PPOCoder
1.0.0
Implementação oficial da geração de código baseada em execução usando o aprendizado de reforço profundo
A utilização dos modelos de linguagem de programação (PL), pré-criada em corpora de código em larga escala, como um meio de automatizar os processos de engenharia de software demonstrou um potencial considerável para simplificar várias tarefas de geração de código, como conclusão de código, tradução de código e síntese de programas. No entanto, as abordagens atuais dependem principalmente de objetivos de ajuste fino supervisionados emprestados da geração de texto, negligenciando recursos específicos no nível da sequência do código, incluindo, mas não limitado à compunhabilidade, bem como à correção sintática e funcional. Para abordar essa limitação, propomos o Ppocoder , uma nova estrutura para a geração de código que combina modelos de PL pré -terenciados com o aprendizado de reforço profundo da Política Proximal (PPO) e emprega feedback de execução como fonte externa de conhecimento na otimização do modelo. O ppocoder é transferível em diferentes tarefas e pls de geração de código.
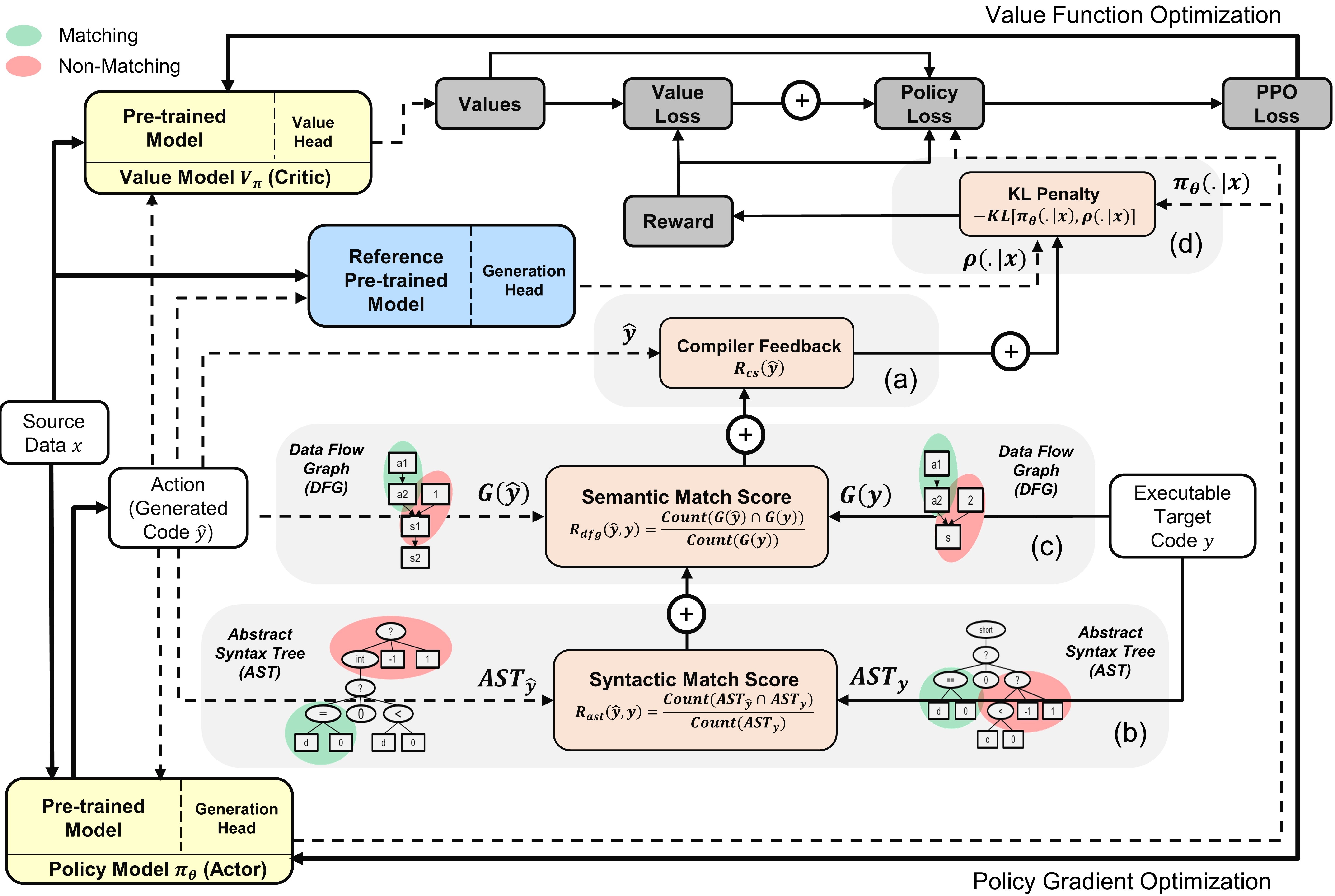
Visão geral do Ppocoder com modelos de ator e crítico : a ação é amostrada da política com base nos dados de origem especificados
Para executar o código, instale as dependências no requisitos.txt.
pip install -r requirements.txt
FinETune/Avaliamos modelos nos seguintes principais benchmarks de conjunto de dados para diferentes tarefas de geração de código:
Pré -processamos os dados e construímos sequências de entrada/saída da mesma maneira descrita nos documentos de referência original. Descompacte e coloque todos os benchmarks na pasta data .
Criamos o script run.sh para executar o ajuste fino do modelo PL baseado em PPO com base no sinal do compilador. Para executar o script para diferentes tarefas de geração de código, configure os seguintes parâmetros:
| Parâmetros | Descrição | Valores de exemplo |
|---|---|---|
l1 | Linguagem de origem | Java |
l2 | Linguagem alvo | cpp |
asp | Tamanho do espaço de ação | 5 |
ns | Número de amostras sintéticas | 10 |
data_path | Caminho para as amostras de dados originais | dados/xlCost/java-cpp/ |
output_path | Caminho para salvar gerações e saídas | SAVED_RESULTS/Java-CPP/ |
baseline_output_dir | Caminho para as saídas Base FinetUned CodeT5 (antes da RL) | linhas de base/saved_models/java-cpp/ |
load_model_path | Caminho para o modelo BASETUNED CODET5 (antes da RL) para cada tarefa a jusante | linhas de base/saved_models/java-cpp/pytorch_model.bin |
max_source_length | Comprimento da fonte maxmim | 400 |
max_target_length | Comprimento do alvo maxmim | 400 |
train_batch_size | TAMANHO DE TREINAMENTO TAMANHO | 32 |
test_batch_size | Testando o tamanho do lote | 48 |
lr | Taxa de aprendizado | 1e-6 |
kl_coef | Coeficiente inicial da penalidade de divergência de KL na recompensa | 0.1 |
kl_target | Alvo do KL que controla adaptativamente o coeficiente de KL | 1 |
vf_coef | Coeficiente do erro VF na perda de PPO | 1e-3 |
run | Índice da corrida | 1 |
Run run.sh salva programas gerados em um arquivo .txt e os pesos do modelo no final de cada época.
Se você achar útil o papel ou o repositório, cite -o com
@Article {Shojaee2023ppocoder,
title = {geração de código baseada em execução usando o aprendizado de reforço profundo},
autor = {Shojaee, Parshin e Jain, Aneesh e Tipirneni, Sindhu e Reddy, Chandan K},
Journal = {arxiv pré -impressão arxiv: 2301.13816},
ano = {2023}
}


