abfrage einbettet Beschneidung für dichte Abruf (Tonellotto et al., 2021, Cikm)
- Multi-View-Dokument-Repräsentation Lernen für offene Dense Abruf (Zhang et al., 2022, ACL)
- Colbertv2: Effektives und effizientes Abruf durch leichte späte Wechselwirkung (Santhanam, 2022, Naacl)
- Lernen verschiedener Dokumentenrepräsentationen mit tiefen Abfrageinteraktionen für dichte Abruf (Li et al., 2022, Arxiv)
- Topic-Keim-repräsentatives Modell für das Abrufen von Dokumenten (Du et al., 2022, Icann)
- Beschleunigte interaktionsbasierte Modelle
- Einbeziehung der Annahme von Abfragebestimmungen für die Unabhängigkeit für effizientes Abrufen und Ranking mit tiefen neuronalen Netzwerken (Mitra et al., 2019, Arxiv)
- Effizientes interaktionsbasiertes neuronales Ranking mit lokalempfindlichem Hashing (Ji et al., 2019, www)
- Poly -codeer: Architekturen und Voraussetzungsstrategien für schnelle und genaue Multi-Sentenz-Bewertungen (Humeau et al., 2020, ICLR, Poly-Coder )
- Modularisierter Transfomer-basiertes Ranking-Framework (Gao et al., 2020, EMNLP, Mores )
- Effizientes Dokument-Ranging für Transformatoren durch Vorkomputierung von Term Repräsentationen (Macavaney et al., 2020, Sigir, Prettr )
- Deformator: Zersetzung vorgebrachte Transformatoren für schnellere Frage zur Beantwortung von (Cao et al., 2020, ACL, Deformator )
- Sparta: effiziente Fragen zur Beantwortung von Open-Domain-Frage, die durch Sparse Transformator Matching Abruf (Zhao et al., 2020, Arxiv, Sparta )
- Konformer-Kernel mit Abfragebegriff Unabhängigkeit für das Abrufen von Dokumenten (Mitra et al., 2020, Arxiv)
- Inttower: Die nächste Generation des Zwei-Turm-Modells für das vorrangige System (Li et al., 2022, Cikm)
- Vorausbildung
- Latente Abruf für schwach beaufsichtigte offene Domain -Frage Beantwortung (Lee et al., 2019, ACL, Orqa )
- Abrufener Sprachmodell vor der Ausbildung (Guu et al., 2020, ICML, Reich )
- Aufgaben vor der Ausbildung zum Einbettungsbasis auf großem Maßstab Abruf (Chang et al., 2020, ICLR, BFS+WLP+MLM )
- Ist Ihr Sprachmodell bereit für eine dichte Darstellung Feinabstimmung? (Gao et al., 2021, EMNLP, Kondensator )
- Unbeaufsichtigtes Korpus-Bewusstseins-Sprachmodell vor der Ausbildung für dichte Durchgangsabnahme (Gao et al., 2021, Arxiv, Cocdenser )
- Weniger ist mehr: Vorab trainierte ein starker siamesischer Encoder mit einem schwachen Decoder (Lu et al., 2021, EMNLP, Seed-Coder )
- Vorausgebildeter Sprachmodell für das Abrufen des Webmaßstabs in Baidu-Suche (Liu et al., 2021, KDD)
- Pre-Training für Ad-hoc-Abruf: Hyperlink ist auch Sie brauchen (Ma et al., 2021, Cikm, Harp )
- Vor dem Training Ein diskriminierender Textcodierer für den dichten Abruf über kontrastive Span-Vorhersage (MA et al., 2022, Sigir)
- TSDAE: Verwenden von transformatorbasiertem sequentiellem Denoising Auto-Ccoder für unbeaufsichtigtes Satz Einbetten des Lernens (Wang et al., 2021, EMNLP)
- CONTEXTUAL MASK AUTOO-CODER FÜR DEZE ARBEITSBEDEUTUNG (WU et al., 2022, Arxiv)
- SIMLM: Vorausbildung mit Repräsentation Engpass für dichte Durchgangsabnahme (Wang et al., 2022, Arxiv)
- Lexmae: Lexikonboden-Vorbereitung für das groß angelegte Abruf (Shen et al., 2022, Arxiv)
- Ein kontrastiver Vorausbildungsansatz zum Erlernen des diskriminierenden Autoencodierers für dichte Abruf (Ma et al., 2022, Cikm)
- Retromae: Abruforientierte Sprachmodelle vor dem Training über maskierte Auto-Coder (Xiao und Liu et al., 2022, EMNLP)
- Abrufenorientierte Maskierung vor dem Training Sprachmodell für dichte Passage Abruf (Long et al., 2022, Arxiv)
- Laprador: unbeaufsichtigtes vorbereitete dichte Retriever für Null-Shot-Text-Abruf (Xu et al., 2022, ACL)
- Maskierte Autoencoder als einheitliche Lernende für die vorgebrachte Satzrepräsentation (Liu et al., 2022, Arxiv)
- Master: Multi-Task-Vorausgebläte-Engpässe maskierte Autocoder sind besser dichte Retrievers (Zhou et al., 2023, ICLR)
- Cot-Mae V2: Kontextuelle maskierte Auto-Coder mit Multi-View-Modellierung für die Durchgangsabnahme (Wu et al., 2023, Arxiv)
- Cot-Mote: Erforschen kontextbezogener maskierter automatischer Encoder-Vorbild mit Mischungsmischung der Text-Experten für die Durchgangsabnahme (Ma et al., 2023, Arxiv)
- Gemeinsames Lernen mit Index
- Gemeinsames Lernen des tiefen Abrufmodells und Produktquantisierungsbasis für ein Einbettungsindex (Zhang et al., 2021, Sigir, Poeem )
- Gemeinsam optimieren Abfrage -Encoder und Produktquantisierung zur Verbesserung der Abrufleistung (Zhan et al., 2021, CIKM, JPQ )
- Matching-orientiertes Produktquantisierung für Ad-hoc-Abruf (Xiao et al., 2021, EMNLP, MOPQ )
- Lernen diskrete Darstellungen durch eingeschränktes Clustering für eine effektive und effiziente dichte Wiederholung (Zhan et al., 2022, WSDM, Reponc )
- Gemeinsames Lernen mit Ranger
- End-to-End-Ausbildung von neuronalen Retrievers für die Beantwortung von Open-Domain-Frage (Sachan et al., 2021, ACL)
- VERTREIGER RETRIEVER-RANKER FÜR DENSE TEXT ARRAGURUVE (Zhang et al., 2022, ICLR)
- Debias
- Lernen robuster dichter Abrufmodelle aus unvollständigen Relevanzbezeichnungen (Prakash et al., 2021, Sigir, Rance )
- Hardnegative oder falsche Negative: Korrektur von Billendverzerrungen in der Ausbildung neuronaler Rangmodelle (Cai et al., 2022, Cikm)
- Simans: Einfache mehrdeutige Negative Probenahme für dichte Textabnahme (Zhou et al., 2022, EMNLP)
- Debiased kontrastives Lernen von unbeaufsichtigten Satzdarstellungen (Zhou et al., 2022, ACL)
- Wiederherstellung von Gold aus schwarzem Sand: Mehrsprachiger Durchgang mit harten und falsch negativen Proben (Shen et al., 2022, EMNLP)
- Null-Shot/Wenig-Shot
- Einbettungsbasierte Zero-Shot-Abruf durch Abfragegenerierung (Liang et al., 2020, Arxiv)
- Abruf der neuronalen Passage mit Null-Shot-Durchgang über domänengeschriebene synthetische Fragengenerierung (Ma et al., 2020, Qgen , Arxiv)
- Auf dem Weg zu robusten neuronalen Abrufmodellen mit synthetischer Vorausbildung (Reddy et al., 2021, Arxiv)
- Beir.
- Null-Schotten-dichte Wiederaufnahme mit dynamischer kontrovers-domäne-invariante Darstellungen (Xin et al., 2021, Arxiv, Modir )
- Große Doppelcodierer sind verallgemeinerbare Retriever (Ni et al., 2022, EMNLP, DTR )
- Semantik außerhalb der Domäne zur Rettung! Null-Shot-Hybrid-Retrieval-Modelle (Chen et al., 2022, Ecir)
- Unterne: Datenvergrößerung zum Abrufen von Informationen unter Verwendung von großsprachigen Modellen (Bonifacio et al., 2022, Arxiv)
- Auf unüberwindende dichte Informationsabnahme mit kontrastivem Lernen (Izacard et al., 2021, Arxiv, Contriever )
- GPL: Generative Pseudo -Markierung für unbeaufsichtigte Domänenanpassung des dichten Abrufs (Wang et al., 2022, Naacl)
- Lernen, Passagen ohne Aufsicht abzurufen (Ram et al., 2021, Arxiv, Spinne )
- Eine gründliche Untersuchung bei einer dichten Abruf von Zero-Shot (Ren et al., 2022, Arxiv)
- Text- und Code-Einbettungen durch kontrastives Vorverbrauch (Neelakantan et al., 2022, Arxiv)
- Entwirrte Modellierung von Domäne und Relevanz für anpassungsfähige dichte Wiederholung (Zhan et al., 2022, Arxiv)
- Promptagator: wenige scheiß dichte relieval aus 8 Beispielen (Dai et al., 2022, Arxiv)
- Fragen sind alles, was Sie brauchen, um eine dichte Passage Retriever zu trainieren (Sachan et al., 2022, TaCl)
- HYPER: Multitasking Hyper-Prompted-Training ermöglicht eine großflächige Abrufverallgemeinerung (Cai et al., 2023, ICLR)
- Coco-Dr.
- Herausforderungen in der Verallgemeinerung in der Frage der offenen Domäne zur Beantwortung von (Liu et al., 2022, Naacl)
- Robustheit
- Auf dem Weg zu einer robusten dichten Wiederholung über die lokale Ranking -Ausrichtung (Chen et al., 2022, Ijcai))
- Umgang mit Tippfehlern für Bert-basierte Passage Abruf und Ranking (Zhuang et al., 2021, EMNLP)
- Bewertung der Robustheit von Abrufpipelines mit Abfragevariationsgeneratoren (Penha et al., 2022, Ecir)
- Analyse der Robustheit von Doppelcodierern auf dichten Abruf gegen Rechtschreibfehler (Sidiropoulos et al., 2022, Sigir)
- Charakterbert und Selbstunterricht zur Verbesserung der Robustheit dichter Retriever bei Abfragen mit Tippfehler (Zhuang et al., 2022, Sigir)
- Bert -Ranker sind spröde: Eine Studie unter Verwendung von kontroversen Dokumentenstörungen (Wang et al., 2022, ICTIR)
- Orderstörer: Nachahmungsgegner für Blackbox Neural Ranking-Modelle (Liu et al., 2022, Arxiv)
- Tippflichtige Engpässe vor der Ausbildung für eine robuste dichte Wiederholung (Zhuang et al., 2023, Arxiv)
- Prüfanalyse
- Der Fluch der dichten niedrigdimensionalen Informationsabnahme für große Indexgrößen (Reimers et al., 2021, ACL)
- Einfache und effektive unbeaufsichtigte Redundanzeliminierung, um dichte Vektoren für die Durchgangsabnahme zu komprimieren (Ma et al., EMNLP, 2021, Redundanz )
- Beir .
- Ausdrucksvoller Ausdruck, der eine dichte Wiederholung bewusst wird: Kann ein dichter Retriever einen spärlichen? (Chen et al., 2021, Arxiv)
- Einfache von entität zentrierte Fragen Herausforderung Dense Retriever (Sciavolino et al., 2021, EMNLP)
- Interpretation dichtes Abruf als Mischung von Themen (Zhan et al., 2021, Arxiv)
- Eine Encoder-Attributionsanalyse für dichte Passage Retriever in offener Domänen-Frage zur Beantwortung von (Li et al., 2022, Trustnlp)
- Die isotrope Darstellung kann die dichte Wiederholung verbessern (Jung et al., 2022, Arxiv)
- Schnelles Lernen
- Semi-Siamese BI-Coder Neural Ranking-Modell mit leichtem Feinabstimmungsmodell (Jung et al., 2022, www)
- Verstreut oder verbunden? Ein optimierter parameter-effizienter Tuning-Ansatz zum Abrufen von Informationen (Ma et al., 2022, Cikm)
- DPTDR: Tiefes Tuning für dichte Durchgangsabnahme (Tang et al., 2022, Arxiv)
- Parameter-effizientes Einort-Tuning macht verallgemeinerte und kalibrierte Neuraltext-Retriever (Tam et al., 2022, Arxiv)
- NIR-Prompt: Ein Multi-Task-Trainingsrahmen für neuronale Information Abruf (Xu et al., 2022, Arxiv)
- Großsprachmodell zum Abrufen
- Präzise null-schotendere Wiederherstellung ohne Relevanzbezeichnungen (Gao et al., 2022, Arxiv)
- Andere
- HLATR: Verbessern Sie mehrstufiges Textabruf mit Hybridliste Acuare Transformator Reranking (Zhang et al., 2022, Arxiv)
- Asyncval: Ein Toolkit zur asynchronen validierenden Dense Retriever -Checkpoints während des Trainings (Zhuang et al., 2022, Sigir)
Hybrid -Abrufmethoden
- Wortembedingbasiert
- Einsprachige und bringliche Informations-Abrufmodelle basierend auf (zweisprachigen) Wortbettdings (Vulic et al., 2015, Sigir, linear kombinieren )
- Worteinbettungsbasiertes verallgemeinertes Sprachmodell zum Abrufen von Informationen (Ganguly et al., 2015, Sigir, GLM )
- Darstellung von Dokumenten und Abfragen als Sätze von Wort eingebetteten Vektoren zum Abrufen von Informationen (Roy et al., 2016, Sigir, linear kombinieren )
- Ein Doppelbettungsraummodell für das Dokumentenranking (Mitra et al., 2016, www, DESM_MIXTURE , linear kombinieren )
- Aus dem ausgetretenen Pfad: Ersetzen wir das emmbasierte Abruf durch K-NN-Suche (Boytsov et al., 2016, CIKM, BM25+Translationsmodell )
- Lernhybride Darstellungen zum Abholen semantisch äquivalenter Fragen (Santos et al., 2015, ACL, Bow-CNN )
- Echtzeit offene Domänen-Frage Beantwortung mit dem Phrase-Index des Densparsen (Seo et al., 2019, ACL, Denspi )
- Kontextualisierte spärliche Darstellungen für Echtzeit-Fragen zur Beantwortung von Open-Domain-Frage (Lee et al., 2020, ACL, Sparc )
- CORT: Komplementäre Ranglisten von Transformatoren (Wrzalik et al., 2020, Naacl, Cort_BM25 )
- Spärliche, dichte und Aufmerksamkeitsdarstellungen für das Abrufen von Text (Luan et al., 2020, TaCl, Me-Hybrid )
- Komplement lexikalisches Abrufmodell mit semantischen Restbettendings (Gao et al., 2020, ECIR, Clear )
- Nutzung der semantischen und lexikalischen Übereinstimmung zur Verbesserung des Rückrufs von Dokumentenabrufsystemen: Ein hybrider Ansatz (Kuzi et al., 2020, Arxiv, Hybrid )
- Ein paar kurze Hinweise zu Deepimpact, Coil und einem konzeptionellen Rahmen für Informationsabruftechniken (Lin et al., 2021, Arxiv, Unicoil )
- Kontextualisierte Offline -Relevanzgewichtung für effizientes und effektives neuronales Abruf (Chen et al., 2021, Sigir)
- Vorhersage von Kompromisse für Effizienz/Effektivität für dichte und spärliche Abrufstrategie-Selektion (Arabzadeh et al., 2021, Cikm)
- Schnelle Forward -Indizes für ein effizientes Dokumentenranking (Leonhardt et al., 2021, Arxiv)
- Verprägte spärliche Darstellungen für das Abrufen von Durchgang durch Repräsentationsschnitte (Lin et al., 2021, Arxiv)
- Uni fi er: Ein eindeutiger Retriever für groß angelegte Abruf (Shen et al., 2022, Arxiv)
Andere Ressourcen
Andere Aufgaben
- E-Commerce-Suche
- Deep Interest Network für die Klick-Through-Ratenvorhersage (Zhou et al., 2018, KDD, Din )
- Vom semantischen Abruf bis hin zu paarweise Ranking: Anwenden von Deep-Lernen in der E-Commerce-Suche (Li et al., 2019, Sigir, Jingdong)
- Multi-Interest-Netzwerk mit dynamischem Routing zur Empfehlung bei Tmall (Li et al., 2019, CIKM, Mind , Tmall)
- Auf dem Weg zu personalisiertem und semantischem Abruf: Eine End-to-End-Lösung für die E-Commerce-Suche durch Einbettung von Lernen (Zhang et al., 2020, Sigir, DPSR , Jingdong)
- Deep Multi-Interest-Netzwerk für die Klickrate-Vorhersage (Xiao et al., 2020, Cikm, Dmin )
- Tiefes Abruf: Ein End-to-End-Strukturmodell für groß angelegte Empfehlungen (Gao et al., 2020, Arxiv)
- Einbettungsbasiertes Produktabruf in die Taobao-Suche (Li et al., 2021, KDD, Taobao)
- Umarmung der Struktur in Daten für die milliardenstufige semantische Produktsuche (Lakshman et al., 2021, Arxiv, Amazon)
- Gesponserte Suche
- Mobius: Auf dem Weg zur nächsten Generation von Abfragen in Baidus gesponserter Suche (Fan et al., 2019, KDD, Baidu)
- Bildabnahme
- Binäres neuronales Netzwerk Hashing für Bildabruf (Zhang et al., 2021, Sigir, Bnnh )
- Tiefes selbstadaptives Hashing für Bildabruf (Lin et al., 2021, Cikm, DSAH )
- Bericht über den ersten Hipstir -Workshop zur Zukunft des Informationsabrufs (Dietz et al., 2019, Sigir, Workshop)
- Lassen Sie uns die Laufzeit messen! Erweiterung der IR -Reproduzierbarkeitsinfrastruktur auf Leistungsaspekte (Hofstätter et al., 2019, Sigir)
- Einbettungsbasierte Abruf in Facebook-Suche (Huang et al., 2020, KDD, EBR )
- Lernen K-Way D-dimensional diskrete Codes für Kompaktbettungsdarstellungen (Chen et al., 2018, ICML)
Datensätze
- 【MS MARCO】 MS MARCO: Ein menschlicher Datensatz für maschinelles Leseverständnis
- 【TREC CAR】 TREC -Komplex -Antwort -Abrufübersicht
- 【TREC DL】 Übersicht über den Trec 2019 Deep Learning Track
- 【TREC COVID】 TREC-Covid: Erstellung einer Sammlung pandemischer Informationsabruf-Tests
Indizierungsmethoden
- Baumbasiert
- Mehrdimensionale binäre Suchbäume, die zur assoziativen Suche verwendet werden (1975, KD Tree )
- Belästigen
- Hashing-basiert
- Ungefähr am nächsten Nachbarn: Um den Fluch der Dimensionalität zu beseitigen, 1998, LSH )
- Quantisierungsbasiert
- Produktquantisierung für die nächste Nachbarsuchung (2010, pq )
- Optimierte Produktquantisierung (2013, OPQ )
- Graph-basiert
- Navigation in einer kleinen Welt (2000, NSW )
- Effiziente und robuste ungefähre Suche nach der nächsten Nachbarn mit hierarchischen schiffbaren kleinen Weltgrafiken (2018, HNSW )
- Toolkits
- FAISS: Eine Bibliothek zur effizienten Ähnlichkeitssuche und Clusterbildung dichter Vektoren
- SPTAG: Eine Bibliothek für eine schnelle ungefähre Suche nach dem nächsten Nachbarn
- OpenMatch: Ein Open-Source-Paket zum Abrufen von Informationen
- Pyserini: Ein Python -Toolkit für reproduzierbare Informationsabrufforschung mit spärlichen und dichten Darstellungen
- Elasticsarch


