PPOCoder
1.0.0
การใช้งานการสร้างรหัสตามการดำเนินการอย่างเป็นทางการโดยใช้การเรียนรู้การเสริมแรงอย่างลึกซึ้ง
การใช้ประโยชน์จากโมเดลการเขียนโปรแกรมภาษา (PL) ซึ่งได้รับการฝึกฝนเกี่ยวกับรหัสขนาดใหญ่ Corpora ซึ่งเป็นวิธีการของกระบวนการทางวิศวกรรมซอฟต์แวร์อัตโนมัติได้แสดงให้เห็นถึงความเป็นไปได้อย่างมากในการปรับปรุงงานการสร้างรหัสต่างๆเช่นการสมบูรณ์ของรหัสการแปลรหัสและการสังเคราะห์โปรแกรม อย่างไรก็ตามวิธีการในปัจจุบันส่วนใหญ่ขึ้นอยู่กับวัตถุประสงค์การปรับจูนที่ได้รับการดูแลที่ยืมมาจากการสร้างข้อความโดยละเลยคุณสมบัติระดับลำดับที่เฉพาะเจาะจงของรหัสรวมถึง แต่ไม่ จำกัด เพียงการรวบรวมรวมถึงความถูกต้องของวากยสัมพันธ์และการใช้งาน เพื่อจัดการกับข้อ จำกัด นี้เราเสนอ PPOCODER ซึ่งเป็นเฟรมเวิร์กใหม่สำหรับการสร้างรหัสที่รวมโมเดล PL ที่ได้รับการฝึกฝนไว้กับการเพิ่มประสิทธิภาพนโยบายใกล้เคียง (PPO) การเรียนรู้การเสริมแรงอย่างลึกซึ้งและใช้การตอบรับการดำเนินการเป็นแหล่งความรู้ภายนอกในการเพิ่มประสิทธิภาพแบบจำลอง PPOCODER สามารถถ่ายโอนได้ในงานและการสร้างรหัสที่แตกต่างกัน
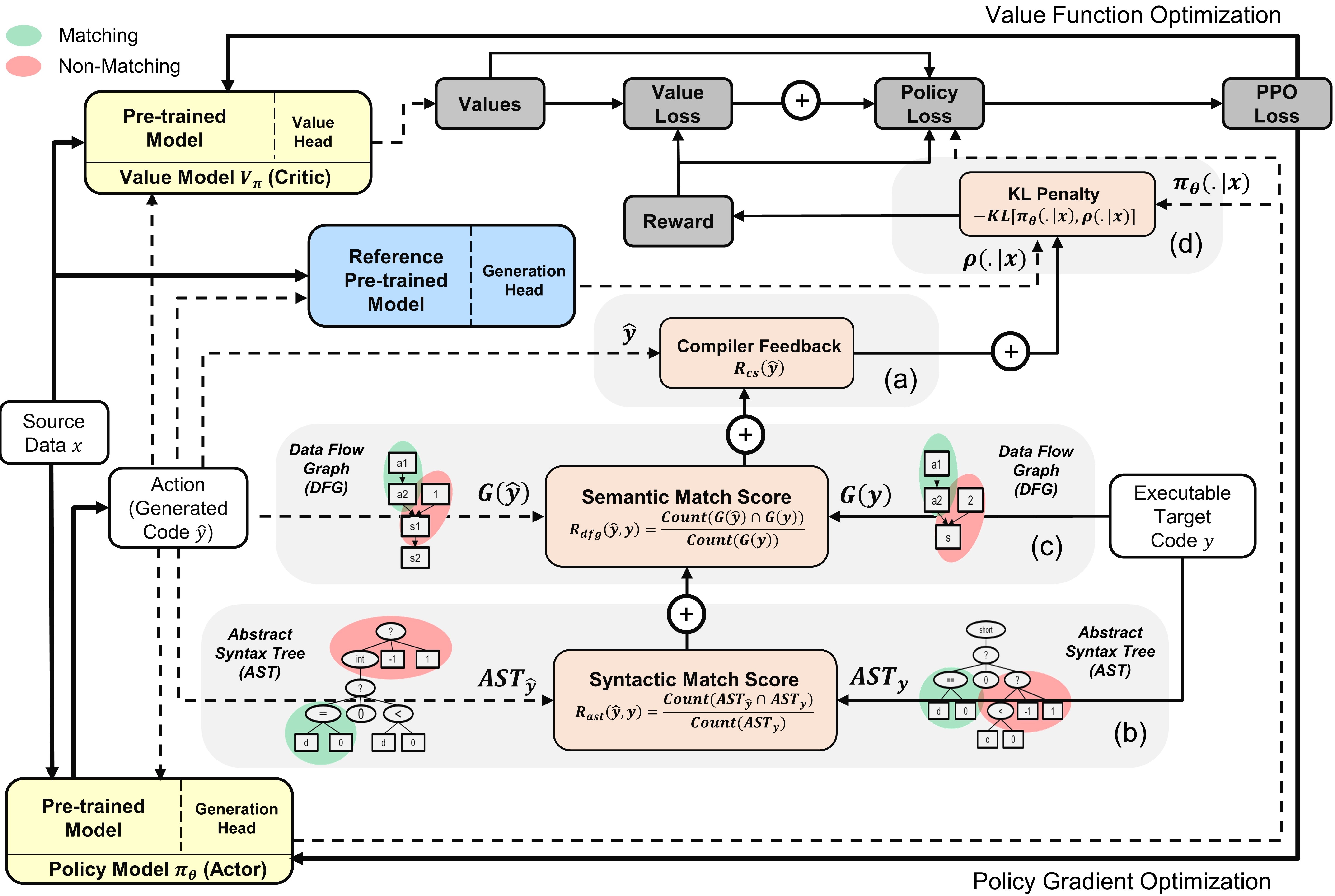
ภาพรวมของ ppocoder กับโมเดลนักแสดงและนักวิจารณ์ : การกระทำนั้นถูกสุ่มตัวอย่างจากนโยบายตามข้อมูลแหล่งที่มา
ในการเรียกใช้รหัสให้ติดตั้งการพึ่งพาในข้อกำหนด. txt
pip install -r requirements.txt
เรา finetune/ประเมินโมเดลบนมาตรฐานชุดข้อมูลสำคัญต่อไปนี้สำหรับงานสร้างรหัสที่แตกต่างกัน:
เราประมวลผลข้อมูลล่วงหน้าและสร้างลำดับอินพุต/เอาต์พุตในลักษณะเดียวกับที่ระบุไว้ในเอกสารมาตรฐานดั้งเดิม คลายซิปและวางเกณฑ์มาตรฐานทั้งหมดในโฟลเดอร์ data
เราได้สร้างสคริปต์ run.sh เพื่อดำเนินการปรับแต่งโมเดล PL แบบ PPO ตามสัญญาณคอมไพเลอร์ ในการเรียกใช้สคริปต์สำหรับงานการสร้างรหัสที่แตกต่างกันกำหนดค่าพารามิเตอร์ต่อไปนี้:
| พารามิเตอร์ | คำอธิบาย | ค่าตัวอย่าง |
|---|---|---|
l1 | ภาษาต้นฉบับ | ชวา |
l2 | ภาษาเป้าหมาย | CPP |
asp | ขนาดพื้นที่แอ็คชั่น | 5 |
ns | จำนวนตัวอย่างสังเคราะห์ | 10 |
data_path | เส้นทางไปยังตัวอย่างข้อมูลดั้งเดิม | ข้อมูล/xlcost/java-cpp/ |
output_path | เส้นทางที่จะบันทึกรุ่นและเอาต์พุต | saved_results/java-cpp/ |
baseline_output_dir | เส้นทางไปยังเอาต์พุตพื้นฐาน codetuned (ก่อน RL) เอาต์พุต | baselines/saved_models/java-cpp/ |
load_model_path | เส้นทางไปยังโมเดล codetuned พื้นฐาน 5 (ก่อน RL) สำหรับแต่ละงานดาวน์สตรีม | baselines/saved_models/java-cpp/pytorch_model.bin |
max_source_length | ความยาวแหล่งที่มาของ maxmim | 400 |
max_target_length | ความยาวเป้าหมายสูงสุด | 400 |
train_batch_size | ขนาดชุดการฝึกอบรม | 32 |
test_batch_size | ขนาดชุดทดสอบ | 48 |
lr | อัตราการเรียนรู้ | 1E-6 |
kl_coef | ค่าสัมประสิทธิ์เริ่มต้นของการลงโทษ KL Divergence ในรางวัล | 0.1 |
kl_target | เป้าหมายของ KL ซึ่งควบคุมค่าสัมประสิทธิ์ KL แบบปรับตัวได้ | 1 |
vf_coef | ค่าสัมประสิทธิ์ข้อผิดพลาด VF ในการสูญเสีย PPO | 1E-3 |
run | ดัชนีของการรัน | 1 |
Run run.sh บันทึกโปรแกรมที่สร้างขึ้นในไฟล์ .txt และน้ำหนักรุ่นในตอนท้ายของแต่ละยุค
หากคุณพบว่ากระดาษหรือ repo มีประโยชน์โปรดอ้างอิงด้วย
@article {shojaee2023ppocoder
title = {การสร้างรหัสตามการดำเนินการโดยใช้การเรียนรู้การเสริมแรงลึก}
ผู้แต่ง = {Shojaee, Parshin และ Jain, Aneesh และ Tipirneni, Sindhu และ Reddy, Chandan K}
journal = {arxiv preprint arxiv: 2301.13816},
ปี = {2023}
-


