PPOCoder
1.0.0
Implementación oficial de la generación de código basada en la ejecución utilizando el aprendizaje de refuerzo profundo
La utilización de los modelos de lenguaje de programación (PL), previamente en los corpus de código a gran escala, como medio para automatizar procesos de ingeniería de software, ha demostrado un potencial considerable en la optimización de varias tareas de generación de código, como la finalización del código, la traducción de código y la síntesis del programa. Sin embargo, los enfoques actuales se basan principalmente en objetivos supervisados de ajuste fino tomados de la generación de texto, descuidando las características específicas a nivel de secuencia del código, incluida, entre otros, compilabilidad, así como corrección sintáctica y funcional. Para abordar esta limitación, proponemos PPOCoder , un nuevo marco para la generación de códigos que combina modelos PL pretrinidos con el aprendizaje de refuerzo profundo de optimización de políticas proximales (PPO) y emplea la retroalimentación de ejecución como fuente externa de conocimiento en la optimización del modelo. PPOCoder es transferible a través de diferentes tareas de generación de código y PLS.
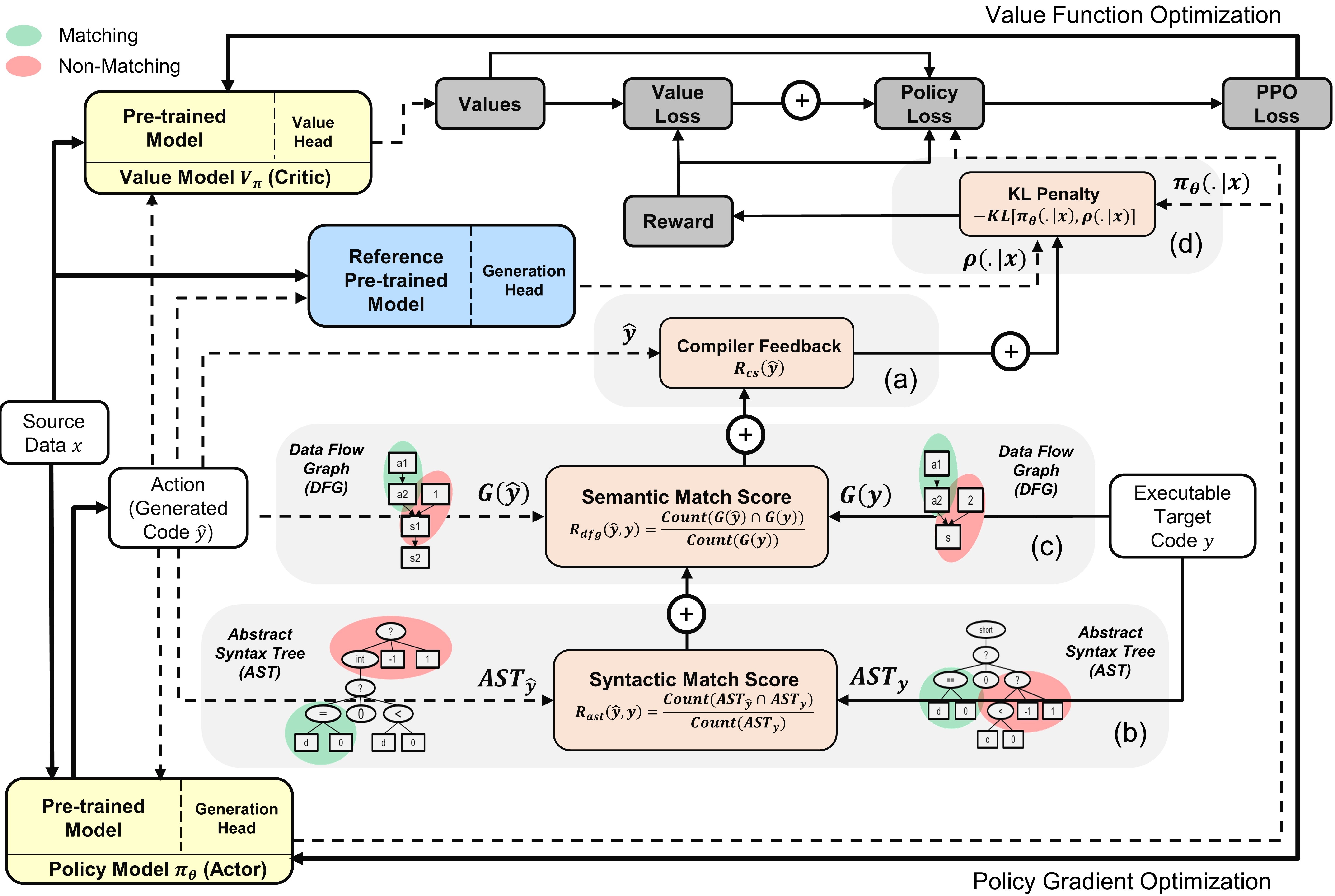
Descripción general del ppocoder con modelos de actor y crítico : la acción se muestrean a partir de la política basada en los datos de origen dados
Para ejecutar el código, instale las dependencias en requisitos.txt.
pip install -r requirements.txt
Finetune/evaluamos modelos en los siguientes puntos de referencia del conjunto de datos principales para diferentes tareas de generación de código:
Preprocesamos los datos y construimos secuencias de entrada/salida de la misma manera que se describe en los documentos de referencia originales. Descomprima y coloque todos los puntos de referencia en la carpeta data .
Hemos creado el script run.sh para ejecutar el modelo PL basado en PPO ajustado en función de la señal del compilador. Para ejecutar el script para diferentes tareas de generación de código, configure los siguientes parámetros:
| Parámetros | Descripción | Valores de ejemplo |
|---|---|---|
l1 | Lenguaje fuente | Java |
l2 | Lengua de llegada | CPP |
asp | Tamaño del espacio de acción | 5 |
ns | Número de muestras sintéticas | 10 |
data_path | Camino a las muestras de datos originales | datos/xlcost/java-cpp/ |
output_path | Ruta para guardar generaciones y salidas | saved_results/java-cpp/ |
baseline_output_dir | Ruta a las salidas Base Finetuned Codet5 (antes de RL) | líneas de base/saved_models/java-cpp/ |
load_model_path | Ruta al modelo Base Finetuned Codet5 (antes de RL) para cada tarea aguas abajo | líneas de base/saved_models/java-cpp/pytorch_model.bin |
max_source_length | MAXMIM Longitud de la fuente | 400 |
max_target_length | MAXMIM Longitud del objetivo | 400 |
train_batch_size | Tamaño de lote de entrenamiento | 32 |
test_batch_size | Prueba de tamaño por lotes | 48 |
lr | Tasa de aprendizaje | 1e-6 |
kl_coef | Coeficiente inicial de la penalización de divergencia de KL en la recompensa | 0.1 |
kl_target | Objetivo del KL que controla adaptativamente el coeficiente KL | 1 |
vf_coef | Coeficiente del error VF en la pérdida de PPO | 1e-3 |
run | Índice de la ejecución | 1 |
Run run.sh guarda programas generados en un archivo .txt y el modelo pesa al final de cada época.
Si encuentra útil el papel o el repositorio, cíquelo con
@article {shojaee2023ppocoder,
title = {Generación de código basada en ejecución utilizando el aprendizaje de refuerzo profundo},
Autor = {Shojaee, Parshin y Jain, Aneesh y Tipirneni, Sindhu y Reddy, Chandan K},
Journal = {arxiv preprint arxiv: 2301.13816},
año = {2023}
}


