Потрясающие семантические модели для первой стадии поиска
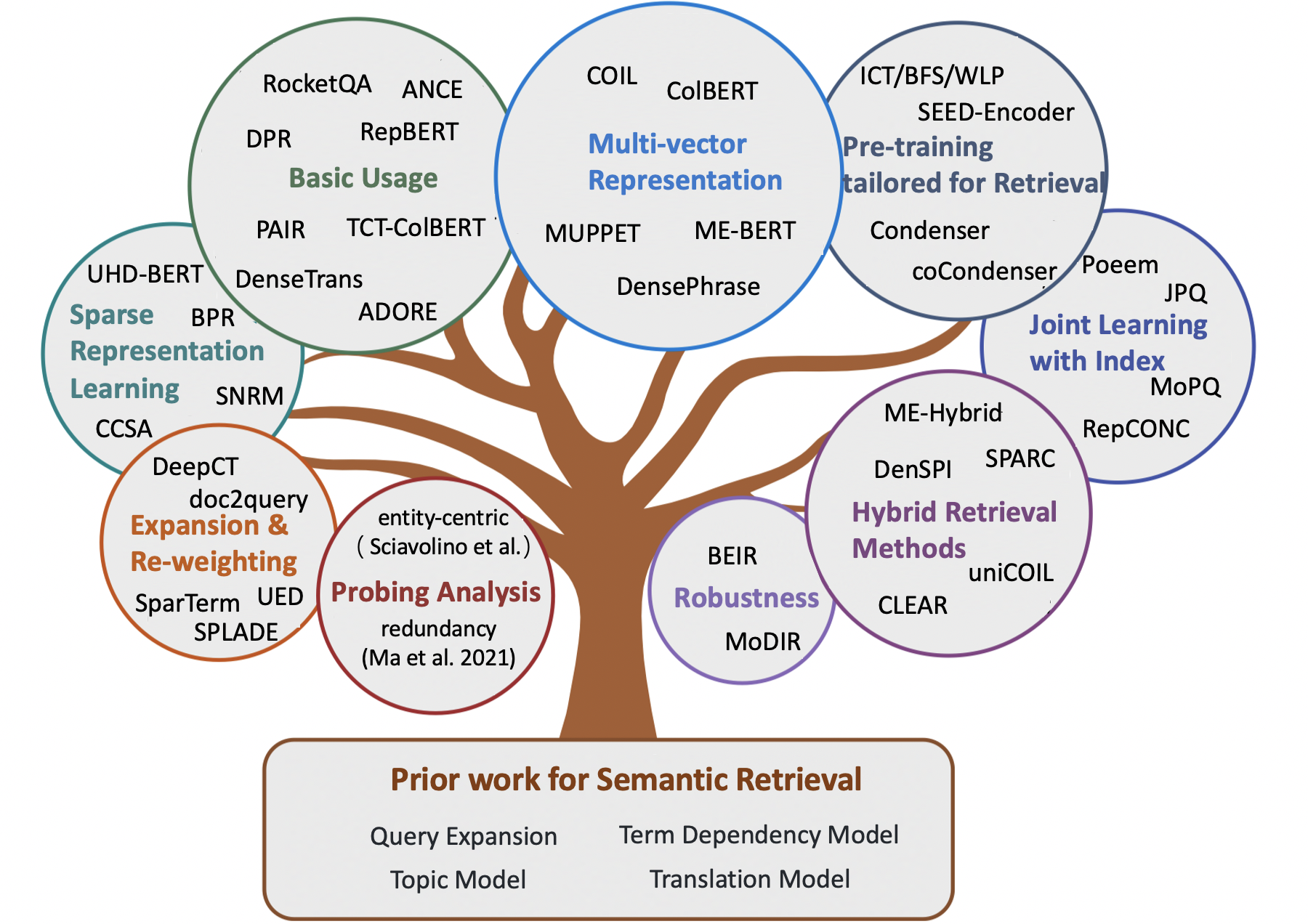
Примечание:
- Куративный список удивительных работ для семантического поиска , включая некоторые ранние методы и недавние нейронные модели для задач поиска информации (например, Ad-Hoc поиск, QA с открытым доменом, QA на основе сообщества и автоматический разговор).
- Для исследователей, которые хотят приобрести семантические модели для переоборудования, мы направляем читателей в удивительный опрос Neuir от Guo et.al.
- Любые отзывы и вклад приветствуются, откройте проблему или свяжитесь со мной.
Содержимое
- Обзорная статья
- Глава 1: Классический поиск на основе терминов
- Глава 2: Ранние методы семантического поиска
- Расширение запроса
- Расширение документа
- Термин модель зависимости
- Тематическая модель
- Модель перевода
- Глава 3: Нейронные методы семантического поиска
- Разреженные методы поиска
- Плотные методы поиска
- Гибридные методы поиска
- Глава 4: Другие ресурсы
- Другие задачи
- Наборы данных
- Методы индексации
Обзорная статья
- Семантическое соответствие в поиске (Li et al., 2014)
- Предварительные трансформаторы для рейтинга текста: Bert и Beyond (Lin et al., 2021, Arxiv)
- Семантические модели для первой стадии поиска: всесторонний обзор (Guo et al., 2021, Tois)

- Предлагаемая концептуальная основа для репрезентативного подхода к поиску информации (Lin et al., 2021, Arxiv)
- Методы предварительного обучения в поиске информации (Fan et al., 2022, Arxiv)
- Поиск плотного текста на основе моделей с предварительно проведенными языками: опрос (Zhao et al., 2022, Arxiv)
- Плотный поиск с низким ресурсом для ответа на вопрос с открытым доменом: комплексный опрос (Shen et al., 2022, Arxiv)
- Заметки на лекции по поиску нейронной информации (Tonellotto et al., 2022, Arxiv)
Классический термин поиск
- Модель векторного пространства для автоматической индексации (1975, VSM )
- Разработки в области автоматического поиска текста (1991, TFIDF )
- Термин-взвешивание подходов в автоматическом поиске текста (1988, TFIDF )
- Актуальность взвешивания поисковых терминов (1976, BIM )
- Теоретическая основа для использования данных о совместном месте в поиске информации (1997, модель зависимости деревьев )
- Структура вероятностной значимости: BM25 и за его пределами (2010, BM25 )
- Подход к изучению языкового моделирования к поиску информации (1998, QL )
- Статистические языковые модели для поиска информации (2007, LM для IR )
- Модель гипергеометрического языка и ZIPF-подобная функция оценки для сходства веб-документов (2010, LM для IR )
- Вероятностные модели поиска информации на основе измерения дивергенции по случайности (2002, DFR )
Ранние методы семантического поиска
Расширение запроса
- Глобальная модель
- Ассоциации слов в системах поиска документов (1969)
- Расширение запросов на основе концепций (1993)
- Расширение запросов с использованием лексико-эмантических отношений (1994)
- Использование контекстов запросов в поиске информации (2007)
- Локальная модель
- Обратная связь с актуальностью в поисках информации (1971, Rocchio PRF )
- Основанная на модели обратная связь в подходе к моделированию языка к поиску информации (2001, модель минимизации дивергенции )
- UMass at Trec 2004: новинка и жесткие (2004, RM3 для PRF )
- Выбор хороших условий расширения для псевдо-релевантной обратной связи (2008, PRF)
- Сравнительное исследование методов оценки языковых моделей запросов с псевдо обратной связью (2009)
- Обратная связь с псевдо-релевантностью на основе факторизации матрицы (2016 г.)
- Снижение риска расширения запросов за счет надежной ограниченной оптимизации (2009 г. , Запрос о дрифте задачи )
- Расширение запроса с использованием локального и глобального анализа документов (2017)
Расширение документа
- Структура корпуса, языковые модели и специальное поиск информации (2004)
- Поиск на основе кластера с использованием языковых моделей (2004 г.)
- Поиск информации о языковой модели с расширением документов (2006 г.)
- Расширение документов на основе Wordnet для надежного ИКА (2010)
- Улучшение поиска коротких текстов с помощью расширения документов (2012 г.)
- Расширение документа с использованием внешних коллекций (2017, на основе Wordnet )
- Расширение документов по сравнению с расширением запроса для специального поиска (2005)
Термин модель зависимости
- Эксперименты в области автоматической индексации фразы для поиска документов: сравнение синтаксических и несинтаксических методов (1987, VSM + Термин зависимость )
- Термин-взвешивание подходов в автоматическом поиске текста (1988, VSM + Term Degyserence )
- Анализ статистических и синтаксических фраз (1997, VSM + Term Depervice )
- Вероятностная модель поиска информации: разработка и сравнительные эксперименты (2000, VSM + Термингаж )
- Рейтинг релевантности с использованием ядра (2010, BM25 + Term Degy Delyency )
- Общая языковая модель для поиска информации (1999, LM + термин зависимости )
- Языковые модели Biterm для поиска документов (2002, LM + Термин зависимость )
- Захватывание терминов зависимостей с использованием языковой модели на основе деревьев предложений (2002, LM + Термин -зависимость )
- Модель языка зависимости для поиска информации (2004 г., LM + Термин зависимости )
- Генеративная теория актуальности (2008)
- Модель случайного поля Маркова для терминов зависимостей (2005, SDM )
Тематическая модель
- Обобщенная модель векторного пространства в поиске информации (1985, GVSM )
- Индексация с помощью скрытого семантического анализа (1990, LSI для IR )
- Вероятностная латентная семантическая индексация (2017, PLSA, линейно комбинация )
- Структура корпуса, языковые модели и специальное поиск информации (2004 г., сглаживание )
- Регулялизация специальных результатов поиска (2005 г., сглаживание )
- Модели документов на основе LDA для специального поиска (2006 г., LDA для IR и LDA для сглаживания LM )
- Сравнительное исследование использования тематических моделей для поиска информации (2009 г., сглаживание )
- Исследование выполнения задачи вероятностных тематических моделей: эмпирическое исследование PLSA и LDA (2010)
- Скрытая семантическая индексация (LSI) не удается для коллекций TREC (2011)
Модель перевода
- Поиск информации как статистический перевод (1999)
- Оценка статистических моделей перевода на основе взаимной информации для специального поиска информации (2010)
- Клипковые модели перевода на основе веб-поиска: от моделей слов до фразы моделей (2010)
- Аксиоматический анализ модели языка перевода для поиска информации (2012)
- Переписывание запросов с использованием перевода с одноязычной статистической машиной (2010 год, для расширения запросов )
- На пути к концепциям моделей перевода с использованием журналов поиска для расширения запросов (2012, для расширения запросов )
Нейронные методы семантического поиска
Разреженные методы поиска
- Термин переизвесок
- Обучение членам срока с распределением с распределенными представлениями (Zheng et al., 2015, Sigir, Deeptr )
- Интеграция и оценка встраиваемых нейронных слов в поиск информации (Zuccon et al., 2015, ADCS, NTLM )
- Учебный термин дискриминация (Frej et al, 2020, Sigir, TDV )
- Контекстный предложение/срок отрывка оценка важности для поиска первой стадии (Dai et al., 2019, Arxiv, DeepCt )
- Контекст-термин для взвешивания для первой стадии поиск прохода (Dai et al., 2020, Sigir, DeepCt )
- Последствия для эффективности термина взвешивания для поиска прохода (Mackenzie et al., 2020, Sigir, DeepCt )
- Контекстный срок действия документа термин для Ad-Hoc Search (Dai et al., 2020, www, hdct )
- Несколько кратких заметок о DeepImpact, катушке и концептуальной основе для методов поиска информации (Lin et al., 2021, Arxiv, Unicoil )
- Расширение
- Расширение документов с помощью прогнозирования запросов (Nogueira et al., 2019, Arxiv, doc2query )
- От doc2query до docttttttquery (Nogueira et al., 2019, Arxiv, doctttttquery )
- Единая предварительная рамка для ранжирования и расширения прохода (Yan et al., 2021, AAAI, UED )
- Поколение-аугимент поиск для ответа на вопрос с открытым доменом (Mao et al., 2020, ACL, GAR , расширение запроса )
- Расширение + Термин повторный взлог
- Расширение посредством прогнозирования важности с контекстуализацией (Macavaney et al., 2020, Sigir, Epic )
- Sparterm: Sparse Learnse Learning Learns Learning для быстрого извлечения текста (Bai et al., 2020, Arxiv, Sparterm )
- SPLADE: разреженная лексическая и экспансионная модель для ранжирования первой стадии (Formal et al., 2021, Sigir, Splade )
- SPLADE V2: разреженная лексическая модель и экспансию для поиска информации (Formal et al., 2021, Arxiv, Spladev2 )
- Учебный отрывок для перевернутых индексов (Mallia et al., 2021, Sigir, Diepimapct )
- Тилде: термин «Независимая модель вероятности для повторной оценки» (Zhuang et al., 2021, Sigir, Tilde )
- Быстрый отрывок, повторный рейтинг с контекстуализированным точным сопоставлением терминов и эффективным расширением прохода (Zhuang et al., 2021, Arxiv, Tildev2 )
- SPADE: улучшение разреженных представлений с использованием двойного документального кодера для поиска первой стадии (Choi et al., 2022, CIKM)
- Разрешенное представление обучение
- Семантическое хеширование (Salakhutdinov et al., 2009)
- От переосмысления нейронного ранжирования до нейронного рейтинга: изучение редкого представления для инвертированной индексации (Zamani et al., 2018, CIKM, SNRM )
- UHD-BERT: ультрасовременные разреженные представления о полном рейтинге (Jang et al., 2021, Arxiv, Uhd-Bert )
- Эффективный поиск прохода с хэшином для ответа на вопрос с открытым доменом (Yamada et al., 2021, ACL, BPR )
- Композитный код Sparse AutoEncoders для первой стадии поиска (Lassance et al., 2021, Sigir, CCSA )
Плотные методы поиска
- Слово-вводный
- Агрегация непрерывных встроенных слов для поиска информации (Clinchant et al., 2013, ACL, FV )
- Монолингвальные и межязычные модели поиска информации на основе (двуязычных) встроенных слов (Vulic et al., 2015, Sigir)
- Сходство короткого текста с вставками слов (Kenter et al., 2015, Cikm, OOB )
- Двойная космическая модель для ранжирования документов (Mitra et al., 2016, Arxiv, Desm )
- Эффективное предложение реагирования на естественный язык для умного ответа (Henderson et al., 2017, Arxiv)
- Сквозное поиск в непрерывном пространстве (Gillick et al., 2018, Arxiv)
- Ответ на вопрос, индексированный фразой: новая задача для масштабируемого понимания документов (Seo et al., 2018, EMNLP, PIQA )
- Поиск плотного отхода для ответа на вопрос с открытым доменом (Karpukhin et al., 2020, Emnlp, DPR )
- Полученное поколение для поиска задач NLP-интенсивных знаний (Lewis et al., 2020, Nips, Rag )
- Repbert: контекстуализированные текстовые встроены для поиска первой стадии (Zhan et al., 2020, Arxiv, Repbert )
- CORT: дополнительные рейтинги от Transformers (Wrzalik et al., 2020, NAACL, CORT )
- DC-Bert: развязка вопроса и документа для эффективной контекстуальной кодировки (Nie et al., 2020, Sigir, DC-Bert )
- Нейронное поиск для вопросов, отвечающий с помощью контролируемого перекрестного привлечения данных (Yang et al., 2021, ACL, увеличение данных )
- Приблизительное ближайшее соседское негативное контрастное обучение для плотного поиска текста (Xiong et al., 2020, Arxiv, Ance )
- Обучение для извлечения: как эффективно и эффективно обучить модель плотного поиска (Zhan et al., 2020, Arxiv, LTRE )
- Glow: Глобальная взвешенная сеть самопринятия для Интернета (Shan et al, 2020, Arxiv, Glow )
- Оптимизированный подход обучения к плотному поиску прохода для ответа на вопрос открытого домена (Qu et al., 2021, ACL, Rocketqa )
- Эффективное обучение эффективному плотному ретриверу с сбалансированной темой, осведомленной о темах (Hofstätter et al., 2021, Sigir, Tas-Balansed )
- Оптимизация тренировок с плотным поиском модели с жесткими негативами (Zhan et al., 2021, Sigir, Star/Adore )
- Несколько выстрелов разговорного поиска (Yu et al., 2021, Sigir)
- Учебное обучение плотные представления фраз в масштабе (Lee et al., 2021, ACL, DensePhrase )
- Более надежный плотный поиск с контрастным двойным обучением (Lee et al., 2021, Ictir, Dance )
- Пара: использование зависимости сходства, ориентированного на проходы для улучшения плотного извлечения прохода (Ren et al., 2021, ACL, пара )
- Наблюдение за актуальностью для OpenQA с Colbert (Khattab et al., 2021, Tacl, Colbert-Qa )
- Средняя обучение многодокументированного читателя и ретривера для ответа на вопрос открытого домена (Sachan et al., 2021, Arxiv, Emdr^2 )
- Улучшение представлений запросов для плотного извлечения с обратной связью с псевдо-актуальностью (Yu et al, 2021, Cikm, Ance-Prf )
- Псевдо-релевантная обратная связь для множественного представления плотного поиска (Wang et al., 2021, Ittir, Colbert-PRF )
- Дискриминационный семантический Ранкер для вопросов поиск (Cai et al., 2021, Ittir, Densetrans )
- Отправление представления для поиска прохода с открытым доменом (Wu et al., 2021, Arxiv)
- RocketQav2: совместный метод обучения для плотного отрыва от прохода и переосмысления прохода (Ren et al., 2021, Emnlp, RocketQav2 )
- Эффективное обучение моделей поиска с использованием отрицательного кеша (Lindgren et al., 2021, Neurips)
- Многостадийное обучение с улучшенным отрицательным контрастностью для поиска нейронного прохода (Lu et al., 2021, EMNLP)
- Улучшение крупномасштабного извлечения на основе встраивания за счет улучшения этикетки (Liu et al., 2021, EMNLP)
- Плотный иерархический поиск для ответа на вопрос с открытым доменом (Liu et al., 2021, Emnlp)
- Постепенно оптимизированное представление документов с би-гранулем для масштабируемого встраивания поиска (Xiao er Al., 2022 , www)
- Светодиод: Lexicon Learned Learn Lence Retriever для крупномасштабного поиска (Zhang et al., 2023, www)
- Aggretriever: простой подход к агрегатному текстовому представлению для надежного извлечения плотного отхода (Lin et al., 2022, Arxiv)
- Контрастное обучение с предложением для получения открытого домена (Wu et al., 2022, ACL)
- Специализация с учетом задач для эффективного и надежного плотного поиска для ответа на вопрос с открытым доменом (Cheng et al., 2022, Arxiv)
- Знания дистилляция
- Distilling плотные представления для ранжирования с использованием плотно связанных учителей (Lin et al., 2020, Arxiv, TCT-Colbert )
- Дистилляция знаний для быстрого поиска чат-ботов (Tahami et al., 2020, Sigir)
- Отделение знаний от читателя в ретривер для ответа на вопросы (Izacard et al., 2020, Arxiv)
- Ретривер просто приблизительный читатель? (Yang et al., 2020, Arxiv)
- Улучшение моделей ранжирования документов с двумя кодерами с двумя раншими и многочисленными дистилляцией (Choi et al., 2021, Sigir, TRMD )
- Улучшение эффективных моделей нейронного ранжирования с дистилляцией знаний по межархитектуре (Hofstätter et al., 2021, Arxiv, Margin-MSE потеря )
- ТВИНБЕРТ: Знание перегонки в сжатые модели BERT с двойной структурой для крупномасштабного поиска (Lu et al., 2022, Arxiv)
- Многоворное представление
- Поиск параграфа с несколькими ходами для ответа на вопрос с открытым доменом (Feldman et al., 2019, ACL, Muppet )
- Разреженные, плотные и внимательные представления для поиска текста (Luan et al., 2020, Tacl, Me-bert )
- Колберт: Эффективный и эффективный поиск отрывок через контекстуализированное позднее взаимодействие над Бертом (Khattab et al., 2020, Sigir, Colbert )
- Катушка: Пересмотрите точное лексическое соответствие в поиске информации с контекстуализированным перевернутым списком (Gao et al., 2021, NaCl, катушка )
- Улучшение представлений о документах путем генерации псевдо -запросов для плотного поиска (Tang et al., 2021, ACL)
- Поиск фразы учится на поиске отрывка, тоже (Lee et al., 2021, Emnlp, DensePhrase )
- Запрос встраивает обрезку для плотного поиска (Tonellotto et al., 2021, CIKM)
- Обучение представления с несколькими просмотрами для открытого домена.
- COLBERTV2: Эффективный и эффективный поиск через легкое позднее взаимодействие (Сантанам, 2022, NAACL)
- Изучение разнообразных представлений документов с глубоким взаимодействием запросов для плотного поиска (Li et al., 2022, Arxiv)
- Тематическая модель на основе представления текста для поиска документов (Du et al., 2022, Icann)
- Ускоряющие модели на основе взаимодействия
- Включение допущений на независимость за запроса для эффективного поиска и ранжирования с использованием глубоких нейронных сетей (Mitra et al., 2019, Arxiv)
- Эффективный нейронный рейтинг на основе взаимодействия с чувствительным к местным хешированию (Ji et al., 2019, www)
- Поли-кодеры: архитектуры и стратегии предварительного обучения для быстрой и точной оценки с несколькими предложениями (Humeau et al., 2020, ICLR, Polycoders )
- Модульная структура ранжирования на основе трансфмеров (Gao et al., 2020, Emnlp, Mores )
- Эффективная повторная оценка документов для трансформаторов путем предварительного выпуска термин
- Deformer: разложение предварительно обученных трансформаторов для более быстрого ответа на вопрос (Cao et al., 2020, ACL, Deformer )
- Sparta: эффективный вопрос с открытым доменом, отвечающий на поиск Sparse Transformer Matching Retieval (Zhao et al., 2020, Arxiv, Sparta )
- Confermer-kernel с независимостью термина запроса для поиска документов (Mitra et al., 2020, Arxiv)
- Inttower: следующее поколение модели с двумя башнями для предварительной системы (Li et al., 2022, CIKM)
- Предварительное обучение
- Скрытый поиск для слабо контролируемого ответа на вопрос открытого домена (Lee et al., 2019, ACL, Orqa )
- Предварительное обучение языковой модели, полученная на аугментировании (Guu et al., 2020, ICML, Realm )
- Задачи предварительного обучения для встраивания крупномасштабного поиска (Chang et al., 2020, ICLR, BFS+WLP+MLM )
- Готова ли ваша языковая модель к плотной настройке? (Gao et al., 2021, EMNLP, конденсатор )
- Неконтролируемое корпус, осведомленная о языковой модели, предварительная тренировка для плотного отрыва (Gao et al., 2021, Arxiv, Cocondenser )
- Меньше больше: предварительное обучение сильного сиамского энкодера с использованием слабого декодера (Lu et al., 2021, Emnlp, Seed-Encoder )
- Предварительно обученная языковая модель для поиска в Интернете в поиске Baidu (Liu et al., 2021, KDD)
- Предварительное обучение для специального поиска: гиперссылка также необходима (Ma et al., 2021, Cikm, Harp )
- Предварительный проезд.
- TSDAE: Использование последовательного дженоневого автоматического оборота на основе трансформаций для неконтролируемого предложения внедряет обучение (Wang et al., 2021, EMNLP)
- Контекстная маска Auto-Encoder для плотного извлечения прохода (Wu et al., 2022, Arxiv)
- SIMLM: предварительное обучение с узким местом для представления для плотного извлечения прохода (Wang et al., 2022, Arxiv)
- Lexmae: Lexicon-Bottlenecked Pretringaing для крупномасштабного поиска (Shen et al., 2022, Arxiv)
- Контрастный подход предварительного обучения для изучения дискриминационного автоэнкодера для плотного поиска (Ma et al., 2022, CIKM)
- Retromae: ориентированные на поиск модели, ориентированные на поиск с помощью маскированного автооборода (Xiao and Liu et al., 2022, Emnlp)
- Поиск, ориентированная на поиск, маскирующая языковая модель для плотного извлечения прохода (Long et al., 2022, Arxiv)
- Лапладор: неконтролируемый предварительно проведенный плотный ретривер для поиска текста с нулевым выстрелом (Xu et al., 2022, ACL)
- Автокодеры в масках в качестве объединенных учеников для предварительного представления предложения (Liu et al., 2022, Arxiv)
- Мастер: Предварительно обученные узколетние автоматические автоходеры в масках-масках-лучшие плотные ретриверы (Zhou et al., 2023, ICLR)
- Cot-Mae V2: Автоохододер с контекстуальным маскированием с многоэтажным моделированием для поиска прохода (Wu et al., 2023, Arxiv)
- Cot-Mote: изучение контекстуального маскируемого автоматического обучения с смесью текстовых экспертов для поиска прохода (Ma et al., 2023, Arxiv)
- Совместное обучение с индексом
- Совместное обучение модели глубокого поиска и индекса встраивания на основе квантования продукта (Zhang et al., 2021, Sigir, Poeum )
- Совместно оптимизировать энкодер запросов и квантование продукта для повышения производительности поиска (Zhan et al., 2021, CIKM, JPQ )
- Квантование продукта, ориентированное на соответствие для Ad-HOC поиска (Xiao et al., 2021, EMNLP, MOPQ )
- Обучение дискретным представлениям посредством ограниченной кластеризации для эффективного и эффективного плотного извлечения (Zhan et al, 2022, WSDM, Repconc )
- Совместное обучение с Ранером
- Средняя тренировка нейронных ретриверов для ответа на вопрос о открытой области (Sachan et al., 2021, ACL)
- Adversarial Retriever-Ranker для плотного поиска текста (Zhang et al., 2022, ICLR)
- Дебис
- Обучение надежных плотных моделей поиска из неполных релевантных ярлыков (Prakash et al., 2021, Sigir, Rance )
- Тяжелые негативы или ложные негативы: исправление смещения объединения в обучении моделей нейронного ранжирования (Cai et al., 2022, CIKM)
- Симанс: Простые неоднозначные негативы выборки для плотного извлечения текста (Zhou et al., 2022, EMNLP)
- Debiased Contrastive Learning о неконтролируемых представлениях предложения (Zhou et al., 2022, ACL)
- Восстановление золота из черного песка: многоязычный плотный отрывок с твердыми и ложными отрицательными образцами (Shen et al., 2022, Emnlp)
- Ноль-выстрел/несколько выстрелов
- Поиск нулевого выстрела на основе встраивания через генерацию запросов (Liang et al., 2020, Arxiv)
- Поиск нуронного отрывка с помощью домена с доменом-синтетическим генерацией вопросов (Ma et al., 2020, QGEN , ARXIV)
- На пути к надежным нейронным моделям с синтетическим предварительным тренировком (Reddy et al., 2021, Arxiv)
- BEIR: гетерогенный эталон для нулевой оценки моделей поиска информации (Thakur et al., 2021, Neurips)
- НЕОБХОДИТЕЛЬНЫЕ ПЕРЕДАТЬ ПРОТИВ НА ИНВЕРГАЦИОННЫЕ ИНВИАЛЬНЫЕ ПРЕДСТАВИТЕЛЬНЫЕ ПРЕДСТАВЛЕНИЯ (XIN et al., 2021, ARXIV, MODIR )
- Большие двойные кодеры являются обобщаемыми ретриверами (Ni et al., 2022, EMNLP, DTR )
- Семантика вне домена на помощь! Модели с нулевым выстрелом (Chen et al., 2022, ECIR)
- Inpres: увеличение данных для поиска информации с использованием моделей крупных языков (Bonifacio et al., 2022, Arxiv)
- На пути к неконтролируемому плотному поиску информации с контрастным обучением (Izacard et al., 2021, Arxiv, Introver )
- GPL: Генеративная псевдо -маркировка для неконтролируемой адаптации доменной домены плотного поиска (Wang et al., 2022, NAACL)
- Обучение получению отрывков без надзора (Ram et al., 2021, Arxiv, Spider )
- Тщательное исследование на плотном поиске с нулевым выстрелом (Ren et al., 2022, Arxiv)
- Встроения текста и кода в отличие от предварительного обучения (Neelakantan et al., 2022, Arxiv)
- DisEneangled моделирование домена и актуальность для адаптируемого плотного поиска (Zhan et al., 2022, Arxiv)
- Заглавный срок: несколько выстрелов из 8 примеров (Dai et al., 2022, Arxiv)
- Вопросы - это все, что вам нужно для обучения плотного отрыва от прохода (Sachan et al., 2022, Tacl)
- Hyper: многозадачная гипер-продуманная тренировка позволяет обеспечить масштабное извлечение обобщения (Cai et al., 2023, ICLR)
- Coco-Dr: борьба с сдвигами распределения в плотном поиске с нулевым выстрелом с контрастным и дистрибутивным обучением (Yu et al., 2022, Emnlp)
- Проблемы в обобщении в ответе на вопрос открытой области (Liu et al., 2022, NAACL)
- Надежность
- На пути к прочному плотному поиску через местное выравнивание ранжирования (Chen et al., 2022, IJCAI)
- Работа с опечатками для извлечения и ранжирования прохода на основе Берта (Zhuang et al., 2021, EMNLP)
- Оценка надежности поисковых трубопроводов с генераторами изменения запросов (Penha et al., 2022, Ecir)
- Анализ надежности двойных кодеров для плотного поиска против ошибок (Sidiropoulos et al., 2022, Sigir)
- Характерберт и самообладание для улучшения надежности плотных ретриверов на запросах с помощью опечаток (Zhuang et al., 2022, Sigir)
- Bert Rankers - хрупкие: исследование с использованием возмущений состязательных документов (Wang et al., 2022, Ictir)
- Оформление порядка: подражание состязательных атак для моделей нейронного ранжирования Blackbox (Liu et al., 2022, Arxiv)
- Опечатки с учетом узкого места для прочного плотного поиска (Zhuang et al., 2023, Arxiv)
- Анализ зондирования
- Проклятие плотного низкоразмерного извлечения информации для больших размеров индексов (Reimers et al., 2021, ACL)
- Простая и эффективная неконтролируемая устранение избыточности для сжатия плотных векторов для поиска прохода (Ma et al., Emnlp, 2021, избыточность )
- BEIR: гетерогенный эталон для нулевой оценки моделей поиска информации (Thakur et al., 2021, Neurips, переносимость )
- Высокая фраза, осведомленная о плотном поиске: может ли плотный ретривер подражать редкому? (Chen et al., 2021, Arxiv)
- Простые ориентированные на сущность вопросы бросают вызов плотным ретриверам (Sciavolino et al., 2021, Emnlp)
- Интерпретация плотного поиска как смесь тем (Zhan et al., 2021, Arxiv)
- Анализ атрибуции энкодера для плотного ретривера в ответе на вопрос с открытым доменом (Li et al., 2022, Trustnlp)
- Изотропное представление может улучшить плотный поиск (Jung et al., 2022, Arxiv)
- Быстрое обучение
- Полу-сиамская модель нейронного ранжирования с биамским биодером с использованием легкой тонкой настройки (Jung et al., 2022, www)
- Разбросанный или подключенный? Оптимизированный подход к настройке для параметра для поиска информации (Ma et al., 2022, CIKM)
- DPTDR: Глубокая оперативная настройка для плотного извлечения прохода (Tang et al., 2022, Arxiv)
- Параметр, определенный настройки быстрого настройки, делает обобщенные и калиброванные ретриверы нейронного текста (Tam et al., 2022, Arxiv)
- NIR-PROMPT: многозадачная структура обучения для поиска нейронной информации (Xu et al., 2022, Arxiv)
- Большая языковая модель для поиска
- Точный нулевой плотный поиск без релевантности метки (Gao et al., 2022, Arxiv)
- Другие
- HLATR: улучшить многоэтапное извлечение текста с помощью гибридного списка трансформатора реэнергики (Zhang et al., 2022, Arxiv)
- Asyncval: инструментарий для асинхронно проверки плотных контрольно -пропускных пунктов во время обучения (Zhuang et al., 2022, Sigir)
Гибридные методы поиска
- Слово-вводный
- Монолингальные и межязычные модели поиска информации, основанные на (двуязычных) встроенных словах (Vulic et al., 2015, Sigir, линейно комбинация )
- Слово внедряет обобщенную языковую модель для поиска информации (Ganguly et al., 2015, Sigir, GLM )
- Представление документов и запросов в качестве наборов встроенных слов векторов для поиска информации (Roy et al., 2016, Sigir, линейно объединить )
- Двойная космическая модель для ранжирования документов (Mitra et al., 2016, www, desm_mixture , линейно объединить )
- Вне проторенного пути: давайте заменим поиск на основе терминов на поиск K-NN (Boytsov et al., 2016, CIKM, BM25+Model )
- Обучение гибридным представлениям для получения семантически эквивалентных вопросов (Santos et al., 2015, ACL, Bow-CNN )
- Ответ на вопрос с открытым доменом в режиме реального времени с помощью индекса фразы с плотной фразой (Seo et al., 2019, ACL, Denspi )
- Контекстуализированные разреженные представления для ответа на вопрос в режиме реального времени (Lee et al., 2020, ACL, SPARC )
- CORT: дополнительные рейтинги от трансформаторов (Wrzalik et al., 2020, NAACL, CORT_BM25 )
- Разреженные, плотные и внимательные представления для поиска текста (Luan et al., 2020, Tacl, Me-Hybrid )
- Дополнение лексической модели поиска с семантическими остаточными вставками (Gao et al., 2020, ECIR, Clear )
- Использование семантического и лексического сопоставления для улучшения отзыва систем поиска документов: гибридный подход (Kuzi et al., 2020, Arxiv, Hybrid )
- Несколько кратких заметок о DeepImpact, катушке и концептуальной основе для методов поиска информации (Lin et al., 2021, Arxiv, Unicoil )
- Контекстуализированная автономная релевантная взвешивание для эффективного и эффективного извлечения нейрода (Chen et al., 2021, Sigir)
- Прогнозирование компромиссов эффективности/эффективности для выбора стратегии плотного и разреженного поиска (Arabzadeh et al., 2021, CIKM)
- Индексы перенесенного вперед для эффективного ранжирования документов (Leonhardt et al., 2021, Arxiv)
- Уплотнительные редкие представления для поиска прохода путем репрезентативного нарезания (Lin et al., 2021, Arxiv)
- Университет: универсальный ретривер для крупномасштабного поиска (Shen et al., 2022, Arxiv)
Другие ресурсы
Другие задачи
- Поиск электронной коммерции
- Глубокая процентная сеть для прогнозирования скорости кликов (Zhou et al., 2018, KDD, DIN )
- От семантического поиска до парного рейтинга: применение глубокого обучения в поиске электронной коммерции (Li et al., 2019, Sigir, Jingdong)
- Многородная сеть с динамической маршрутизацией для рекомендаций в Tmall (Li et al., 2019, Cikm, Mind , Tmall)
- На пути к персонализированному и семантическому поиску: сквозное решение для поиска электронной коммерции посредством встраивания обучения (Zhang et al., 2020, Sigir, Dpsr , Jingdong)
- Глубокая многоэтажная сеть для прогнозирования скорости кликов (Xiao et al., 2020, CIKM, DMIN )
- Глубокий поиск: сквозная модель обучаемой структуры для крупномасштабных рекомендаций (Gao et al., 2020, Arxiv)
- Поиск продукта на основе встраивания в поиске Taobao (Li et al., 2021, KDD, Taobao)
- Охватывание структуры в данных для поиска семантического продукта в миллиардном масштабе (Lakshman et al., 2021, Arxiv, Amazon)
- Спонсируемый поиск
- MOBIUS: К следующему поколению соответствия запросов в спонсируемом поиске Baidu (Fan et al., 2019, KDD, Baidu)
- Поиск изображения
- Хэширование бинарной нейронной сети для поиска изображений (Zhang et al., 2021, Sigir, Bnnh )
- Глубокий самоадаптивный хешинг для поиска изображения (Lin et al., 2021, Cikm, DSAH )
- Отчет о первом семинаре Hipstir о будущем поиска информации (Dietz et al., 2019, Sigir, Workshop)
- Давайте измерем время выполнения! Расширение инфраструктуры ИК -воспроизведения, включающую аспекты производительности (Hofstätter et al., 2019, Sigir)
- Поиск на основе встраивания в поисках Facebook (Huang et al., 2020, KDD, EBR )
- Обучение k-way d-димерные дискретные коды для компактных встроенных представлений (Chen et al., 2018, ICML)
Наборы данных
- 【MS MARCO】 MS MARCO: Набор данных по пониманию прочитанного машины с человеком
- 【Car Car】 Complex Complex Reanse Replieval Обзор
- 【Trec DL】 Обзор TREC 2019 Deep Learning Track
- 【COVID TREC】 TREC-COVID: Создание сбора тестов по поиску пандемии
Методы индексации
- Дерево на основе
- Многомерные бинарные поисковые деревья, используемые для ассоциативного поиска (1975, KD Tree )
- Раздражать
- На основе хешина
- Приблизительные ближайшие соседи: к удалению проклятия размерности (1998, LSH )
- Основанный на квантовании
- Квантование продукта для поиска ближайшего соседа (2010, PQ )
- Оптимизированная квантование продукта (2013, OPQ )
- График на основе
- Навигация в небольшом мире (2000, Новый Южный Уэльс )
- Эффективный и надежный приблизительный поиск ближайшего соседа с использованием иерархических судоходных малых графиков мира (2018, HNSW )
- Наборы инструментов
- FAISS: библиотека для эффективного поиска сходства и кластеризации плотных векторов
- SPTAG: библиотека для быстрого приблизительного поиска ближайшего соседа
- OpenMatch: пакет с открытым исходным кодом для поиска информации
- Pyserini: Python Toolkit для воспроизводимой исследования поиска информации с редкими и плотными представлениями
- Elasticsearch


