Modelos semânticos incríveis para a recuperação do primeiro estágio
Observação:
- Uma lista com curadoria de artigos incríveis para recuperação semântica , incluindo alguns métodos iniciais e modelos neurais recentes para tarefas de recuperação de informações (por exemplo, recuperação ad-hoc, controle de qualidade de domínio aberto, controle de qualidade comunitário e conversas automáticas).
- Para pesquisadores que desejam adquirir modelos semânticos para renomear estágios, encaminhamos os leitores para a incrível pesquisa Neuir de Guo et.al.
- Qualquer feedback e contribuição são bem -vindos, abra um problema ou entre em contato comigo.
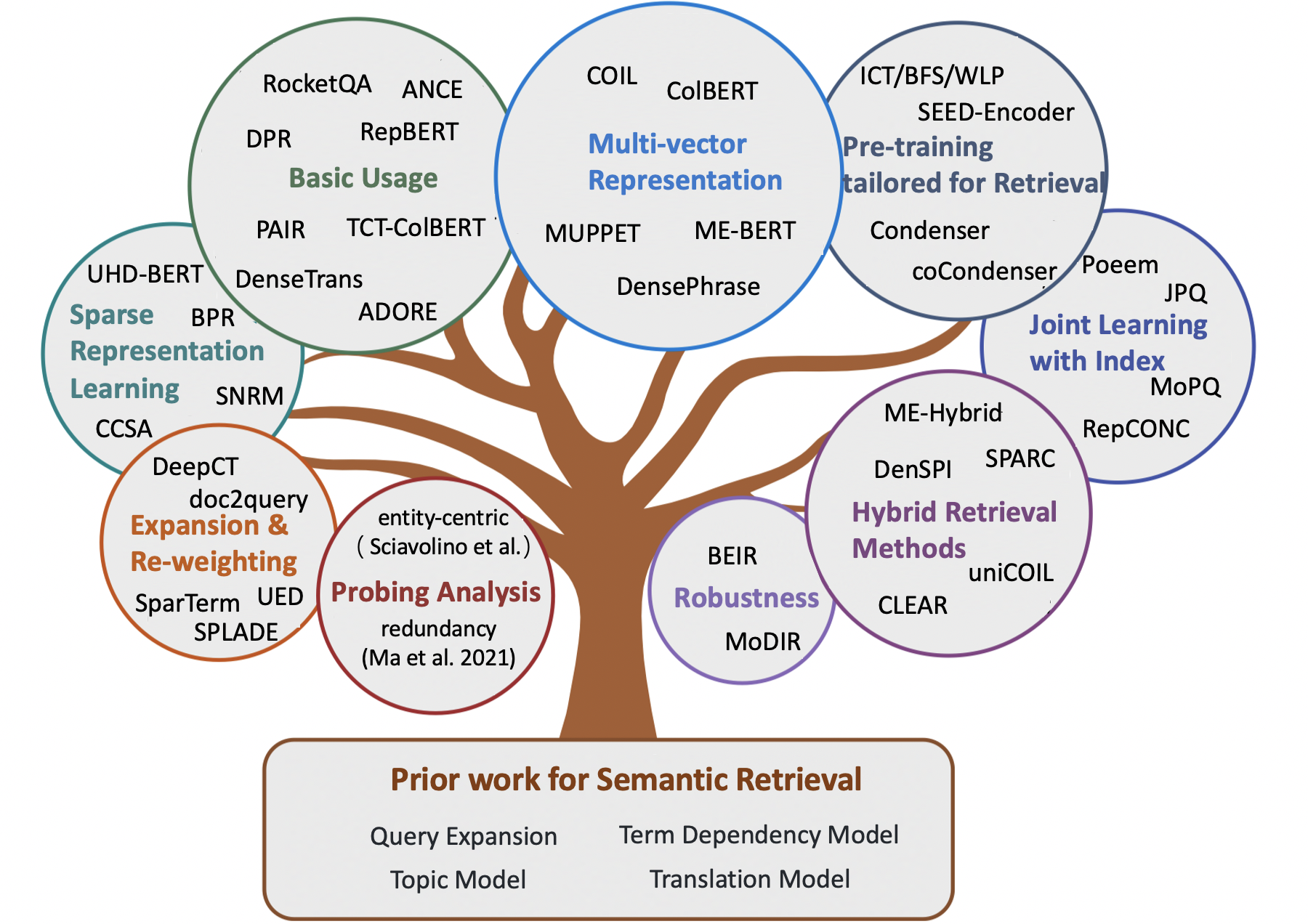
Conteúdo
- Documento de pesquisa
- Capítulo 1: Recuperação clássica baseada em termos
- Capítulo 2: Métodos iniciais para recuperação semântica
- Expansão de consulta
- Expansão de documentos
- Modelo de dependência a termo
- Modelo de tópico
- Modelo de tradução
- Capítulo 3: Métodos neurais para recuperação semântica
- Métodos de recuperação esparsa
- Métodos densos de recuperação
- Métodos de recuperação híbrida
- Capítulo 4: Outros recursos
- Outras tarefas
- Conjuntos de dados
- Métodos de indexação
Documento de pesquisa
- Combinação semântica na busca (Li et al., 2014)
- Transformadores pré -tenhados para classificação de texto: Bert e além (Lin et al., 2021, arxiv)
- Modelos semânticos para a recuperação do primeiro estágio: uma revisão abrangente (Guo et al., 2021, Tois)

- Uma estrutura conceitual proposta para uma abordagem representacional da recuperação da informação (Lin et al., 2021, arxiv)
- Métodos de pré-treinamento em recuperação de informações (Fan et al., 2022, arxiv)
- Recuperação de texto densa com base em modelos de idiomas pré -teremam: uma pesquisa (Zhao et al., 2022, arxiv)
- Recuperação densas de baixo recurso para respostas de perguntas de domínio aberto: uma pesquisa abrangente (Shen et al., 2022, arxiv)
- Notas de aula sobre recuperação de informações neurais (Tonellotto et al., 2022, arxiv)
Recuperação clássica baseada em termos
- Um modelo de espaço vetorial para indexação automática (1975, VSM )
- Desenvolvimentos na recuperação automática de texto (1991, TFIDF )
- Abordagens de ponderação a prazo na recuperação automática de texto (1988, TFIDF )
- Relevância ponderagem dos termos de pesquisa (1976, BIM )
- Uma base teórica para o uso de dados de co-ocorrência na recuperação de informações (1997, Modelo de Dependência de Árvores )
- A estrutura de relevância probabilística: BM25 e Beyond (2010, BM25 )
- Uma abordagem de modelagem de idiomas para a recuperação de informações (1998, ql )
- Modelos de idiomas estatísticos para recuperação de informações (2007, LM para IR )
- Modelo de linguagem hipergeométrica e função de pontuação do tipo ZIPF para recuperação de similaridade de documentos da web (2010, LM para IR )
- Modelos probabilísticos de recuperação de informações com base na medição da divergência da aleatoriedade (2002, DFR )
Métodos iniciais para recuperação semântica
Expansão de consulta
- Modelo global
- Associações de palavras-palavras em sistemas de recuperação de documentos (1969)
- Expansão de consulta baseada em conceito (1993)
- Expansão de consulta usando relações lexicais-semânticas (1994)
- Usando contextos de consulta na recuperação de informações (2007)
- Modelo local
- Feedback de relevância na recuperação de informações (1971, Rocchio Prf )
- Feedback baseado em modelo na abordagem de modelagem de idiomas para recuperação de informações (2001, Modelo de Minimização de Divergência )
- UMass em Trec 2004: Novidade e Hard (2004, RM3 para PRF )
- Selecionando bons termos de expansão para feedback de pseudo-relevância (2008, Prf)
- Um estudo comparativo de métodos para estimar modelos de linguagem de consulta com pseudo -feedback (2009)
- Feedback de pseudo-relevância com base na fatorização da matriz (2016)
- Reduzindo o risco de expansão de consulta por meio de otimização robusta restrita (2009 , Problema de deriva da consulta )
- Expansão de consulta usando análise de documentos locais e globais (2017)
Expansão de documentos
- Estrutura do corpus, modelos de idiomas e recuperação de informações ad hoc (2004)
- Recuperação baseada em cluster usando modelos de idiomas (2004)
- Recuperação de informações do modelo de idioma com expansão de documentos (2006)
- Expansão de documentos baseada no WordNet para IR robusto (2010)
- Melhorando a recuperação de textos curtos por meio de expansão de documentos (2012)
- Expansão de documentos usando coleções externas (2017, baseado em WordNet )
- Expansão de documentos versus expansão de consulta para recuperação ad-hoc (2005)
Modelo de dependência a termo
- Experimentos na indexação de frase automática para recuperação de documentos: uma comparação de métodos sintáticos e não sintáticos (1987, VSM + termo dependência )
- Abordagens de ponderação a prazo na recuperação automática de texto (1988, VSM + termo dependência )
- Uma análise de frases estatísticas e sintáticas (1997, VSM + termo dependência )
- Um modelo probabilístico de recuperação de informações: desenvolvimento e experimentos comparativos (2000, vsm + termo dependência )
- Classificação de relevância usando kernels (2010, BM25 + dependência do termo )
- Um modelo de idioma geral para recuperação de informações (1999, LM + termo dependência )
- Modelos de linguagem Biterm para recuperação de documentos (2002, LM + Termo Dependência )
- Captura de dependências a termos usando um modelo de idioma baseado em árvores de sentença (2002, LM + termo dependência )
- Modelo de idioma de dependência para recuperação de informações (2004, LM + termo dependência )
- Uma teoria generativa da relevância (2008)
- Um modelo de campo aleatório de Markov para dependências de termos (2005, SDM )
Modelo de tópico
- Modelo de espaço vetorial generalizado na recuperação de informações (1985, GVSM )
- Indexação por análise semântica latente (1990, LSI para IR )
- Indexação semântica latente probabilística (2017, PLSA, combinar linearmente )
- Estrutura do corpus, modelos de idiomas e recuperação de informações ad hoc (2004, suavização )
- Pontuações de recuperação ad hoc regularizando (2005, suavização )
- Modelos de documentos baseados em LDA para recuperação ad-hoc (2006, LDA para IR e LDA para suavização de LM )
- Um estudo comparativo da utilização de modelos de tópicos para recuperação de informações (2009, suavização )
- Investigando o desempenho da tarefa de modelos de tópicos probabilísticos: um estudo empírico da PLSA e LDA (2010)
- A indexação semântica latente (LSI) falha para as coleções TREC (2011)
Modelo de tradução
- Recuperação da informação como tradução estatística (1999)
- Estimativa de modelos de tradução estatística com base em informações mútuas para recuperação de informações ad hoc (2010)
- Modelos de tradução baseados em cliques para pesquisa na web: de modelos de palavras a modelos de frases (2010)
- Análise Axiomática do Modelo de Linguagem de Tradução para Recuperação de Informações (2012)
- Reescrita de consulta usando a tradução monolíngue de máquinas estatísticas (2010, para expansão de consulta )
- Para modelos de tradução baseados em conceito, usando logs de pesquisa para expansão da consulta (2012, para expansão de consulta )
Métodos neurais para recuperação semântica
Métodos de recuperação esparsa
- Termo re-ponderação
- Aprendendo a refazer os termos com representações distribuídas (Zheng et al., 2015, Sigir, DeepTr )
- Integração e avaliação de incorporações de palavras neurais na recuperação de informações (Zuccon et al., 2015, ADCs, NTLM )
- Aprendendo a termo discriminação (Frej et al, 2020, SIGIR, TDV )
- Estimativa de importância de sentença/termo de precisão de contexto para recuperação de primeira etapa (Dai et al., 2019, arxiv, Deepct )
- Ponderação de termo com reconhecimento de contexto para recuperação de passagem em primeiro estágio (Dai et al., 2020, Sigir, Deepct )
- Implicações de eficiência da ponderação do termo para recuperação de passagem (Mackenzie et al., 2020, Sigir, Deepct )
- Poço de termo com reconhecimento de contexto para pesquisa ad-hoc (Dai et al., 2020, www, hdct )
- Algumas breves notas sobre o DeepImpact, bobina e uma estrutura conceitual para técnicas de recuperação de informações (Lin et al., 2021, arxiv, unicoil )
- Expansão
- Expansão de documentos por previsão de consultas (Nogueira et al., 2019, arxiv, doc2query )
- De Doc2Query a DocttttQuery (Nogueira et al., 2019, Arxiv, DocttttQuery )
- Uma estrutura de pré -treinamento unificada para classificação de passagem e expansão (Yan et al., 2021, AAAI, UED )
- Recuperação da geração agente para resposta a perguntas de domínio aberto (Mao et al., 2020, ACL, GAR , expansão da consulta )
- Expansão + termo re-ponderação
- Expansão por previsão de importância com a contextualização (Macavaney et al., 2020, Sigir, Epic )
- SPARTERM: Aprendendo a representação esparsa baseada em termos para recuperação de texto rápido (Bai et al., 2020, arxiv, Sparterm )
- Splade: Modelo Sparso Lexical e de Expansão para Ranking de Primeiro estágio (Formal et al., 2021, Sigir, Splade )
- Splade V2: Modelo de LEXICAL E EXPANSÃO esparso para recuperação de informações (Formal et al., 2021, Arxiv, Spladev2 )
- Aprendendo os impactos da passagem para índices invertidos (Mallia et al., 2021, Sigir, DeepImapct )
- Tilde: Modelo de verossimilhança independente de termo para a passagem de passagem (Zhuang et al., 2021, Sigir, Tilde )
- Passagem rápida novamente com a correspondência exata contextualizada e a expansão eficiente da passagem (Zhuang et al., 2021, Arxiv, TildeV2 )
- SPADE: Melhorando representações esparsas usando um codificador de documentos duplos para recuperação em primeira etapa (Choi et al., 2022, CIKM)
- Aprendizagem de representação esparsa
- Hashing semântico (Salakhutdinov et al., 2009)
- Do renomeamento neural ao ranking neural: aprendendo uma representação escassa para indexação invertida (Zamani et al., 2018, CIKM, SNRM )
- UHD-Bert: Representações escassas de escasso ultra-altas de balde para classificação completa (Jang et al., 2021, Arxiv, Uhd-Bert )
- Recuperação de passagem eficiente com hash para respostas de perguntas de domínio aberto (Yamada et al., 2021, ACL, BPR )
- Código composto AutoEncoders esparsos para recuperação de primeira etapa (Lassance et al., 2021, Sigir, CCSA )
Métodos densos de recuperação
- Baseado em palavras
- Agregando incorporações contínuas de palavras para recuperação de informações (ClinChant et al., 2013, ACL, FV )
- Modelos de recuperação de informações monolíngues e cruzadas baseadas em incorporação de palavras (bilíngues) (Vulic et al., 2015, Sigir)
- Similaridade de texto curto com incorporações de palavras (Kenter et al., 2015, CIKM, OOB )
- Um modelo espacial de incorporação dupla para classificação de documentos (Mitra et al., 2016, Arxiv, DESM )
- Sugestão eficiente de resposta à linguagem natural para resposta inteligente (Henderson et al., 2017, arxiv)
- Recuperação de ponta a ponta no espaço contínuo (Gillick et al., 2018, arxiv)
- Resposta de perguntas indexadas por frase: Um novo desafio para a compreensão de documentos escaláveis (Seo et al., 2018, EMNLP, PIQA )
- Recuperação de Passagem densa para Resposta de Perguntas para Domínios Abertos (Karpukhin et al., 2020, EMNLP, DPR )
- Geração de recuperação de recuperação para tarefas de PNL com uso intensivo de conhecimento (Lewis et al., 2020, NIPS, RAG )
- REPBERT: INCLIMENTOS DE TEXTO CONTEXTIVADO PARA REFERVIÇÃO DE PRIMEIRO EMPRIATIVO (ZHAN et al., 2020, Arxiv, Repbert )
- CORT: Classificação complementar de Transformers (Wrzalik et al., 2020, NAACL, CORT )
- DC-Bert: Desarbrar a pergunta e documento para codificação contextual eficiente (Nie et al., 2020, Sigir, DC-Bert )
- Recuperação neural para resposta a perguntas com o aumento de dados supervisionados de atendimento cruzado (Yang et al., 2021, ACL, Aumentação de dados )
- Aprendizagem contrastiva negativa mais próxima do vizinho mais próximo para recuperação de texto denso (Xiong et al., 2020, arxiv, ance )
- Aprendendo a recuperar: como treinar um modelo denso de recuperação de maneira eficaz e eficiente (Zhan et al., 2020, Arxiv, LTRE )
- GLOW: Rede de auto-ataque ponderada global para Web (Shan et al, 2020, Arxiv, Glow )
- Uma abordagem de treinamento otimizada para recuperar densidade de passagem para respostas de perguntas de domínio aberto (Qu et al., 2021, ACL, Rocketqa )
- ENCESSIONAR ENCENDIAMENTE UM RETRIEVER DENEGO EFICIENTE COM AMOSTRAÇÃO DE ACONTAÇÃO DE TOPOSA BALAFICANTE (HOFSTätter et al., 2021, Sigir, Tas-Ballanceado )
- Otimizando o treinamento de modelos de recuperação denso com negativos duros (Zhan et al., 2021, Sigir, Star/Adore )
- Recuperação dense de densa conversação com poucas fotos (Yu et al., 2021, Sigir)
- Aprendendo representações densas de frases em escala (Lee et al., 2021, ACL, densefrases )
- Recuperação densa mais robusta com aprendizado duplo contrastivo (Lee et al., 2021, ictir, dança )
- Par: aproveitar a relação de similaridade centrada na passagem para melhorar a recuperação de passagem densa (Ren et al., 2021, ACL, par µ
- Supervisão guiada por relevância para o OpenQA com Colbert (Khattab et al., 2021, TACL, Colbert-Qa )
- Treinamento de ponta a ponta do leitor e retriever de vários documentos para respostas de perguntas em domínio aberto (Sachan et al., 2021, arxiv, emdr^2 )
- Melhorando as representações de consulta para recuperação densa com pseudo-relevância feedback (Yu et al, 2021, Cikm, Ance-prf )
- Feedback de pseudo-relevância para recuperação de densa de representação múltipla (Wang et al., 2021, ICTIR, Colbert-prf )
- Um Ranker semântico discriminativo para recuperação de perguntas (Cai et al., 2021, ICTIR, Densetrans )
- Representação Desacoplamento para recuperação de passagem de domínio aberto (Wu et al., 2021, arxiv)
- RocketQav2: Um método de treinamento conjunto para recuperação de passagem densa e renomeamento de passagem (Ren et al., 2021, EMNLP, RocketQav2 )
- Treinamento eficiente de modelos de recuperação usando cache negativo (Lindgren et al., 2021, Neurips)
- Treinamento em vários estágios com melhor contraste negativo para recuperação de passagem neural (Lu et al., 2021, EMNLP)
- Melhorando a recuperação em larga escala baseada em incorporação por meio de aprimoramento da etiqueta (Liu et al., 2021, EMNLP)
- Recuperação hierárquica densa para respostas de perguntas de domínio aberto (Liu et al., 2021, EMNLP)
- Representação de documentos bi-granulares progressivamente otimizados para recuperação baseada em incorporação escalável (Xiao er al., 2022 , www)
- LED: Retriever denso iluminado por léxico para recuperação em larga escala (Zhang et al., 2023, www)
- Aggretriever: uma abordagem simples para agregar a representação textual para recuperação de passagem densa robusta (Lin et al., 2022, arxiv)
- Aprendizagem contrastiva com reconhecimento de sentenças para recuperação de passagem de domínio aberto (Wu et al., 2022, ACL)
- Especialização com reconhecimento de tarefas para recuperação densa eficiente e robusta para respostas de perguntas de domínio aberto (Cheng et al., 2022, arxiv)
- Destilação do conhecimento
- Destilando representações densas para classificação usando professores fortemente acoplados (Lin et al., 2020, Arxiv, TCT-Colbert )
- Distilação de conhecimento para bate-papo baseado em rápida recuperação (Tahami et al., 2020, Sigir)
- Destilando conhecimento do leitor para o Retriever para resposta a perguntas (Izacard et al., 2020, arxiv)
- Retriever é apenas um aproximador do leitor? (Yang et al., 2020, arxiv)
- Melhorando os modelos de classificação de documentos bi-codificadores com dois rankers e destilação com vários professores (Choi et al., 2021, Sigir, TRMD )
- Melhorando modelos eficientes de classificação neural com destilação de conhecimento entre arquitetura cruzada (Hofstätter et al., 2021, arxiv, perda de margem-mse )
- Twinbert: Distilação de conhecimento de modelos Bert compactados com estrutura dupla para recuperação em larga escala (Lu et al., 2022, Arxiv)
- Representação multi-vetor
- Recuperação de parágrafos multi-hop para respostas de perguntas de domínio aberto (Feldman et al., 2019, ACL, Muppet )
- Representações esparsas, densas e atencionais para recuperação de texto (Luan et al., 2020, TACL, ME-Bert )
- Colbert: Pesquisa de passagem eficiente e eficaz por meio de interação tardia contextualizada sobre Bert (Khattab et al., 2020, Sigir, Colbert )
- Bobina: revisite a correspondência lexical exata na recuperação de informações com a lista invertida contextualizada (Gao et al., 2021, NaCl, bobina )
- Melhorando as representações de documentos gerando incorporações de consulta pseudo para recuperação densa (Tang et al., 2021, ACL)
- A Recuperação de Phrase aprende a recuperação de passagem, também (Lee et al., 2021, EMNLP, Densephrases )
- Consulta incorporação de poda para recuperação densa (Tonellotto et al., 2021, CIKM)
- Aprendizagem de representação de documentos de várias visualizações para recuperação densiva de domínio aberto (Zhang et al., 2022, ACL)
- Colbertv2: Recuperação eficaz e eficaz via interação tardia leve (Santhanam, 2022, NAACL)
- Aprendendo diversas representações de documentos com interações de consulta profunda para recuperação densa (Li et al., 2022, arxiv)
- Modelo baseado em representação de texto granulado por tópico para recuperação de documentos (du et al., 2022, ICANN)
- Acelere modelos baseados em interação
- Incorporando a suposição de independência do termo de consulta para recuperação e classificação eficientes usando redes neurais profundas (Mitra et al., 2019, Arxiv)
- Classificação neural baseada em interação eficiente com hash sensível à localidade (Ji et al., 2019, www)
- Poli-codificadores: arquiteturas e estratégias de pré-treinamento para pontuação rápida e precisa de várias frases (Humau et al., 2020, ICLR, poli-codificadores )
- Estrutura de classificação baseada em transfômers modularizada (Gao et al., 2020, EMNLP, costumes )
- Documento eficiente re-lançando para transformadores, com representações de termos pré-compuatórias (Macavaney et al., 2020, Sigir, PretTr )
- Deformador: Decompondo transformadores pré-treinados para uma resposta mais rápida de perguntas (Cao et al., 2020, ACL, deformador )
- Esparta: Efficient Open Domain Pergunta Responda via Recuperação de Combinação de Transformadores Esparsos (Zhao et al., 2020, Arxiv, Sparta )
- Conformer-Kernel com Independência do termo de consulta para recuperação de documentos (Mitra et al., 2020, Arxiv)
- INTTOWER: A próxima geração de modelo de duas torre para o sistema de pré-classificação (Li et al., 2022, CIKM)
- Pré-treinamento
- Recuperação latente para respostas de perguntas de domínio aberto fracamente supervisionado (Lee et al., 2019, ACL, ORQA )
- Modelo de idioma de recuperação de recuperação Pré-treinamento (Guu et al., 2020, ICML, Reino )
- Tarefas de pré-treinamento para incorporar a recuperação em larga escala (Chang et al., 2020, ICLR, BFS+WLP+MLM )
- O seu modelo de idioma está pronto para a representação densa e o ajuste fino? (Gao et al., 2021, EMNLP, condensador )
- Modelo de idioma de corpus não supervisionado Pré-treinamento para recuperação de passagem densa (Gao et al., 2021, Arxiv, Cocondenser )
- Menos é mais: pré-treinamento um codificador siamês forte usando um decodificador fraco (Lu et al., 2021, EMNLP, codificador de sementes )
- Modelo de idioma pré-treinado para recuperação em escala na web na pesquisa de Baidu (Liu et al., 2021, KDD)
- Pré-treinamento para recuperação ad-hoc: o hiperlink também você precisa de (Ma et al., 2021, Cikm, harpa )
- Pré-treinar um codificador de texto discriminativo para recuperação densa por meio de previsão de extensão contrastiva (Ma et al., 2022, Sigir)
- TSDAE: Usando o codificador de denoising seqüencial baseado em transformador para a sentença não supervisionada que incorpore o aprendizado (Wang et al., 2021, EMNLP)
- Máscara contextual Auto-Encoder para recuperação de passagem densa (Wu et al., 2022, Arxiv)
- SIMLM: pré-treinamento com gargalos de representação para recuperação de passagem densa (Wang et al., 2022, arxiv)
- Lexmae: Pré-Trelainamento de Léxico-Bottlenecked para Recuperação em larga escala (Shen et al., 2022, Arxiv)
- Uma abordagem de pré-treinamento contrastiva para aprender autoencoder discriminativo para recuperação densa (Ma et al., 2022, CIKM)
- Retomae: modelos de linguagem orientada a recuperação pré-treinamento por meio do codificador automático mascarado (Xiao e Liu et al., 2022, EMNLP)
- Modelo de idioma de pré-treinamento de máscara orientado para recuperação para recuperação de passagem densa (Long et al., 2022, arxiv)
- LaPrador: Retriever denso pré-terenciado não supervisionado para recuperação de texto com tiro zero (Xu et al., 2022, ACL)
- AutoEncoders mascarados como aprendizes unificados para representação de sentenças pré-treinadas (Liu et al., 2022, arxiv)
- Mestre: Os autoencodentes mascarados com gargalos pré-treinados com várias tarefas são melhores retrievers densos (Zhou et al., 2023, ICLR)
- COT-MAE V2: Encoder automático mascarado contextual com modelagem de várias vistas para recuperação de passagem (Wu et al., 2023, arxiv)
- MOTE COT: Explorando pré-treinamento de automóveis mascarado contextual com expertores de mistura de textual para recuperação de passagem (Ma et al., 2023, arxiv)
- Aprendizagem conjunta com índice
- Aprendizagem conjunta de modelo de recuperação profunda e índice de incorporação baseado em quantização de produtos (Zhang et al., 2021, Sigir, Poeem )
- Otimizando em conjunto o codificador de consulta e a quantização do produto para melhorar o desempenho da recuperação (Zhan et al., 2021, Cikm, JPQ )
- Quantização de produtos orientada para correspondência para recuperação ad-hoc (Xiao et al., 2021, EMNLP, MOPQ )
- Aprendendo representações discretas por meio de agrupamento restrito para uma recuperação densa eficaz e eficiente (Zhan et al, 2022, WSDM, RepConc )
- Aprendizagem conjunta com Ranker
- Treinamento de ponta a ponta dos retrievers neurais para respostas de perguntas de domínio aberto (Sachan et al., 2021, ACL)
- Adversarial Retriever-Ranker para recuperação de texto densa (Zhang et al., 2022, ICLR)
- Debias
- Aprendendo modelos de recuperação densos robustos a partir de etiquetas de relevância incompletas (Prakash et al., 2021, Sigir, Rance )
- Negativos difíceis ou falsos negativos: corrigindo o viés de agrupamento no treinamento de modelos de classificação neural (Cai et al., 2022, CIKM)
- Siman: Amostragem negativa ambígua simples para recuperação de texto denso (Zhou et al., 2022, EMNLP)
- Aprendizagem contrastiva debiária de representações de sentenças não supervisionadas (Zhou et al., 2022, ACL)
- Recuperação de ouro da areia preta: recuperação de passagem densa multilíngue com amostras difíceis e falsas negativas (Shen et al., 2022, EMNLP)
- Zero-shot/Few-shot
- Recuperação de tiro zero baseado em incorporação através da geração de consultas (Liang et al., 2020, Arxiv)
- Recuperação de passagem neural zero-tiro via geração de perguntas sintéticas direcionadas ao domínio (Ma et al., 2020, QGEN , ARXIV)
- Em direção a modelos robustos de recuperação neural com pré-treinamento sintético (Reddy et al., 2021, Arxiv)
- Beir: Um benchmark heterogêneo para avaliação de tiro zero dos modelos de recuperação de informações (Thakur et al., 2021, Neurips)
- Recuperação densiva de tiro zero com o Momentum Adverssarial Domain Invariant Representations (Xin et al., 2021, Arxiv, Modir )
- Grandes codificadores duplos são recuperadores generalizáveis (Ni et al., 2022, EMNLP, DTR )
- Semântica fora do domínio para o resgate! Modelos de recuperação híbrida zero-tiro (Chen et al., 2022, ECIR)
- INPARS: Aumentação de dados para recuperação de informações usando grandes modelos de idiomas (Bonifacio et al., 2022, Arxiv)
- Rumo à recuperação de informações densas não supervisionadas com aprendizado contrastante (Izacard et al., 2021, Arxiv, Contrador )
- GPL: Pseudo -rotulagem generativa para adaptação do domínio não supervisionada da recuperação densa (Wang et al., 2022, NAACL)
- Aprendendo a recuperar passagens sem supervisão (Ram et al., 2021, arxiv, aranha )
- Um exame minucioso sobre a recuperação dense zero-tiro (Ren et al., 2022, arxiv)
- INCEDIMENTOS DE TEXTO E CÓDIGO POR CONTRATIVO PRANTOLING (Neelakantan et al., 2022, Arxiv)
- Modelagem de Domínio e Relevância para Recuperação Adaptável (Zhan et al., 2022, Arxiv)
- Promptgator: Recuperação de Densidade de Feiantamento de 8 Exemplos (Dai et al., 2022, ARXIV)
- As perguntas são tudo o que você precisa para treinar um denso Retriever (Sachan et al., 2022, TACL)
- Hiper: O treinamento hiper-promprido com várias tarefas permite a generalização de recuperação em larga escala (Cai et al., 2023, ICLR)
- Coco-DR: Combatendo mudanças de distribuição na recuperação densa de tiro zero com aprendizado contrastivo e distributamente robusto (Yu et al., 2022, EMNLP)
- Desafios na generalização em respostas de perguntas de domínio aberto (Liu et al., 2022, NAACL)
- Robustez
- Rumo a uma recuperação densa robusta via alinhamento local de classificação (Chen et al., 2022, IJCAI)
- Lidando com erros de digitação para recuperação de passagem baseada em Bert e classificação (Zhuang et al., 2021, EMNLP)
- Avaliando a robustez dos oleodutos de recuperação com geradores de variação de consulta (Penha et al., 2022, ECIR)
- Analisando a robustez de codificadores duplos para recuperação densa contra erros de ortografia (Sidiropoulos et al., 2022, Sigir)
- Caracterbert e auto-ensino para melhorar a robustez dos densos retrievers em consultas com erros de digitação (Zhuang et al., 2022, Sigir)
- Bert Rankers é frágil: um estudo usando perturbações do documento adversário (Wang et al., 2022, ICTIR)
- Disorder de ordem: Ataques adversários de imitação para modelos de classificação neural de BlackBox (Liu et al., 2022, Arxiv)
- A pré-treinamento com gargalos com reconhecimento de digitação para recuperação robusta dense (Zhuang et al., 2023, Arxiv)
- Análise de sondagem
- A maldição de densa recuperação de informações de baixa dimensão para grandes tamanhos de índices (Reimers et al., 2021, ACL)
- Eliminação de redundância não supervisionada simples e eficaz para comprimir vetores densos para recuperação de passagem (Ma et al., EMNLP, 2021, redundância )
- Beir: Uma referência heterogênea para avaliação de tiro zero dos modelos de recuperação de informações (Thakur et al., 2021, Neurips, Transferitabilidade )
- Phrase Saliente Consciência de Recuperação dense: Um denso Retriever pode imitar um esparso? (Chen et al., 2021, arxiv)
- Questões centradas na entidade simples desafiam os densos Retrievers (Sciavolino et al., 2021, EMNLP)
- Interpretando a densa recuperação como a mistura de tópicos (Zhan et al., 2021, arxiv)
- Uma análise de atribuição do codificador para retiradas de passagem densa em resposta de perguntas abertas (Li et al., 2022, TrustNLP)
- A representação isotrópica pode melhorar a recuperação densa (Jung et al., 2022, arxiv)
- Aprendizado imediato
- Modelo de classificação neural bi-codificadora semi-siamesa usando o ajuste fino leve (Jung et al., 2022, www)
- Espalhado ou conectado? Uma abordagem de ajuste com eficiência de parâmetro otimizada para recuperação de informações (Ma et al., 2022, CIKM)
- DPTDR: Ajuste rápido para recuperação de passagem densa (Tang et al., 2022, Arxiv)
- Parameter-Efficient Prompt Tuning Makes Generalized and Calibrated Neural Text Retrievers(Tam et al., 2022, arXiv)
- NIR-PROMPT: Uma estrutura de treinamento de informações neurais generalizadas de várias tarefas (Xu et al., 2022, Arxiv)
- Modelo de linguagem grande para recuperação
- Recuperação densas precisas de tiro zero sem rótulos de relevância (Gao et al., 2022, arxiv)
- Outros
- HLATR: Aprimorar a recuperação de texto em vários estágios com a lista de transformadores conscientes da lista híbrida (Zhang et al., 2022, Arxiv)
- ASYNCVAL: Um kit de ferramentas para validar assíncrono Ponto de verificação dense Retriever durante o treinamento (Zhuang et al., 2022, Sigir)
Métodos de recuperação híbrida
- Baseado em palavras
- Modelos de recuperação de informações monolíngues e cruzadas com base em incorporação de palavras (bilíngues) (Vulic et al., 2015, Sigir, combinando linearmente )
- Modelo de linguagem generalizada baseada em palavras para recuperação de informações (Ganguly et al., 2015, Sigir, GLM )
- Representando documentos e consultas como conjuntos de vetores incorporados de palavras para recuperação de informações (Roy et al., 2016, Sigir, combinar linearmente )
- Um modelo espacial de incorporação dupla para classificação de documentos (Mitra et al., 2016, www, desm_mixture , combinar linearmente )
- Fora do caminho batido: vamos substituir a recuperação baseada em termos pela pesquisa K-NN (Boytsov et al., 2016, CIKM, BM25+Tradução Modelo
- Aprendendo representações híbridas para recuperar questões semanticamente equivalentes (Santos et al., 2015, ACL, Bow-CNN )
- Responda a perguntas de domínio aberto em tempo real com Índice de frase densa-densa (Seo et al., 2019, ACL, Denspi )
- Representações esparsas contextualizadas para respostas de perguntas de domínio aberto em tempo real (Lee et al., 2020, ACL, SPARC )
- CORT: Classificação complementar de Transformers (Wrzalik et al., 2020, NAACL, CORT_BM25 )
- Representações esparsas, densas e atencionais para recuperação de texto (Luan et al., 2020, TACL, ME-HYBRID )
- Modelo de recuperação lexical complemento com incorporações residuais semânticas (Gao et al., 2020, ECIR, claro )
- Aproveitando a correspondência semântica e lexical para melhorar a recuperação de sistemas de recuperação de documentos: uma abordagem híbrida (Kuzi et al., 2020, arxiv, híbrido )
- Algumas breves notas sobre o DeepImpact, bobina e uma estrutura conceitual para técnicas de recuperação de informações (Lin et al., 2021, arxiv, unicoil )
- Peso relevante offline contextualizado para recuperação neural eficiente e eficaz (Chen et al., 2021, Sigir)
- Prevendo trade-offs de eficiência/eficácia para seleção de estratégia de densidade versus esparso (Arabzadeh et al., 2021, CIKM)
- Índices de avanço rápido para classificação de documentos eficientes (Leonhardt et al., 2021, Arxiv)
- Representações esparsas densificantes para a recuperação de passagem por fatiamento representacional (Lin et al., 2021, arxiv)
- Uni fi er: Um retriever unificado para recuperação em larga escala (Shen et al., 2022, arxiv)
Outros recursos
Outras tarefas
- Pesquisa de comércio eletrônico
- Rede de juros profundos para previsão da taxa de cliques (Zhou et al., 2018, KDD, DIN )
- Da recuperação semântica ao ranking pareado: aplicação de aprendizado profundo na pesquisa de comércio eletrônico (Li et al., 2019, Sigir, Jingdong)
- Rede multi-interesse com roteamento dinâmico para recomendação em tmall (Li et al., 2019, CIKM, MIND , TMALL)
- Rumo à recuperação personalizada e semântica: uma solução de ponta a ponta para pesquisa de comércio eletrônico por meio de incorporação de aprendizado (Zhang et al., 2020, Sigir, DPSR , Jingdong)
- Rede de vários interesses profundos para previsão da taxa de cliques (Xiao et al., 2020, CIKM, DMIN )
- Recuperação profunda: um modelo de estrutura aprendida de ponta a ponta para recomendações em larga escala (Gao et al., 2020, arxiv)
- Recuperação de produtos baseada em incorporação na Taobao Search (Li et al., 2021, KDD, Taobao)
- Abraçando a estrutura nos dados para pesquisa de produtos semânticos em escala bilhão (Lakshman et al., 2021, Arxiv, Amazon)
- Pesquisa patrocinada
- Mobius: Para a próxima geração de combinações de consulta na busca patrocinada pelo Baidu (Fan et al., 2019, KDD, Baidu)
- Recuperação de imagem
- Rede neural binária Hashing para recuperação de imagens (Zhang et al., 2021, Sigir, BNNH )
- Hash de auto-adaptação profunda para recuperação de imagens (Lin et al., 2021, CIKM, DSAH )
- Relatório sobre o primeiro workshop de Hipstir sobre o futuro da recuperação de informações (Dietz et al., 2019, Sigir, Workshop)
- Vamos medir o tempo de execução! Estendendo a infraestrutura de replicação de infravermelho para incluir aspectos de desempenho (Hofstätter et al., 2019, SIGIR)
- Recuperação baseada em incorporação na pesquisa do Facebook (Huang et al., 2020, KDD, EBR )
- Aprendendo códigos discretos Dimensionais K-Way D para representações de incorporação compacta (Chen et al., 2018, ICML)
Conjuntos de dados
- 【Ms Marco】 MS MARCO: Um conjunto de dados de compreensão de leitura de máquina gerada por humanos
- 【Trec Car Car】 Trec Complex Answer Recuperação Visão geral
- 【Trec DL】 Visão geral da trilha Trec 2019 Deep Learning
- 【Trec Covid】 Trec-Covid: Construindo uma coleção de testes de recuperação de informações pandêmicas
Métodos de indexação
- Baseada em árvores
- Árvores de busca binária multidimensional usadas para pesquisa associativa (1975, árvore KD )
- Irritar
- Baseado em hash
- Aproximadamente vizinhos mais próximos: para remover a maldição da dimensionalidade (1998, LSH )
- Baseado em quantização
- Quantização do produto para a pesquisa de vizinho mais próximo (2010, PQ )
- Quantização otimizada do produto (2013, OPQ )
- Baseado em gráfico
- Navegação em um mundo pequeno (2000, NSW )
- Pesquisa de vizinho aproximada mais próxima eficiente e robusta usando gráficos mundiais pequenos de navegação hierárquica (2018, HNSW )
- Kits de ferramentas
- FAISS: uma biblioteca para pesquisa eficiente de similaridade e agrupamento de vetores densos
- SPTAG: uma biblioteca para uma pesquisa vizinha mais próxima mais próxima
- OpenMatch: um pacote de código aberto para recuperação de informações
- Pyserini: um kit de ferramentas Python para pesquisa de recuperação de informações reproduzíveis com representações esparsas e densas
- Elasticsearch


