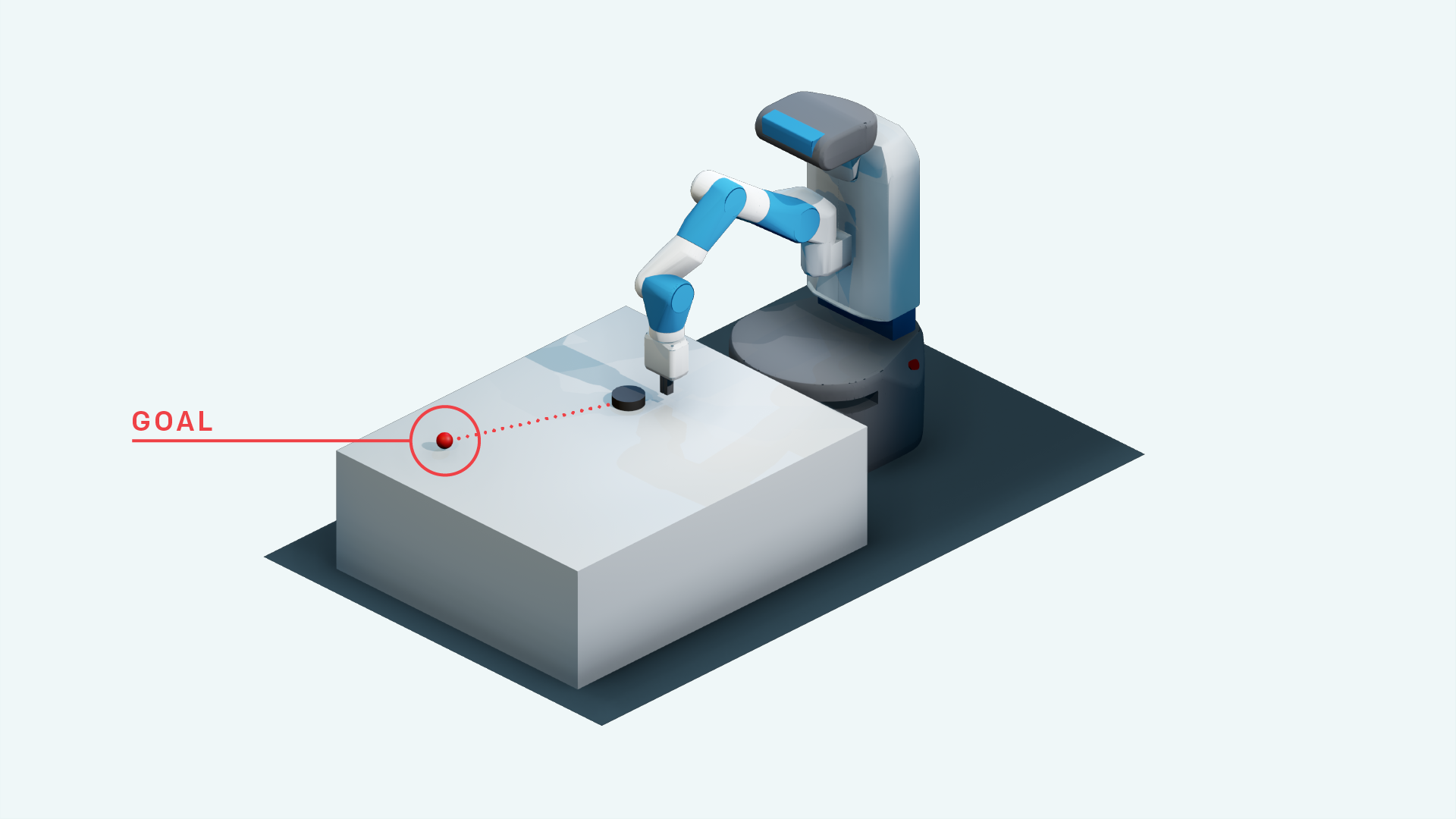
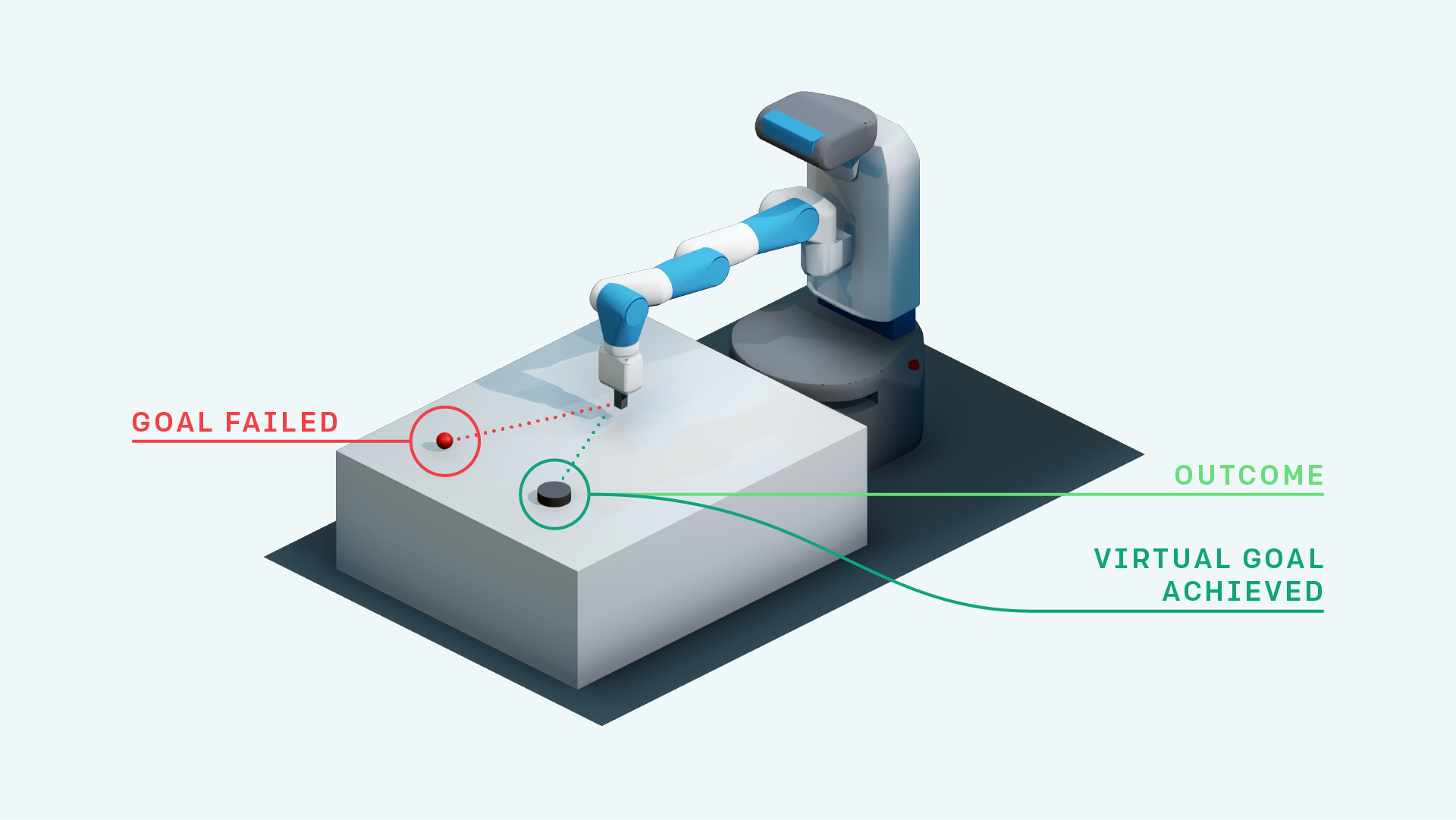
تعلم التعزيز العميق في Pytorch
يحتوي هذا المستودع على جميع خوارزميات RL الخالية من النماذج (القادمة) القائمة على النماذج في Pytorch. (قد تحتوي أيضًا على بعض الأفكار البحثية التي أعمل عليها حاليًا)
للحصول على إصدار C ++ من Pytorch-RL: Pytorch-RL-CPP
ما هذا؟
يقوم Pytorch-RL بتنفيذ بعض خوارزميات التعلم العميقة في Pytorch ، خاصة تلك المعنية بمساحات العمل المستمرة. يمكنك تدريب الخوارزمية بكفاءة إما على وحدة المعالجة المركزية أو وحدة معالجة الرسومات. علاوة على ذلك ، يعمل Pytorch-RL مع Openai Gym خارج الصندوق. هذا يعني أن التقييم واللعب مع خوارزميات مختلفة أمر سهل. بالطبع يمكنك تمديد Pytorch-RL وفقًا لاحتياجاتك الخاصة. TL: DR: Pytorch-RL يجعل من السهل حقًا تشغيل خوارزميات التعلم العميقة على أحدث طراز.
تثبيت
تثبيت Pytorch-RL من PYPI (موصى به):
PIP تثبيت pytorch-policy
التبعيات
- Pytorch
- صالة رياضية (Openai)
- Mujoco-PY (لمحاكاة الفيزياء والروبوتات ENV في صالة الألعاب الرياضية)
- pybullet (قريبا)
- MPI (مدعوم فقط بتثبيت Pytorch الخلفي MPI)
- Tensorboardx (https://github.com/lanpa/tensorboardx)
خوارزميات RL
- DQN (مع تعلم Q مزدوج)
- DDPG
- DDPG معها (لبيئات جلب Openai)
- تعلم التعزيز الوريش
- إعادة تحديد أولوية إعادة التشغيل + DDPG
- DDPG مع إعادة تشغيل تجربة الإدراك الأولوية (البحث)
- الخريطة العصبية مع A3C (قريبا)
- قوس قزح DQN (قريبا)
- PPO (https://github.com/ikostrikov/pytorch-a2c-ppo-acktr)
- لها باهتمامها في استبدال الأهداف (البحث)
- A3C (قريبا)
- أيسر (قريبا)
- دارلا
- TDM
- نماذج العالم
- ممثل ناعم النحاسي
- استكشاف تمكين تمكين (تنفيذ TensorFlow: https://github.com/navneet-nmk/empowerment-driven-exploration)
البيئات
- انطلق
- بونغ (قريبا)
- مهمة روبوتية التلاعب باليد
- جلب مهمة آلية
- مهمة روبوتية يدوية
- كتلة التلاعب المهمة الآلية
- مونتيزوما الانتقام (البحث الحالي)
- شرك
- جاذبية
- يحمل
- Super Mario Bros (اتبع التعليمات لتثبيت Gym-Retro https://github.com/openai/retro)
- Opensim الأطراف الاصطناعية NIPS تحدي (https://www.crowdai.org/challenges/nips-2018-ai-for-prosthetics-challenge)
نمذجة البيئة (للاستكشاف والتكيف مع المجال)
تم استخدام حيل التدريب المتعددة GAN بسبب عدم الاستقرار في تدريب المولدات والتمييز. يرجى الرجوع إلى https://github.com/soumith/ganhacks لمزيد من المعلومات.
حتى بعد استخدام الحيل ، كان من الصعب حقًا تدريب Gan على التقارب. ومع ذلك ، بعد استخدام التطبيع الطيفي (https://arxiv.org/abs/1802.05957) تم تدريب Infogan على التقارب.
للحصول على مهام ترجمة الصورة مع Gans و VAEs بشكل عام ، فإن التدريب مع Skip Connection يساعد حقًا على التدريب.
- بيتا-فاي
- إنفوجان
- cvae-gan
- النماذج التوليدية القائمة على التدفق (البحث)
- ساجان
- الحضور المتسلسل ، استنتاج ، كرر
- الفضول مدفوعة الاستكشاف
- ضوضاء مساحة المعلمة للاستكشاف
- شبكة صاخبة
مراجع
- لعب أتاري مع التعلم التعزيز العميق ، Mnih et al. ، 2013
- السيطرة على مستوى الإنسان من خلال تعلم التعزيز العميق ، Mnih et al. ، 2015
- تعلم التعزيز العميق مع التعلم Q مزدوج ، فان هاسيلت وآخرون ، 2015
- السيطرة المستمرة مع التعلم التعزيز العميق ، Lillicrap et al. ، 2015
- CVAE-GAN: توليد الصور الدقيق من خلال التدريب غير المتماثل ، Bao et al. ، 2017
- Beta-VAE: تعلم المفاهيم البصرية الأساسية مع إطار اختلاف مقيد ، Higgins et al. ، 2017
- إعادة توزيع تجربة الإعادة ، Andrychowicz et al. ، 2017
- Infogan: التعلم التمثيل القابل للتفسير عن طريق المعلومات إلى تعظيم الشباك العدائية التوليدية ، Chen et al. ، 2016
- نماذج العالم ، ها وآخرون ، 2018
- التطبيع الطيفي للشبكات العدائية التوليدية ، Miyato et al. ، 2018
- شبكات العدوى التوليدية للاعتداء الذاتي ، Zhang et al. ، 2018
- استكشاف الفضول الذي يحركه الفضول من خلال التنبؤ ذاتيا ، باثاك وآخرون ، 2017
- الممثل الناعم الناقص: التعلم التعزيز العميق خارج الجودة مع ممثل عشوائي ، Haarnoja et al. ، 2018
- ضوضاء مساحة المعلمة للاستكشاف ، Plappert et al. ، 2018
- شبكة صاخبة للاستكشاف ، Fortunato et al. ، 2018
- خوارزميات تحسين السياسة القريبة ، شولمان وآخرون ، 2017
- السيطرة في الوقت الفعلي غير الخاضع للرقابة من خلال التمكين التباين ، Karl et al. ، 2017
- التقدير العصبي للمعلومات المتبادلة ، Belghazi et al. ، 2018
- الاستكشاف القائم على التمكين باستخدام تقدير المعلومات المتبادلة ، كومار وآخرون ، 2018