PPOCoder
1.0.0
使用深入的强化学习的官方实施基于执行的代码生成
在大规模代码语料库中审议的编程语言(PL)模型的利用,作为自动化软件工程流程的一种手段,在简化各种代码生成任务(例如代码完成,代码翻译和程序合成)方面具有巨大的潜力。但是,当前的方法主要依赖于从文本生成中借来的监督微调目标,忽略了代码的特定序列级特征,包括但不限于汇编以及句法和功能正确性。为了解决这一限制,我们提出了PPOCODER ,这是一个新的代码生成框架,将预验证的PL模型与近端策略优化(PPO)深入强化学习结合在一起,并采用执行反馈作为模型优化中的知识来源。 PPOCODER可以在不同的代码生成任务和PLS中转移。
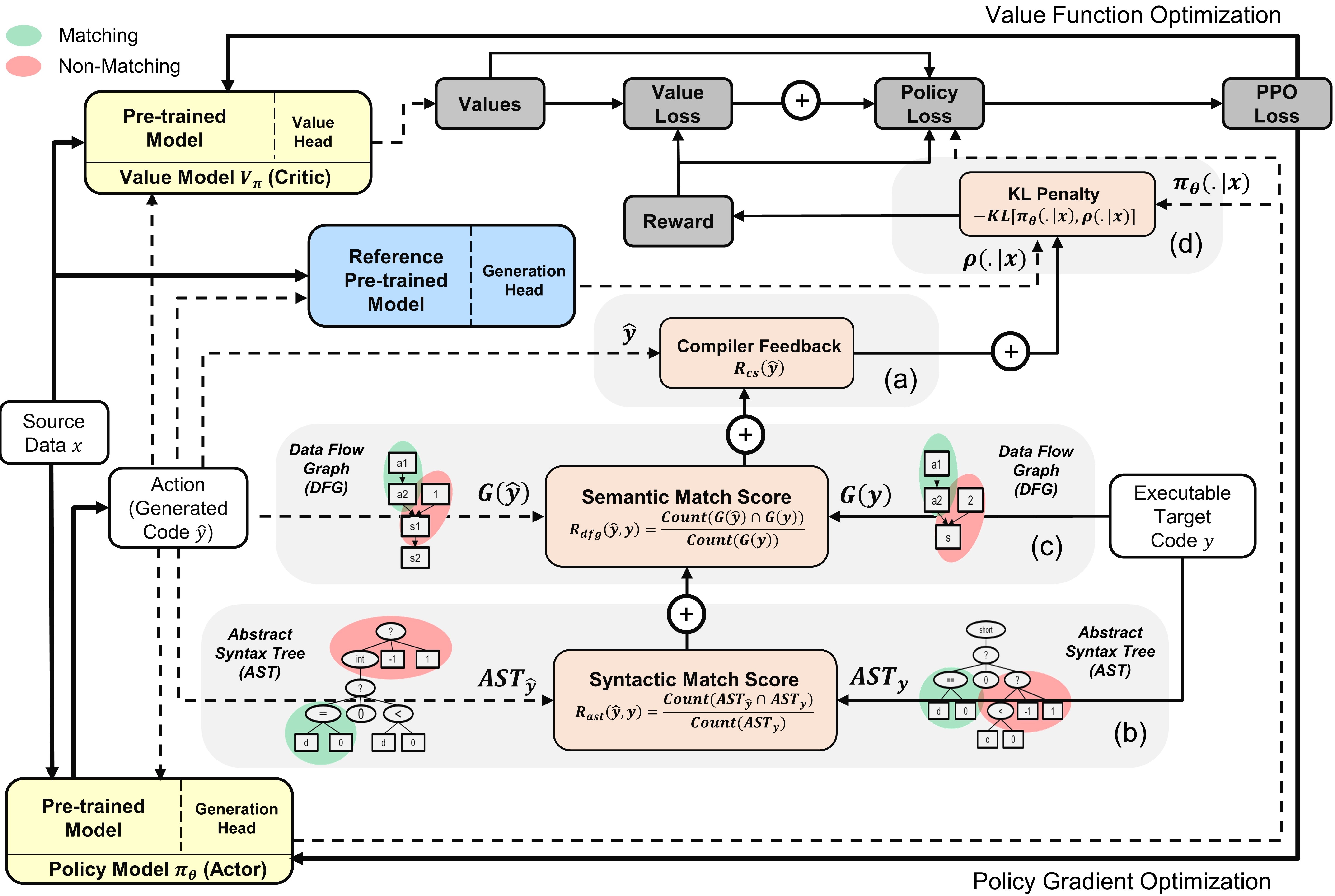
带有演员和评论家模型的PPOCODER概述:根据给定的源数据,该动作是从策略中抽样的
要运行代码,请将依赖项安装在unignts.txt中。
pip install -r requirements.txt
我们对不同代码生成任务的以下主要数据集基准进行了Finetune/评估模型:
我们以与原始基准论文中概述的方式相同的方式预处理数据并构建输入/输出序列。解压缩并将所有基准放在data文件夹中。
我们创建了run.sh脚本以基于编译器信号执行基于PPO的PL模型微调。要运行不同代码生成任务的脚本,请配置以下参数:
| 参数 | 描述 | 示例值 |
|---|---|---|
l1 | 源语言 | 爪哇 |
l2 | 目标语言 | CPP |
asp | 动作空间大小 | 5 |
ns | 合成样品的数量 | 10 |
data_path | 原始数据样本的路径 | 数据/XLCOST/JAVA-CPP/ |
output_path | 保存世代和输出的路径 | saved_results/java-cpp/ |
baseline_output_dir | 基础固定的codet5(RL之前)输出的路径 | 基线/saved_models/java-cpp/ |
load_model_path | 对于每个下游任务 | 基线/saved_models/java-cpp/pytorch_model.bin |
max_source_length | maxmim源长度 | 400 |
max_target_length | MAXMIM目标长度 | 400 |
train_batch_size | 培训批量大小 | 32 |
test_batch_size | 测试批次尺寸 | 48 |
lr | 学习率 | 1E-6 |
kl_coef | 奖励中KL DiverGunty的初始系数 | 0.1 |
kl_target | KL的靶标能够自适应控制KL系数 | 1 |
vf_coef | PPO丢失中VF误差的系数 | 1E-3 |
run | 运行索引 | 1 |
运行run.sh将生成的程序保存在.txt文件和每个时期末尾的模型权重。
如果您发现纸张或存储库有用,请引用
@article {shojaee2023ppocoder,
title = {基于执行的代码生成使用深钢筋学习},
作者= {Shojaee,Parshin和Jain,Aneesh和Tipirneni,Sindhu和Reddy,Chandan K},
日记= {arxiv预印arxiv:2301.13816},
年= {2023}
}


