PPOCoder
1.0.0
Implémentation officielle de la génération de code basée sur l'exécution à l'aide d'un apprentissage en renforcement profond
L'utilisation des modèles de langage de programmation (PL), pré-entraînées sur des corpus de code à grande échelle, comme moyen d'automatiser les processus d'ingénierie logicielle a démontré un potentiel considérable dans la rationalisation de diverses tâches de génération de code telles que l'achèvement du code, la traduction du code et la synthèse du programme. Cependant, les approches actuelles reposent principalement sur des objectifs de réglage fin supervisés empruntés à la génération de texte, négligeant des caractéristiques spécifiques au niveau de la séquence du code, y compris, mais sans s'y limiter, la compilabilité ainsi que l'exactitude syntaxique et fonctionnelle. Pour lutter contre cette limitation, nous proposons PpoDer , un nouveau cadre de génération de code qui combine des modèles PL pré-étendus avec un apprentissage en renforcement en profondeur de la politique proximale (PPO) et utilise la rétroaction d'exécution comme source externe de connaissances dans l'optimisation du modèle. PPOCODER est transférable sur différentes tâches de génération de code et PLS.
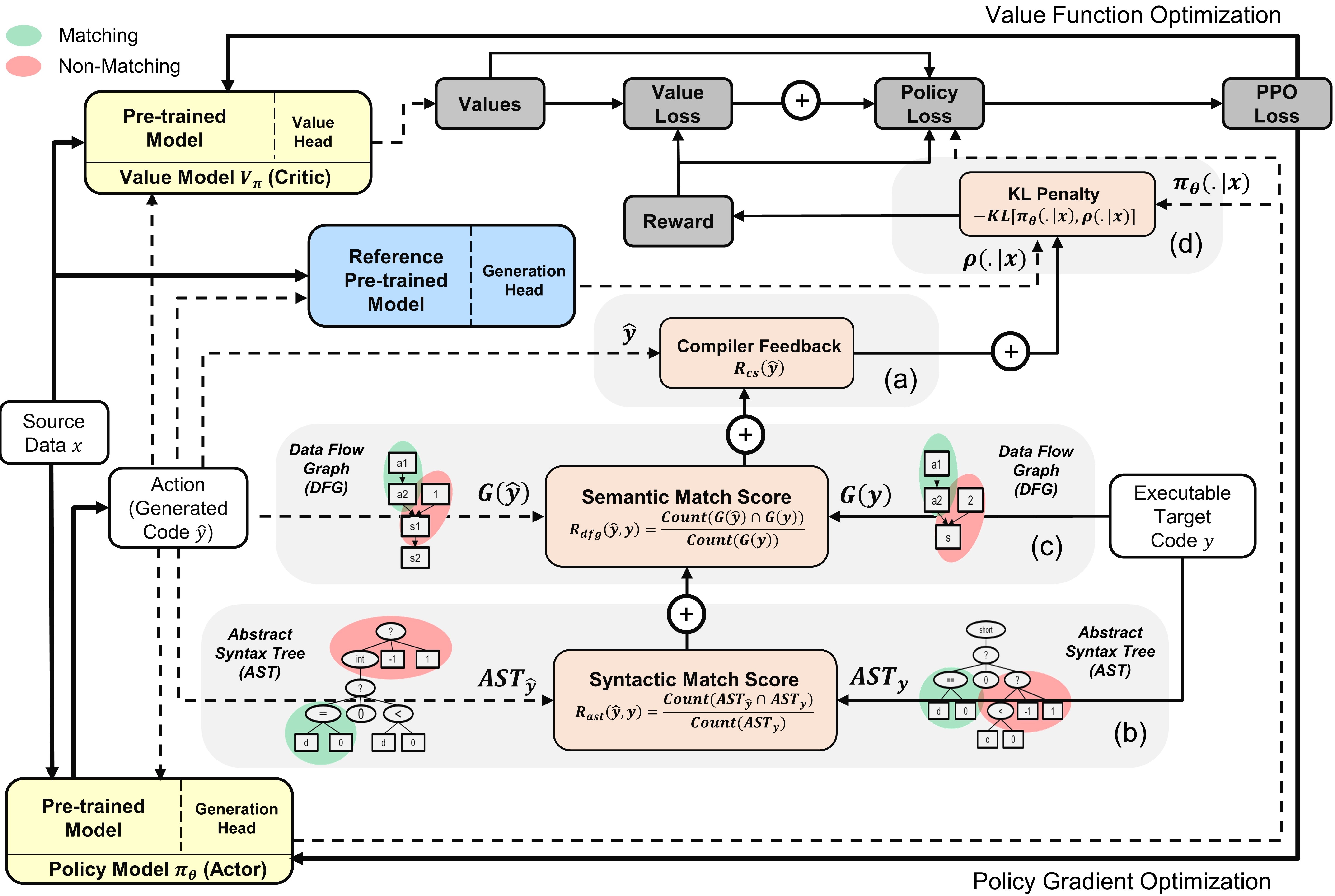
Présentation du ppocodeur avec des modèles d'acteur et de critique : l'action est échantillonnée à partir de la politique basée sur les données source données
Pour exécuter le code, installez les dépendances dans les exigences.txt.
pip install -r requirements.txt
Nous finettune / évaluons les modèles sur les principaux benchmarks de données suivants pour différentes tâches de génération de code:
Nous préparons les données et construisons des séquences d'entrée / sortie de la même manière que celles décrites dans les papiers de référence d'origine. Décompressez et placez tous les repères dans le dossier data .
Nous avons créé le script run.sh pour exécuter un réglage fin du modèle PPO basé sur PPO basé sur le signal du compilateur. Pour exécuter le script pour différentes tâches de génération de code, configurez les paramètres suivants:
| Paramètres | Description | Exemples de valeurs |
|---|---|---|
l1 | Langue source | Java |
l2 | Langue cible | cpp |
asp | Taille de l'espace d'action | 5 |
ns | Nombre d'échantillons synthétiques | 10 |
data_path | Chemin vers les échantillons de données d'origine | data / xlcost / java-cpp / |
output_path | Chemin pour enregistrer les générations et les sorties | Saved_results / java-cpp / |
baseline_output_dir | Chemin vers la base Finetuned Codet5 (avant RL) | Bâlelines / Saved_Models / Java-Cpp / |
load_model_path | Chemin vers le modèle de Codet5 Finetuned de base (avant RL) pour chaque tâche en aval | Bâlelines / Saved_Models / Java-Cpp / Pytorch_Model.bin |
max_source_length | Longueur de source maxmim | 400 |
max_target_length | Longueur cible maxmim | 400 |
train_batch_size | Taille du lot d'entraînement | 32 |
test_batch_size | Tester la taille du lot | 48 |
lr | Taux d'apprentissage | 1E-6 |
kl_coef | Coefficient initial de la pénalité de divergence KL dans la récompense | 0.1 |
kl_target | Cible du KL qui contrôle de manière adaptative le coefficient KL | 1 |
vf_coef | Coefficient de l'erreur VF dans la perte PPO | 1E-3 |
run | Index de la course | 1 |
L'exécution run.sh enregistre des programmes générés dans un fichier .txt et le modèle ponde à la fin de chaque époque.
Si vous trouvez le papier ou le repo utile, veuillez le citer avec
@article {shojaee2023ppocoder,
title = {Génération de code basée sur l'exécution à l'aide d'un apprentissage en renforcement profond},
auteur = {Shojaee, Parshin et Jain, Aneesh et Tipirneni, Sindhu et Reddy, Chandan K},
journal = {arXiv preprint arXiv: 2301.13816},
année = {2023}
}


