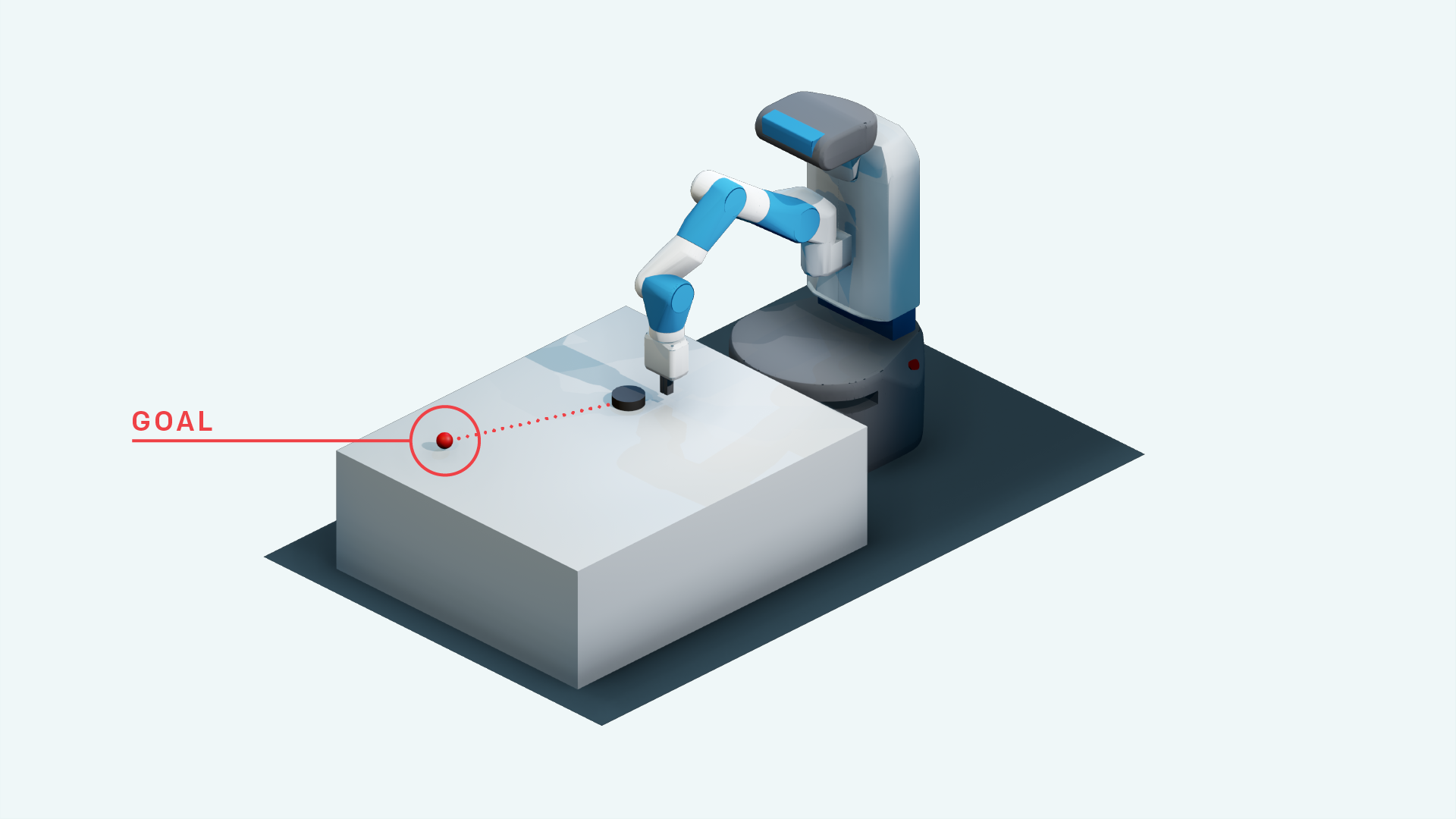
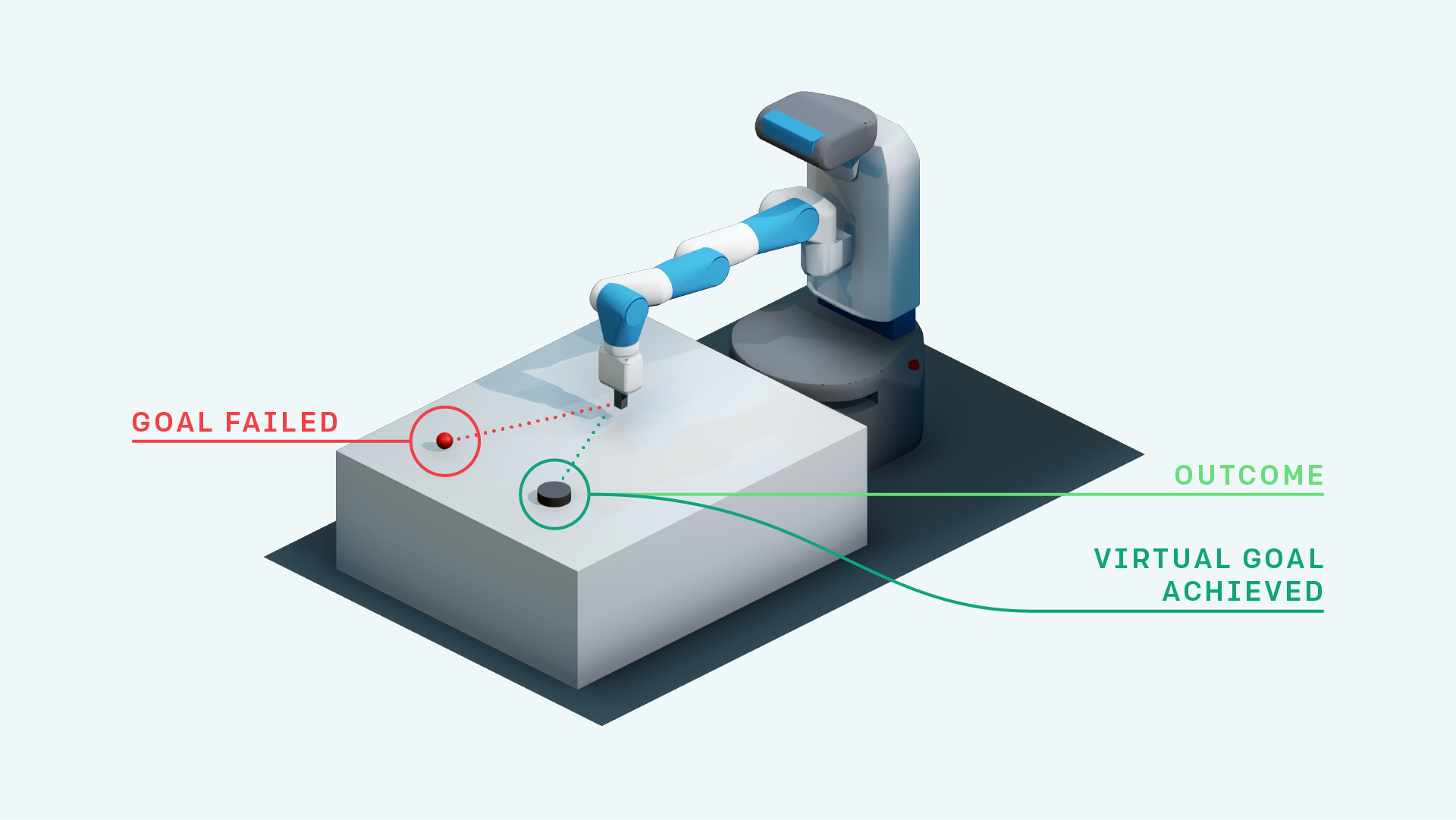
Tiefes Verstärkungslernen im Pytorch
Dieses Repository enthält alle modellfreien Standard- und modellbasierten (kommenden) RL-Algorithmen in Pytorch. (Kann auch einige Forschungsideen enthalten, an denen ich derzeit arbeite)
Für C ++-Version von Pytorch-RL: Pytorch-RL-CPP
Was ist das?
Pytorch-Rl implementiert einige hochmoderne Algorithmen für die tiefe Verstärkung in Pytorch, insbesondere diejenigen, die sich mit kontinuierlichen Handlungsräumen befassen. Sie können Ihren Algorithmus entweder auf CPU oder GPU effizient trainieren. Darüber hinaus arbeitet Pytorch-Rl mit Openai Gym von Out of the Box zusammen. Dies bedeutet, dass die Bewertung und das Herumspielen mit verschiedenen Algorithmen einfach ist. Natürlich können Sie Pytorch-Rl entsprechend Ihren eigenen Bedürfnissen erweitern. TL: DR: Pytorch-RL erleichtert es wirklich einfach, hochmoderne Algorithmen für die Verstärkung zu führen.
Installation
Installieren Sie Pytorch-RL von PYPI (empfohlen):
PIP Installieren Sie Pytorch-Policy
Abhängigkeiten
- Pytorch
- Fitnessstudio (OpenAI)
- Mujoco-Py (für die Physiksimulation und die Robotikum im Fitnessstudio)
- Pybullet (bald kommt)
- MPI (nur mit MPI -Backend -Pytorch -Installation unterstützt)
- Tensorboardx (https://github.com/lanpa/tensorboardx)
RL -Algorithmen
- DQN (mit Doppel -Q -Lernen)
- DDPG
- DDPG mit ihr (für die OpenAI -Fetch -Umgebungen)
- Heirarchische Verstärkung
- Priorisierte Erfahrung Wiederholung + DDPG
- DDPG mit priorisierter Nachblicke -Wiederholung (Forschung)
- Neuronale Karte mit A3C (bald kommt)
- Rainbow DQN (bald kommt)
- PPO (https://github.com/ikostrikov/pytorch-a2c-ppo-acktr)
- Sie mit Selbstaufmerksamkeit für die Zielsubstitution (Forschung)
- A3C (bald kommt)
- Acer (bald kommt)
- Darla
- Tdm
- Weltmodelle
- Weicher Schauspielerkritiker
- Empowerment-gesteuerte Exploration (TensorFlow-Implementierung: https://github.com/navneet-nmk/empowerment-driven-ploration)
Umgebungen
- Ausbruch
- Pong (bald kommt)
- Handmanipulation Roboteraufgabe
- Roboteraufgabe abrufen
- Handreicher Roboteraufgabe
- Blockmanipulation Roboteraufgabe blockieren
- Montezumas Rache (aktuelle Forschung)
- Falle
- Gravar
- Tragkraft
- Super Mario Bros (Befolgen Sie die Anweisungen zur Installation von Fitnessstudio-Retro https://github.com/openai/retro)
- OpenSim Prothetics NIPS Challenge (https://www.crowdai.org/challenges/nips-2018-ai-for-prosthetics-chalenge)
Umgebungsmodellierung (zur Erforschung und Domänenanpassung)
Aufgrund der Instabilität bei der Ausbildung der Generatoren und Diskriminatoren wurden mehrere GaN -Trainingstricks verwendet. Weitere Informationen finden Sie unter https://github.com/soumith/ganhacks.
Auch nach dem Einsatz der Tricks war es wirklich schwierig, einen Gan zur Konvergenz zu trainieren. Nach Verwendung der spektralen Normalisierung (https://arxiv.org/abs/1802.05957) wurde der Infogan jedoch zur Konvergenz geschult.
Für Bild -zu -Bild -Übersetzungsaufgaben mit Gans und für Vaes im Allgemeinen hilft das Training mit Skip Connection wirklich dem Training.
- Beta-vae
- Infogan
- CVAE-GAN
- Flow -basierte generative Modelle (Forschung)
- Sagan
- Sequentielle Teilnahme, abschließen, wiederholen
- Neugierde Erkundung
- Parameterraum Rauschen für die Erkundung
- Lautes Netzwerk
Referenzen
- Mnih et al., 2013, Atari mit tiefem Verstärkungslernen spielen,
- Mnih et al., 2015 auf Menschenebene durch tiefes Verstärkungslernen, Mnih et al., 2015
- Tiefe Verstärkung Lernen mit Doppel-Q-Learning, Van Hasselt et al., 2015
- Kontinuierliche Kontrolle mit tiefem Verstärkungslernen, Lillicrap et al., 2015
- CVAE-GAN: Feinkörnige Bildgenerierung durch asymmetrisches Training, Bao et al., 2017
- Beta-vae: Lernen grundlegender visueller Konzepte mit einem eingeschränkten Variationsrahmen, Higgins et al., 2017
- Replay im Hinterblicke, Andrychowicz et al., 2017
- Infogan: Interpretierbares Lernen von Repräsentationen durch Informationen, die generative kontroverse Netze maximieren, Chen et al., 2016
- Weltmodelle, Ha et al., 2018
- Spektrale Normalisierung für generative kontroverse Netzwerke, Miyato et al., 2018
- Selbstbekämpfung generative kontroverse Netzwerke, Zhang et al., 2018
- Curiosity-getriebene Erforschung durch selbstvervielfältige Vorhersage, Pathak et al., 2017
- Weiche Schauspieler-Kritik: Off-Policy Maximum Entropie Tiefes Verstärkung Lernen mit einem stochastischen Schauspieler, Karnoja et al., 2018
- Parameterraum Rauschen für Exploration, Plappert et al., 2018
- Lautes Netzwerk für Exploration, Fortunato et al., 2018
- Proximale Politikoptimierungsalgorithmen, Schulman et al., 2017
- Unüberwachte Echtzeitkontrolle durch Variationsförderung, Karl et al., 2017
- Mutuelle Information Neuronale Schätzung, Belghazi et al., 2018
- Empowerment-gesteuerte Exploration unter Verwendung von gegenseitiger Informationsschätzung, Kumar et al., 2018