Modèles sémantiques impressionnants pour la récupération de première étape
Note:
- Une liste organisée de documents impressionnants pour la récupération sémantique , y compris certaines méthodes précoces et des modèles neuronaux récents pour les tâches de récupération de l'information (par exemple, la récupération ad hoc, l'AQ en domaine ouvert, la QA communautaire et la conversation automatique).
- Pour les chercheurs qui souhaitent acquérir des modèles sémantiques pour les étapes de réévaluation, nous renvoyons les lecteurs à la superbe enquête Neuir par Guo et .
- Toute rétroaction et contribution sont les bienvenues, veuillez ouvrir un problème ou me contacter.
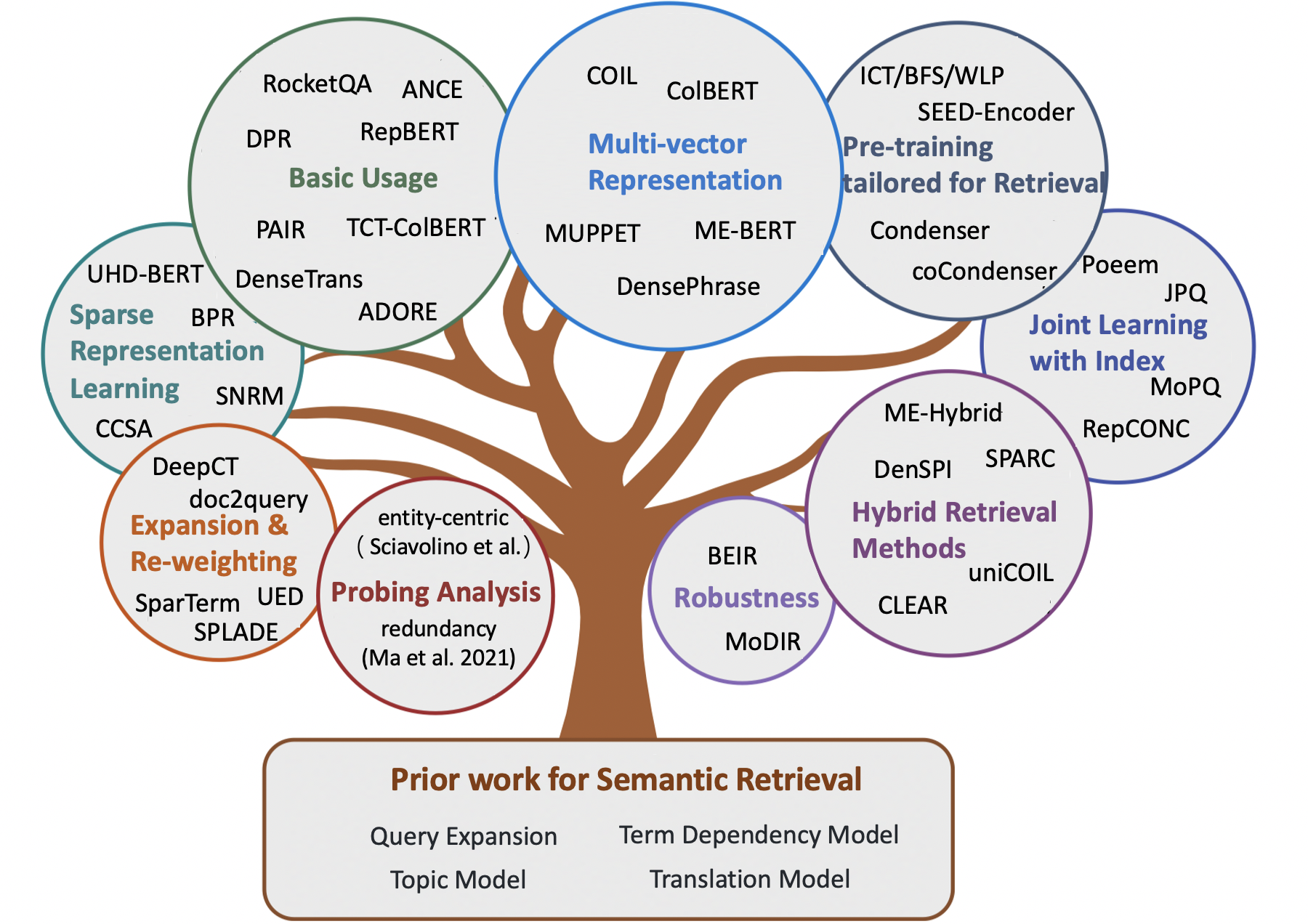
Contenu
- Document d'enquête
- Chapitre 1: récupération basée sur les termes classiques
- Chapitre 2: Méthodes précoces pour la récupération sémantique
- Extension de requête
- Expansion du document
- Modèle de dépendance à terme
- Modèle de sujet
- Modèle de traduction
- Chapitre 3: Méthodes neuronales pour la récupération sémantique
- Méthodes de récupération clairsemées
- Méthodes de récupération denses
- Méthodes de récupération hybride
- Chapitre 4: Autres ressources
- Autres tâches
- Ensembles de données
- Méthodes d'indexation
Document d'enquête
- Matchage sémantique dans la recherche (Li et al., 2014)
- Transformers pré-entraînés pour le classement du texte: Bert et au-delà (Lin et al., 2021, arxiv)
- Modèles sémantiques pour la récupération de première étape: une revue complète (Guo et al., 2021, tois)

- Un cadre conceptuel proposé pour une approche de représentation de la récupération de l'information (Lin et al., 2021, arXiv)
- Méthodes de pré-formation dans la recherche d'informations (Fan et al., 2022, arxiv)
- Récupération de texte dense basée sur des modèles de langage pré-entraînés: une enquête (Zhao et al., 2022, arxiv)
- Récupération de dense à faible ressource pour la question des questions du domaine ouvert: une enquête complète (Shen et al., 2022, Arxiv)
- Notes de cours sur la récupération des informations neuronales (Tonellotto et al., 2022, arXiv)
Récupération classique basée sur des termes
- Un modèle d'espace vectoriel pour l'indexation automatique (1975, VSM )
- Développements dans la récupération automatique de texte (1991, TFIDF )
- Approches de poids à terme dans la récupération automatique de texte (1988, TFIDF )
- Pondération de pertinence des termes de recherche (1976, BIM )
- Une base théorique pour l'utilisation des données de cooccurrence dans la recherche d'informations (1997, modèle de dépendance aux arbres )
- Le cadre de pertinence probabiliste: BM25 et au-delà (2010, BM25 )
- Une approche de modélisation linguistique de la recherche d'informations (1998, QL )
- Modèles linguistiques statistiques pour la récupération de l'information (2007, LM pour IR )
- Modèle de langue hypergéométrique et fonction de notation de type ZIPF pour la recherche de similitude de document Web (2010, LM pour IR )
- Modèles probabilistes de récupération de l'information basés sur la mesure de la divergence de l'aléatoire (2002, DFR )
Les premières méthodes de récupération sémantique
Extension de requête
- Modèle mondial
- Associations de mots mot dans les systèmes de récupération de documents (1969)
- Extension de requête basée sur le concept (1993)
- Extension de requête en utilisant des relations lexicales-sémantiques (1994)
- Utilisation des contextes de requête dans la recherche d'informations (2007)
- Modèle local
- Retour de pertinence dans la recherche d'informations (1971, Rocchio PRF )
- Rétroaction basée sur le modèle Dans l'approche de modélisation des langues de la récupération des informations (2001, modèle de minimisation de la divergence )
- UMass à TREC 2004: Novely and Hard (2004, RM3 pour PRF )
- Sélection de bons termes d'expansion pour les commentaires de pseudo-relance (2008, PRF)
- Une étude comparative des méthodes d'estimation des modèles de langage de requête avec pseudo rétroaction (2009)
- Retour pseudo-réévolution basé sur la factorisation de la matrice (2016)
- Réduire le risque d'expansion des requêtes via une optimisation contrainte une robuste (2009 , Problème de dérive de requête )
- Extension de requête en utilisant l'analyse des documents locaux et globaux (2017)
Expansion du document
- Structure du corpus, modèles de langue et récupération des informations ad hoc (2004)
- Récupération basée sur des grappes à l'aide de modèles de langage (2004)
- Renseignante des informations sur le modèle linguistique avec expansion des documents (2006)
- Extension de document basée sur WordNet pour IR robuste (2010)
- Amélioration de la récupération des textes courts grâce à l'expansion des documents (2012)
- Extension de document à l'aide de collections externes (2017, basées sur WordNet )
- Extension du document par rapport à l'extension de requête pour la récupération ad hoc (2005)
Modèle de dépendance à terme
- Expériences dans l'indexation automatique des phrases pour la récupération de documents: une comparaison des méthodes syntaxiques et non syntaxiques (1987, VSM + Term Dependency ))
- Approches de poids à terme dans la récupération automatique de texte (1988, VSM + Terme Dependency )
- Une analyse des phrases statistiques et syntaxiques (1997, VSM + Terme Dependency )
- Un modèle probabiliste de récupération de l'information: développement et expériences comparatives (2000, VSM + Term Dependency ))
- Classement de pertinence à l'aide des noyaux (2010, BM25 + Terme Dependency )
- Un modèle de langue générale pour la récupération de l'information (1999, LM + Term Dependency ))
- Modèles de langage boirm pour la récupération de documents (2002, LM + Term Dependency )
- Capturation de dépendances à terme à l'aide d'un modèle de langue basé sur les arbres de phrase (2002, LM + dépendance à terme )
- Modèle de langage de dépendance pour la récupération de l'information (2004, LM + Term Dependency )
- Une théorie générative de la pertinence (2008)
- Un modèle de champ aléatoire de Markov pour les dépendances à terme (2005, SDM )
Modèle de sujet
- Modèle d'espace vectoriel généralisé dans la recherche d'informations (1985, GVSM )
- Indexation par analyse sémantique latente (1990, LSI pour IR )
- Indexation sémantique latente probabiliste (2017, PLSA, combinant linéairement )
- Structure du corpus, modèles de langue et récupération des informations ad hoc (2004, lissage )
- Régulariser les scores de récupération ad hoc (2005, lissage )
- Modèles de documents basés sur la LDA pour la récupération ad hoc (2006, LDA pour IR et LDA pour le lissage LM )
- Une étude comparative de l'utilisation des modèles de sujet pour la récupération de l'information (2009, lissage )
- Étude des performances des tâches des modèles de sujets probabilistes: une étude empirique de PLSA et LDA (2010)
- L'indexation sémantique latente (LSI) échoue pour les collections TREC (2011)
Modèle de traduction
- Récupération des informations comme traduction statistique (1999)
- Estimation des modèles de traduction statistique basés sur des informations mutuelles pour la récupération des informations ad hoc (2010)
- Modèles de traduction basés sur les clics pour la recherche Web: des modèles de mots aux modèles de phrase (2010)
- Analyse axiomatique du modèle de langue de traduction pour la récupération de l'information (2012)
- Réécriture de requête en utilisant la traduction automatique statistique monolingue (2010, pour l'expansion de la requête )
- Vers des modèles de traduction basés sur des concepts utilisant des journaux de recherche pour l'expansion des requêtes (2012, pour l'extension de requête )
Méthodes neuronales pour la récupération sémantique
Méthodes de récupération clairsemées
- Terme Re-poids
- Apprendre à reconder les termes avec des représentations distribuées (Zheng et al., 2015, Sigir, Deeptr )
- Intégrer et évaluer les incorporations de mots neuronaux dans la recherche d'informations (ZucCon et al., 2015, ADCS, NTLM )
- Discrimination du terme d'apprentissage (Frej et al, 2020, Sigir, TDV )
- Estimation de la phrase / du passage du contexte d'importance pour la récupération de première étape (Dai et al., 2019, Arxiv, Deepct )
- Pondération du terme au contexte pour la récupération de passage au premier étage (Dai et al., 2020, Sigir, Deepct )
- Implications d'efficacité de la pondération du terme pour la récupération de passage (Mackenzie et al., 2020, Sigir, Deepct )
- Pondération du terme de document contextuel pour la recherche ad-hoc (Dai et al., 2020, www, HDCT )
- Quelques brèves notes sur DeepImpact, Coil et un cadre conceptuel pour les techniques de recherche d'informations (Lin et al., 2021, Arxiv, Unicoil )
- Expansion
- Expansion du document par prédiction des requêtes (Nogueira et al., 2019, Arxiv, Doc2Query )
- De Doc2Query à DoctttttQuery (Nogueira et al., 2019, Arxiv, DoctttttQuery )
- Un cadre de pré-formation unifié pour le classement et l'expansion des passagers (Yan et al., 2021, aaai, ued )
- Récupération de la génération de la génération pour la réponse aux questions du domaine ouvert (Mao et al., 2020, ACL, GAR , Expansion de la requête )
- Extension + Terme Re-Weighting
- Extension par prédiction d'importance avec la contextualisation (Macavaney et al., 2020, Sigir, Epic )
- SPARTERM: Représentation clairsemée des termes d'apprentissage pour la récupération de texte rapide (Bai et al., 2020, Arxiv, Sparterm ))
- Salle: Modèle de lexical et d'expansion clairsemé pour le classement de première étape (Formal et al., 2021, Sigir, Salle )
- Salle V2: Modèle de lexical et d'expansion clairsemé pour la recherche d'informations (Formal et al., 2021, Arxiv, Sparlev2 )
- Les impacts du passage d'apprentissage pour les indices inversés (Mallia et al., 2021, Sigir, DeepiMapct )
- Tilde: Terme Modèle de vraisemblance indépendant pour la re-rantement du passage (Zhuang et al., 2021, Sigir, Tilde )
- Re-Ranking de passage rapide avec une correspondance de terme exact contextualisée et une expansion efficace de passage (Zhuang et al., 2021, Arxiv, Tildev2 )
- SPADE: Amélioration des représentations clairsemées à l'aide d'un encodeur à double document pour la récupération en première étape (Choi et al., 2022, CIKM)
- Représentation clairsemée Apprentissage
- Hachage sémantique (Salakhutdinov et al., 2009)
- De la relance neuronale au classement neuronal: apprendre une représentation clairsemée pour l'indexation inversée (Zamani et al., 2018, CIKM, SNRM )
- UHD-BERT: Représentations clairsemées ultra-dimensionnelles à godet pour le classement complet (Jang et al., 2021, Arxiv, Uhd-Bert )
- Récupération de passage ef fi cace avec hachage pour la question de la question du domaine ouvert (Yamada et al., 2021, ACL, BPR )
- Code composite Autoencoders clairsemés pour la récupération de première étape (Lassance et al., 2021, Sigir, CCSA )
Méthodes de récupération denses
- Basé sur les mots
- Aggrégation des incorporations de mots continues pour la récupération d'informations (Clinchant et al., 2013, ACL, FV )
- Modèles de récupération d'informations monolinguaux et interdiusables basés sur des incorporations de mots (bilingues) (Vulic et al., 2015, Sigir)
- Similité du texte court avec les incorporations de mots (Kenter et al., 2015, CIKM, OOB )
- Un modèle d'espace d'intégration double pour le classement des documents (Mitra et al., 2016, Arxiv, DESM )
- Suggestion efficace de réponse au langage naturel pour la réponse intelligente (Henderson et al., 2017, arxiv)
- Récupération de bout en bout dans un espace continu (Gillick et al., 2018, arxiv)
- Question indexée par la phrase Réponse: un nouveau défi pour la compréhension des documents évolutifs (Seo et al., 2018, EMNLP, PIQA )
- Récupération de passage dense pour la question de la question du domaine ouvert (Karpukhin et al., 2020, EMNLP, DPR )
- Génération auprès de la récupération pour les tâches NLP à forte intensité de connaissances (Lewis et al., 2020, Nips, Rag )
- Repbert: Intégration de texte contextualisé pour la récupération de première étape (Zhan et al., 2020, Arxiv, Repbert )
- CORT: classement complémentaire de Transformers (Wrzalik et al., 2020, NAACL, CORT )
- DC-BERT: Question et document de découplage pour un codage contextuel efficace (Nie et al., 2020, Sigir, DC-Bert )
- Récupération neuronale pour répondre à des questions avec une augmentation de données supervisée à l'attention croisée (Yang et al., 2021, ACL, Augmentation des données )
- Apprentissage contrastif négatif le plus proche du voisin pour la récupération de texte dense (Xiong et al., 2020, Arxiv, Ace )
- Apprendre à récupérer: comment former un modèle de récupération dense efficacement et efficacement (Zhan et al., 2020, Arxiv, Ltre )
- Glow: réseau d'auto-agence d'auto-atténuation globale pour Web (Shan et al, 2020, Arxiv, Glow )
- Une approche de formation optimisée de la récupération de passage dense pour la question des questions du domaine ouvert (Qu et al., 2021, ACL, Rocketqa )
- Enseignant efficacement un retriever dense efficace avec un échantillonnage de conscience de sujet équilibré (Hofstätter et al., 2021, Sigir, tas-équilibré )
- Optimisation de la formation de modèle de récupération dense avec des négatifs durs (Zhan et al., 2021, Sigir, Star / Adore )
- Retrievale dense conversationnelle à quelques coups (Yu et al., 2021, Sigir)
- Apprentissage des représentations denses des phrases à grande échelle (Lee et al., 2021, ACL, densephrases )
- Retalie dense plus robuste avec le double apprentissage contrasté (Lee et al., 2021, ictir, danse )
- Paire: tirant parti de la relation de similitude centrée sur le passage pour l'amélioration de la récupération de passage dense (Ren et al., 2021, ACL, paire )
- Supervision guidée par la pertinence pour OpenQA avec Colbert (Khattab et al., 2021, Tacl, Colbert-QA )
- Formation de bout en bout du lecteur multi-documents et Retriever pour une question de questions-domaines ouvertes (Sachan et al., 2021, Arxiv, Emdr ^ 2 )
- Amélioration des représentations de la requête pour une récupération dense avec une rétroaction de pertinence pseudo (Yu et al, 2021, CIKM, ANCE-PRF )
- Retour pseudo-réévolution pour la représentation multiple Retrievale dense (Wang et al., 2021, ICTIR, Colbert-PRF )
- Un rang sémantique discriminant pour la récupération de questions (Cai et al., 2021, ictir, densetrans ))
- Découplage de représentation pour la récupération de passage du domaine ouvert (Wu et al., 2021, arXiv)
- ROCKETQAV2: Une méthode de formation conjointe pour la récupération de passage dense et le record de passage (Ren et al., 2021, EMNLP, RocketQav2 )
- Formation ef fi cace des modèles de récupération à l'aide de cache négatif (Lindgren et al., 2021, Neirips)
- Formation en plusieurs étapes avec un contraste négatif amélioré pour la récupération du passage neuronal (Lu et al., 2021, EMNLP)
- Amélioration de la récupération à grande échelle basée sur l'intégration via l'amélioration de l'étiquette (Liu et al., 2021, EMNLP)
- Récupération hiérarchique dense pour répondre aux questions du domaine ouvert (Liu et al., 2021, EMNLP)
- Représentation des documents bi-granulaires progressivement optimisés pour la récupération basée sur l'incorporation évolutive (Xiao er al., 2022 , www)
- LED: Retriever dense éclairé en lexique pour la récupération à grande échelle (Zhang et al., 2023, www)
- En aggravage: une approche simple de la représentation textuelle agrégée pour une récupération de passage dense robuste (Lin et al., 2022, arXiv)
- Apprentissage contrastif conscient de la phrase pour la récupération de passage du domaine ouvert (Wu et al., 2022, ACL)
- Spécialisation de la tâche pour la récupération dense ef fi cace et robuste pour la réponse aux questions du domaine ouvert (Cheng et al., 2022, arxiv)
- Distillation des connaissances
- Distillant des représentations denses pour le classement en utilisant des enseignants à couplage serré (Lin et al., 2020, Arxiv, TCT-Colbert )
- Connaissances de distillation pour les bots de chat basés sur la récupération rapide (Tahami et al., 2020, Sigir)
- Distillant les connaissances du lecteur à Retriever pour répondre aux questions (Izacard et al., 2020, arXiv)
- Retriever est-il simplement un approximateur du lecteur? (Yang et al., 2020, arxiv)
- Amélioration des modèles de classement des documents bi-encodeurs avec deux rangs et distillation multi-enseignants (Choi et al., 2021, Sigir, TRMD )
- Amélioration des modèles de classement neuronal efficaces avec distillation de connaissances inter-architectures (Hofstätter et al., 2021, arxiv, marge-mse perte )
- Twinbert: Distilling Knowledge to Twin-structuré Modèles Bert comprimés pour une récupération à grande échelle (Lu et al., 2022, arxiv)
- Représentation multi-vecteur
- Récupération de paragraphe multi-HOP pour la réponse aux questions du domaine ouvert (Feldman et al., 2019, ACL, Muppet )
- Représentations clairsemées, denses et attentionnelles pour la récupération de texte (Luan et al., 2020, Tacl, Me-Bert )
- Colbert: Recherche de passage efficace et efficace via une interaction tardive contextualisée sur Bert (Khattab et al., 2020, Sigir, Colbert )
- Coil: Revisitez la correspondance lexicale exacte dans la récupération des informations avec la liste inversée contextualisée (Gao et al., 2021, NaCl, Coil )
- Améliorer les représentations de documents en générant des incorporations de requête pseudo pour une récupération dense (Tang et al., 2021, ACL)
- La récupération des phrases apprend également la récupération du passage (Lee et al., 2021, EMNLP, densephrases )
- Requête dans l'élagage de l'intégration pour une récupération dense (Tonellotto et al., 2021, CIKM)
- Représentation de documents multi-visualités pour la récupération dense du domaine ouvert (Zhang et al., 2022, ACL)
- Colbertv2: récupération efficace et ef fi cace via une interaction tardive légère (Santhanam, 2022, NAACL)
- Apprendre diverses représentations de documents avec des interactions de requête profonde pour la récupération dense (Li et al., 2022, arXiv)
- Modèle basé sur la représentation du texte à grain de sujet pour la récupération de documents (Du et al., 2022, ICANN)
- Accélérer les modèles basés sur l'interaction
- Intégration de l'hypothèse d'indépendance du terme de requête pour une récupération et un classement efficaces à l'aide de réseaux de neurones profonds (Mitra et al., 2019, arXiv)
- Classement neuronal efficace basé sur l'interaction avec le hachage sensible de la localité (Ji et al., 2019, www)
- Poly-Encoders: Architectures et stratégies de pré-formation pour une notation multisence rapide et précise (Humeau et al., 2020, ICLR, Poly-Encoders )
- Cadre de classement basé sur les transfomères modularisée (Gao et al., 2020, EMNLP, MORES )
- Re-Ranking de documents efficaces pour les transformateurs par des représentations de terme pré-computantes (Macavaney et al., 2020, Sigir, PretrTr )
- Déformateur: décomposition de transformateurs pré-formés pour répondre à des questions plus rapides (Cao et al., 2020, ACL, déformer )
- Sparta: Question ef fi cace du domaine ouvert répondant via la récupération de transformateur clairsemérandant (Zhao et al., 2020, arXiv, Sparta )
- CONFORMER-KERNEL AVEC INDÉPENSION DU TERME DE RESQUE POUR LA RÉTENTION DES DOCUMENTS (MITRA ET AL., 2020, ARXIV)
- Inttower: La prochaine génération de modèle à deux points pour le système pré-rangée (Li et al., 2022, CIKM)
- Pré-formation
- Récupération latente pour une question de réponse à un domaine ouvert faiblement supervisé (Lee et al., 2019, ACL, ORQA )
- Modèle de langue de la récupération Pré-formation du langage auprès de la récupération (Guu et al., 2020, ICML, royaume )
- Tâches de pré-formation pour la récupération à grande échelle basée sur l'intégration (Chang et al., 2020, ICLR, BFS + WLP + MLM )
- Votre modèle de langue est-il prêt pour une représentation dense ajustée? (Gao et al., 2021, EMNLP, condenseur )
- Modèle de langue conscient de Corpus non supervisé pré-formation pour la récupération de passage dense (Gao et al., 2021, arXiv, cocondenser )
- Moins c'est plus: pré-formation d'un codeur siamois fort utilisant un décodeur faible (Lu et al., 2021, EMNLP, Encodeur de semences )
- Modèle de langage pré-formé pour la récupération de l'échelle Web dans la recherche de Baidu (Liu et al., 2021, KDD)
- Pré-formation pour la récupération ad-hoc: l'hyperlien est également avez besoin (Ma et al., 2021, CIKM, harp )
- Pré-entraînant un codeur de texte discriminant pour une récupération dense via une prédiction de portée contrastive (Ma et al., 2022, Sigir)
- TSDAE: Utilisation de l'autocodeur séquentiel à base de transformateurs pour l'apprentissage d'intégration de phrases non supervisé (Wang et al., 2021, EMNLP)
- Masque contextuel Auto-Encodeur pour une récupération de passage dense (Wu et al., 2022, Arxiv)
- SIMLM: pré-formation avec goulot d'étranglement de représentation pour récupération de passage dense (Wang et al., 2022, arXiv)
- Lexmae: lexique-bottlened pré-entraînement pour une récupération à grande échelle (Shen et al., 2022, arxiv)
- Une approche pré-formation contrastive pour apprendre l'autoencodeur discriminant pour la récupération dense (Ma et al., 2022, CIKM)
- Retomae: Modèles de langage orienté vers la récupération avant la formation via le cocodeur automatique masqué (Xiao et Liu et al., 2022, EMNLP)
- Modèle de langage pré-formation de masquage orienté vers la récupération pour la récupération de passage dense (Long et al., 2022, arxiv)
- Laprador: Retriever dense prétraité non supervisé pour la récupération de texte zéro-shot (Xu et al., 2022, ACL)
- Autoencoders masqués comme apprenants unifiés pour la représentation pré-formée des phrases (Liu et al., 2022, arXiv)
- Master: Les autoencoders masqués pré-formés multi-tâches sont de meilleurs retrievers dense (Zhou et al., 2023, ICLR)
- COT-MAE V2: Encodeur auto-masqué contextuel avec modélisation multi-visualités pour la récupération de passage (Wu et al., 2023, arxiv)
- COT-MOTE: Exploration de la pré-formation de l'encodeur automatique masqué contextuel avec des experts de mélange de textuels pour la récupération de passage (Ma et al., 2023, arXiv)
- Apprentissage conjoint avec index
- Apprentissage conjoint du modèle de récupération profonde et de l'indice d'intégration basé sur la quantification des produits (Zhang et al., 2021, Sigir, Poeem )
- Optimisation conjointe de l'encodeur de requête et de la quantification du produit pour améliorer les performances de récupération (Zhan et al., 2021, CIKM, JPQ )
- Quantification du produit axé sur correspondance pour la récupération ad hoc (Xiao et al., 2021, EMNLP, MOPQ )
- Apprentissage des représentations discrètes via un regroupement contraint pour une récupération dense efficace et efficiente (Zhan et al, 2022, WSDM, REPCONC )
- Apprentissage conjoint avec Ranker
- Formation de bout en bout des retrievers neuronaux pour la réponse aux questions du domaine ouvert (Sachan et al., 2021, ACL)
- Retriever adversarial Retriever pour une récupération de texte dense (Zhang et al., 2022, ICLR)
- Debias
- Apprendre des modèles de récupération denses robustes à partir d'étiquettes de pertinence incomplètes (Prakash et al., 2021, Sigir, Rance )
- Négatifs durs ou faux négatifs: corriger les biais de mise en commun dans la formation des modèles de classement neuronal (Cai et al., 2022, CIKM)
- Simans: Simple ambigu négatif échantillonnage pour une récupération de texte dense (Zhou et al., 2022, EMNLP)
- Apprentissage contrasté débias des représentations de phrases non supervisées (Zhou et al., 2022, ACL)
- Récupération de l'or du sable noir: récupération de passage dense multilingue avec des échantillons durs et faux négatifs (Shen et al., 2022, EMNLP)
- Zéro-shot / in-shot
- Récupération de récupération de zéro-tirs par l'incorporation par le biais de la génération de requêtes (Liang et al., 2020, Arxiv)
- Récupération de passage neuronal zéro via génération de questions synthétiques ciblées par domaine (Ma et al., 2020, QGEN , ARXIV)
- Vers des modèles de récupération neuronale robustes avec pré-formation synthétique (Reddy et al., 2021, arXiv)
- BEIR: Une référence hétérogène pour l'évaluation zéro-shot des modèles de récupération d'informations (Thakur et al., 2021, Neirips)
- Répartie dense zéro avec des représentations invariantes du domaine adversaire de la quantité de mouvement (Xin et al., 2021, arXiv, modir )
- Les grands encodeurs doubles sont des retrievers généralisables (Ni et al., 2022, EMNLP, DTR )
- Sémantique hors du domaine à la rescousse! Modèles de récupération hybride zéro-shot (Chen et al., 2022, ECIR)
- INPARS: Augmentation des données pour la récupération d'informations à l'aide de modèles de gros langues (Bonifacio et al., 2022, arxiv)
- Vers la récupération de l'information dense non supervisée avec un apprentissage contrastif (Izacard et al., 2021, arXiv, Contriever )
- GPL: Étiquetage de pseudo génératif pour l'adaptation du domaine non supervisé de la récupération dense (Wang et al., 2022, NAACL)
- Apprendre à récupérer des passages sans supervision (Ram et al., 2021, Arxiv, Spider )
- Un examen approfondi sur la récupération dense zéro-shot (Ren et al., 2022, arxiv)
- Les incorporations de texte et de code par pré-formation contrastive (Neelakantan et al., 2022, arXiv)
- Modélisation démêlée du domaine et pertinence pour la récupération dense adaptable (Zhan et al., 2022, arXiv)
- Insidegator: récupération dense à quelques coups à partir de 8 exemples (Dai et al., 2022, arXiv)
- Les questions sont tout ce dont vous avez besoin pour former un retour de passage dense (Sachan et al., 2022, tacl)
- HYPER: L'entraînement multitâche hyper-programmé permet une généralisation de récupération à grande échelle (Cai et al., 2023, ICLR)
- Coco-Dr: Combattre des changements de distribution dans une récupération dense zéro-shot avec un apprentissage contrastif et robuste à distribution (Yu et al., 2022, EMNLP)
- Défis en généralisation dans la question de la question du domaine ouvert (Liu et al., 2022, NAACL)
- Robustesse
- Vers une récupération dense robuste via l'alignement du classement local (Chen et al., 2022, ijcai)
- Traitant des fautes de frappe pour la récupération et le classement des passagers basés sur Bert (Zhuang et al., 2021, EMNLP)
- Évaluation de la robustesse des pipelines de récupération avec des générateurs de variation de requête (Penha et al., 2022, ECIR)
- Analyse de la robustesse des doubles encodeurs pour une récupération dense contre les fautes d'orthographe (Sidiropoulos et al., 2022, Sigir)
- Caracterbert et auto-enseignement pour améliorer la robustesse des retrievers denses sur les requêtes avec des fautes de frappe (Zhuang et al., 2022, Sigir)
- Bert Rankers est fragile: une étude utilisant des perturbations de documents contradictoires (Wang et al., 2022, ICTIR)
- Dés commande: Imitation Attaques adversaires pour les modèles de classement neuronal Blackbox (Liu et al., 2022, Arxiv)
- Pré-formation préalable à la typo
- Analyse de sondage
- La malédiction de la récupération des informations dense de faible dimension pour les grandes tailles d'indices (Reimers et al., 2021, ACL)
- Élimination de redondance simple et efficace non supervisée pour comprimer des vecteurs denses pour la récupération de passage (Ma et al., Emnlp, 2021, redondance )
- BEIR: Une référence hétérogène pour l'évaluation zéro-shot des modèles de récupération d'informations (Thakur et al., 2021, Neirips, transférabilité )
- Phrase saillante consciente de la récupération dense: un retriever dense peut-il imiter un clairsemé? (Chen et al., 2021, arxiv)
- Les questions simples centrées sur l'entité défient les récupérateurs denses (Sciavolino et al., 2021, EMNLP)
- Interprétation de la récupération dense comme un mélange de sujets (Zhan et al., 2021, arxiv)
- Une analyse d'attribution de l'encodeur pour le retriever de passage dense dans la question de la question du domaine ouvert (Li et al., 2022, Trustnlp)
- La représentation isotrope peut améliorer la récupération dense (Jung et al., 2022, arxiv)
- Apprentissage rapide
- Modèle de classement neuronal semi-siamois en bi-encodeur à l'aide d'un réglage fin léger (Jung et al., 2022, www))
- Dispersé ou connecté? Une approche de réglage optimisée économe en paramètres pour la récupération des informations (Ma et al., 2022, CIKM)
- DPTDR: réglage rapide de la récupération de passage dense (Tang et al., 2022, arXiv)
- Le réglage rapide des paramètres-effectifs fait des retrievers de texte neuronal généralisés et calibrés (Tam et al., 2022, arXiv)
- NIR-PROMPT: Un cadre de formation de récupération des informations neurales multi-tâches (Xu et al., 2022, Arxiv)
- Modèle de grande langue pour la récupération
- Retrie dense zéro précis sans étiquettes de pertinence (Gao et al., 2022, arxiv)
- Autres
- HLATR: Améliorer la récupération de texte en plusieurs étapes avec une liste de transformateurs conscients de la liste hybride (Zhang et al., 2022, arXiv)
- Asyncval: une boîte à outils pour valider de manière asynchrone des points de contrôle de récupération dense pendant la formation (Zhuang et al., 2022, Sigir)
Méthodes de récupération hybride
- Basé sur les mots
- Modèles de récupération d'informations monolinguaux et interdiusables basés sur des incorporations de mots (bilingues) (Vulic et al., 2015, Sigir, combinement linéairement )
- Modèle de langage généralisé basé sur l'intégration des mots pour la récupération de l'information (Ganguly et al., 2015, Sigir, GLM )
- Représentant des documents et des requêtes comme des ensembles de vecteurs intégrés de mots pour la récupération d'informations (Roy et al., 2016, Sigir, combiner linéairement )
- Un modèle d'espace d'intégration double pour le classement des documents (Mitra et al., 2016, www, desm_mixture , combiner linéairement )
- Hors des sentiers battus: Remplacement de la récupération basée sur des termes par la recherche K-NN (Boytsov et al., 2016, CIKM, BM25 + Traduction Model ))
- Apprentissage des représentations hybrides pour récupérer des questions sémantiquement équivalentes (Santos et al., 2015, ACL, Bow-CNN )
- Question du domaine ouvert en temps réel Réponse avec l'indice de phrase dense sassis (Seo et al., 2019, ACL, Denspi )
- Représentations clairsemées contextualisées pour la question des questions en temps ouvert en temps réel (Lee et al., 2020, ACL, SPARC )
- CORT: classement complémentaire de Transformers (Wrzalik et al., 2020, NAACL, CORT_BM25 )
- Représentations clairsemées, denses et attentionnelles pour la récupération de texte (Luan et al., 2020, Tacl, Me-Hybride )
- Complément Modèle de récupération lexicale avec intégres résiduels sémantiques (Gao et al., 2020, eCir, clair )
- Tirer parti de l'appariement sémantique et lexical pour améliorer le rappel des systèmes de récupération de documents: une approche hybride (Kuzi et al., 2020, arxiv, hybride )
- Quelques brèves notes sur DeepImpact, Coil et un cadre conceptuel pour les techniques de recherche d'informations (Lin et al., 2021, Arxiv, Unicoil )
- Pondération de pertinence hors ligne contextualisée pour une récupération neuronale efficace et efficace (Chen et al., 2021, Sigir)
- Prédire les compromis d'efficacité / efficacité pour la sélection de stratégie dense vs clairsemée de la stratégie (Arabzadeh et al., 2021, CIKM)
- Index en avant rapide pour un classement des documents efficace (Leonhardt et al., 2021, arxiv)
- Densification des représentations clairsemées pour la récupération de passage par tranchage représentatif (Lin et al., 2021, arXiv)
- Uni fi c.: un retriever uni fi é pour une récupération à grande échelle (Shen et al., 2022, arXiv)
Autres ressources
Autres tâches
- Recherche de commerce électronique
- Réseau de profondeur d'intérêt pour la prédiction des taux de clics (Zhou et al., 2018, KDD, DIN )
- De la récupération sémantique au classement par paire: application de l'apprentissage en profondeur dans la recherche de commerce électronique (Li et al., 2019, Sigir, Jingdong)
- Réseau multi-intérêts avec routage dynamique pour recommandation chez Tmall (Li et al., 2019, CIKM, Mind , Tmall)
- Vers la récupération personnalisée et sémantique: une solution de bout en bout pour la recherche de commerce électronique via l'apprentissage de l'intégration (Zhang et al., 2020, Sigir, DPSR , Jingdong)
- Réseau multi-intérêt profond pour la prédiction du taux de clics (Xiao et al., 2020, CIKM, DMIN )
- Retalie profonde: un modèle de structure apprenable de bout en bout pour des recommandations à grande échelle (Gao et al., 2020, arxiv)
- Recherche de produits basée sur l'intégration dans Taobao Search (Li et al., 2021, KDD, Taobao)
- Embrassant la structure dans les données pour la recherche de produits sémantiques à l'échelle milliard (Lakshman et al., 2021, Arxiv, Amazon)
- Recherche parrainée
- Mobius: Vers la prochaine génération de matchs de requête-AD dans la recherche parrainée de Baidu (Fan et al., 2019, KDD, Baidu)
- Récupération d'image
- Hachage du réseau neuronal binaire pour la récupération d'image (Zhang et al., 2021, Sigir, BNNH )
- Hachage d'auto-adaptation profond pour la récupération d'image (Lin et al., 2021, CIKM, DSAH )
- Rapport sur le premier atelier Hipstir sur l'avenir de la récupération de l'information (Dietz et al., 2019, Sigir, atelier)
- Mesurer le temps d'exécution! Extension de l'infrastructure de réplicabilité IR pour inclure des aspects de performance (Hofstätter et al., 2019, Sigir)
- Retalie basée sur l'intégration dans Facebook Search (Huang et al., 2020, KDD, EBR )
- Apprentissage des codes discrets D-Dimension en K pour les représentations d'intégration compacte (Chen et al., 2018, ICML)
Ensembles de données
- 【MS Marco】 Mme Marco: un ensemble de données de compréhension de la lecture de la machine générée par l'homme
- 【Trec Car】 Trec Complex Response Retrieval Aperçu
- 【TREC DL】 Aperçu du TREC 2019 Deep Learning Track
- 【TREC Covid】 TREC-COVID: Construire une collection de tests de récupération des informations pandémiques
Méthodes d'indexation
- Arbre à base d'arbres
- Arbres de recherche binaires multidimensionnels utilisés pour la recherche associative (1975, KD Tree )
- Ennuyer
- À base de hachage
- Approximations des voisins les plus proches: vers l'élimination de la malédiction de la dimensionnalité (1998, LSH )
- En quantification basée sur la quantification
- Quantification du produit pour la recherche de voisin le plus proche (2010, PQ )
- Quantification optimisée du produit (2013, OPQ )
- Graphique
- Navigation dans un petit monde (2000, NSW )
- Recherche de voisin le plus proche efficace et robuste en utilisant des graphiques hiérarchiques de petit monde navigable (2018, HNSW )
- Kits d'outils
- FAISS: une bibliothèque pour une recherche et un regroupement de similitudes efficaces de vecteurs denses
- SPTAG: une bibliothèque pour une recherche rapide à l'approche rapide
- OpenMatch: un package open source pour la récupération d'informations
- Pyserini: une boîte à outils Python pour la recherche de recherche d'informations reproductibles avec des représentations clairsemées et denses
- Elasticsearch


