PPOCoder
1.0.0
使用深入的強化學習的官方實施基於執行的代碼生成
在大規模代碼語料庫中審議的編程語言(PL)模型的利用,作為自動化軟件工程流程的一種手段,在簡化各種代碼生成任務(例如代碼完成,代碼翻譯和程序合成)方面具有巨大的潛力。但是,當前的方法主要依賴於從文本生成中藉來的監督微調目標,忽略了代碼的特定序列級特徵,包括但不限於彙編以及句法和功能正確性。為了解決這一限制,我們提出了PPOCODER ,這是一個新的代碼生成框架,將預驗證的PL模型與近端策略優化(PPO)深入強化學習結合在一起,並採用執行反饋作為模型優化中的知識來源。 PPOCODER可以在不同的代碼生成任務和PLS中轉移。
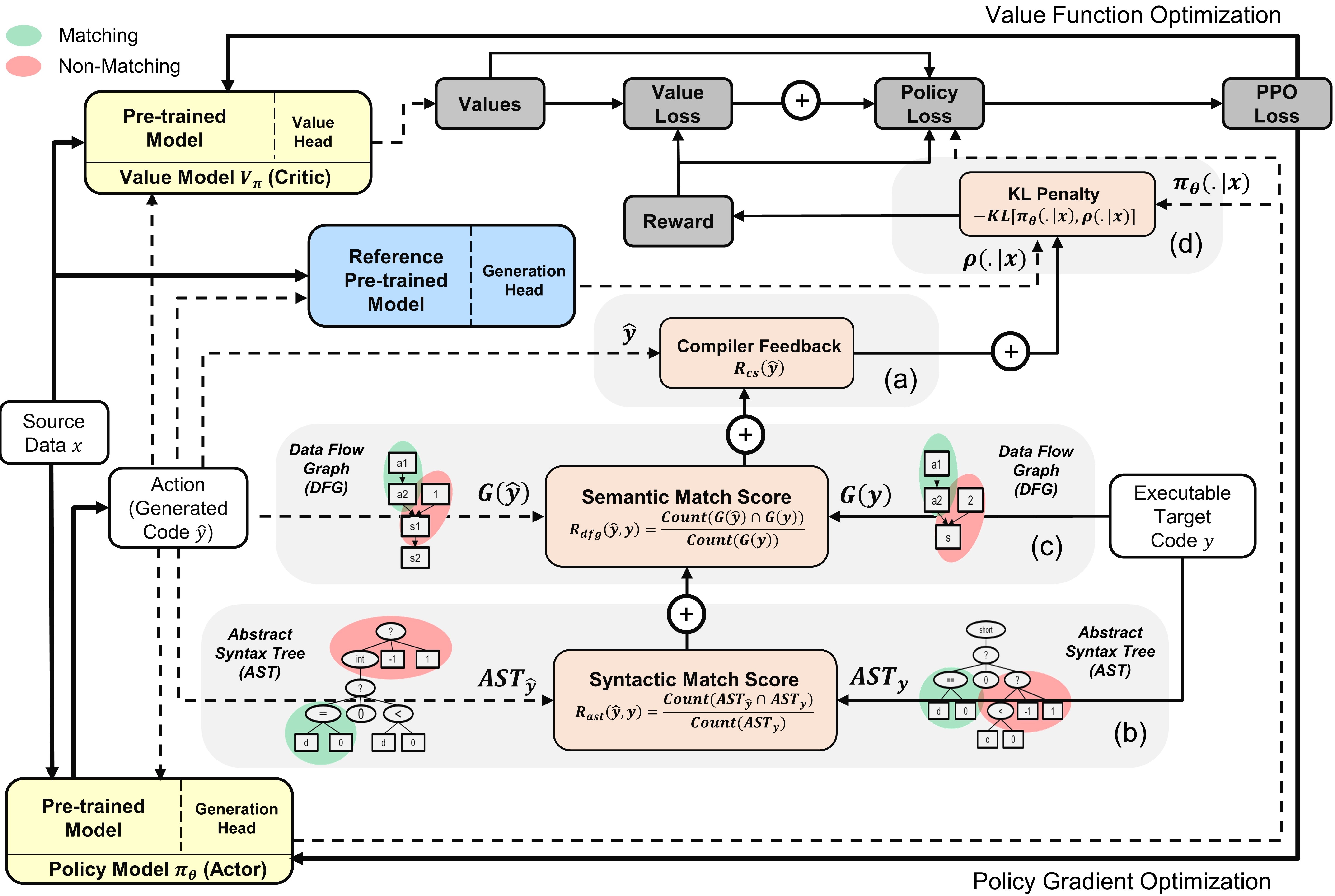
帶有演員和評論家模型的PPOCODER概述:根據給定的源數據,該動作是從策略中抽樣的
要運行代碼,請將依賴項安裝在unignts.txt中。
pip install -r requirements.txt
我們對不同代碼生成任務的以下主要數據集基准進行了Finetune/評估模型:
我們以與原始基準論文中概述的方式相同的方式預處理數據並構建輸入/輸出序列。解壓縮並將所有基準放在data文件夾中。
我們創建了run.sh腳本以基於編譯器信號執行基於PPO的PL模型微調。要運行不同代碼生成任務的腳本,請配置以下參數:
| 參數 | 描述 | 示例值 |
|---|---|---|
l1 | 源語言 | 爪哇 |
l2 | 目標語言 | CPP |
asp | 動作空間大小 | 5 |
ns | 合成樣品的數量 | 10 |
data_path | 原始數據樣本的路徑 | 數據/XLCOST/JAVA-CPP/ |
output_path | 保存世代和輸出的路徑 | saved_results/java-cpp/ |
baseline_output_dir | 基礎固定的codet5(RL之前)輸出的路徑 | 基線/saved_models/java-cpp/ |
load_model_path | 對於每個下游任務 | 基線/saved_models/java-cpp/pytorch_model.bin |
max_source_length | maxmim源長度 | 400 |
max_target_length | MAXMIM目標長度 | 400 |
train_batch_size | 培訓批量大小 | 32 |
test_batch_size | 測試批次尺寸 | 48 |
lr | 學習率 | 1E-6 |
kl_coef | 獎勵中KL DiverGunty的初始係數 | 0.1 |
kl_target | KL的靶標能夠自適應控制KL係數 | 1 |
vf_coef | PPO丟失中VF誤差的係數 | 1E-3 |
run | 運行索引 | 1 |
運行run.sh將生成的程序保存在.txt文件和每個時期末尾的模型權重。
如果您發現紙張或存儲庫有用,請引用
@article {shojaee2023ppocoder,
title = {基於執行的代碼生成使用深鋼筋學習},
作者= {Shojaee,Parshin和Jain,Aneesh和Tipirneni,Sindhu和Reddy,Chandan K},
日記= {arxiv預印arxiv:2301.13816},
年= {2023}
}


