PPOCoder
1.0.0
Offizielle Implementierung der ausführungsbasierten Codegenerierung mit tiefem Verstärkungslernen
Die Nutzung von Programmiersprache (PL) -Modellen (PL), die auf groß angelegten Code-Korpora als Mittel zur Automatisierung von Software-Engineering-Prozessen vorgelegt wurden, hat ein beträchtliches Potenzial für die Staffnung verschiedener Aufgaben zur Codegenerierung wie Codeabschluss, Codeübersetzung und Programmsynthese gezeigt. Aktuelle Ansätze beruhen jedoch hauptsächlich auf beaufsichtigte Feinabstimmungsziele, die aus der Textgenerierung entlehnt wurden, und vernachlässigen spezifische Merkmale von Code auf Sequenzebene, einschließlich, aber nicht beschränkt auf Kompilierbarkeit sowie syntaktische und funktionale Richtigkeit. Um diese Einschränkung anzugehen, schlagen wir PPOCODER vor, einen neuen Rahmen für die Codegenerierung, das vorgezogene PL -Modelle mit der Lernen des Tiefenverstärkers mit proximaler Richtlinien (PPO) kombiniert und Ausführungsfeedback als externe Wissensquelle in die Modelloptimierung verwendet. PPOCODER ist über verschiedene Aufgaben und PLs mit Codegenerierung übertragbar.
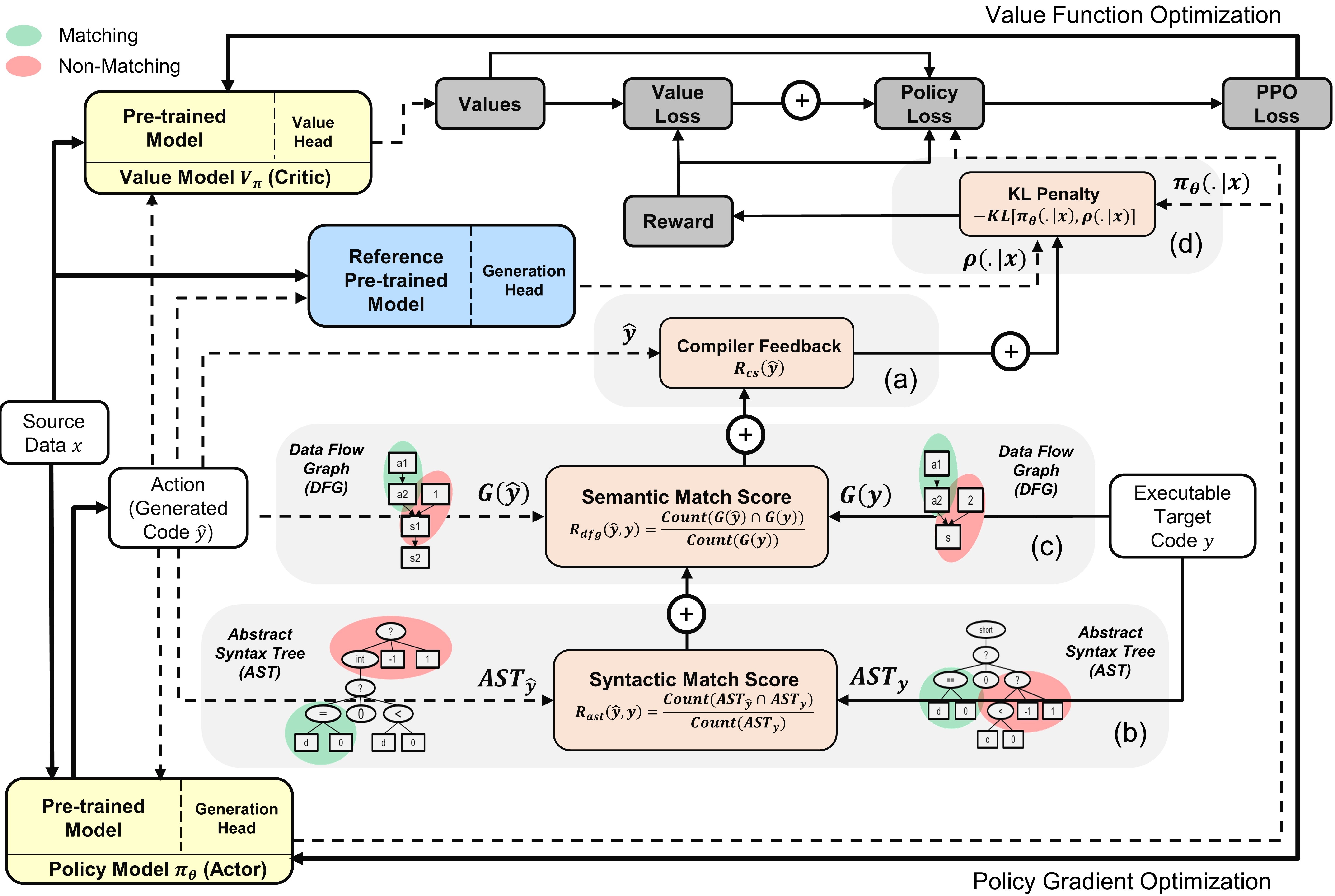
Überblick über den PPOCODER mit Akteur- und Kritikermodellen : Die Aktion wird aus der Richtlinie basierend auf den angegebenen Quelldaten abgetastet
Um den Code auszuführen, installieren Sie die Abhängigkeiten in Anforderungen.txt.
pip install -r requirements.txt
Wir finanzieren/bewerten Modelle für die folgenden Hauptdatensatz -Benchmarks für verschiedene Aufgaben zur Codegenerierung:
Wir haben die Daten vorbereitet und konstruieren Eingangs-/Ausgangssequenzen auf die gleiche Weise wie in den ursprünglichen Benchmark -Papieren. Entpacken Sie alle Benchmarks in den data .
Wir haben run.sh -Skript erstellt, um PPO-basierte PL-Modell-Feinabstimmung basierend auf dem Compiler-Signal auszuführen. Konfigurieren Sie die folgenden Parameter, um das Skript für verschiedene Aufgaben zur Codegenerierung auszuführen:
| Parameter | Beschreibung | Beispielwerte |
|---|---|---|
l1 | Quellensprache | Java |
l2 | Zielsprache | CPP |
asp | Aktionsraumgröße | 5 |
ns | Anzahl der synthetischen Proben | 10 |
data_path | Pfad zu den ursprünglichen Datenproben | Data/xlcost/java-cpp/ |
output_path | Pfad zum Speichern von Generationen und Ausgängen | SAVED_RESULTS/JAVA-CPP/ |
baseline_output_dir | Pfad zum Basisfonetuned Codet5 (vor RL) Ausgängen | Baselines/Saved_Models/Java-CPP/ |
load_model_path | Pfad zum Basis -Finetuned Codet5 -Modell (vor RL) für jede nachgeschaltete Aufgabe | Baselines/Saved_Models/Java-CPP/Pytorch_Model.bin |
max_source_length | Maxmim -Quellenlänge | 400 |
max_target_length | Maxmim Ziellänge | 400 |
train_batch_size | Trainingseinheitgröße | 32 |
test_batch_size | Stapelgröße testen | 48 |
lr | Lernrate | 1E-6 |
kl_coef | Anfangskoeffizient der KL -Divergenzstrafe in der Belohnung | 0,1 |
kl_target | Ziel des KL, das den KL -Koeffizienten adaptiv steuert | 1 |
vf_coef | Koeffizient des VF -Fehlers im PPO -Verlust | 1e-3 |
run | Index des Laufs | 1 |
Running run.sh speichert generierte Programme in einer .txt -Datei und die Modellgewichte am Ende jeder Epoche.
Wenn Sie das Papier oder das Repo nützlich finden, zitieren Sie es bitte mit
@Article {Shojaee2023Pocoder,
title = {ausführungsbasierte Codegenerierung mit Deep verstärkten Lernen},
Autor = {Shojaee, Parshin und Jain, Aneesh und Tipirneni, Sindhu und Reddy, Chandan K},
Journal = {Arxiv Preprint Arxiv: 2301.13816},
Jahr = {2023}
}


