EasyRLHF
1.0.0
EasyRLHF旨在使用現成的解決方案和數據集(即HF Trainer,HF數據集,DeepSpeed,TRL)提供簡單且最小的接口來訓練對齊語言模型。
以下各節將涵蓋對齊方法的粗略概念(RLHF,RRHF,DPO,IPO),並提供如何運行示例。
如《指示》論文所示,我們可以訓練獎勵模型並加強語言模型以更好地遵循人類的指示。我們可以首先使用hh-rlhf數據集和slimorca-dedup數據集進行培訓獎勵模型和SFT-LM。然後可以使用TRL庫培訓PPO-LM。
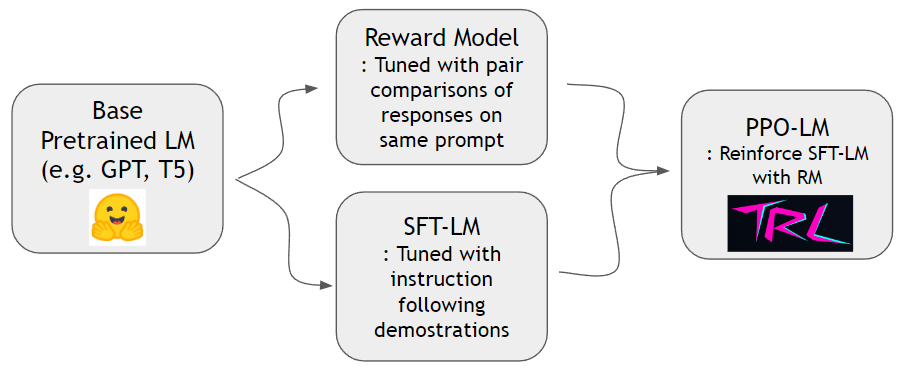
我們需要成對比較數據集來訓練獎勵模型。在指示紙中,作者在同一提示下使用了4〜9排名的連續性。例如, A < B < C = D < E是一個排名序列,一個可以採樣兩個任意樣本(A和C)。在這裡,C贏得了人類偏好的一項。因此,我們將logit of C - logit of A建模為c的log頻率比A。 x logit of X log頻率比A。我們通過人類使用HH-RLHF的現成數據集。該數據集已經平坦,因此我們不必擔心指令紙中討論的採樣方案。
我們可以使用Slimorca-Dedup培訓SFT模型。
現在,我們有了獎勵模型和SFT模型,我們可以使用為語言模型設計的現成的RL軟件包進行增強學習。我們使用TRLTO加強SFT模型。在PPO階段,我們將SFT模型的副本保留為參考。該參考模型允許行為模型學會在避免獎勵黑客攻擊的同時學習增加人類偏好。具體而言,行為模型首先生成給定提示的完成。通過最小化針對參考模型的令牌分佈的KL差異,令牌分佈可保持接近參考模型。完成一個完成獎勵模型以獲得獎勵分數。 KL期限和獎勵分數被求和,並被視為PPO算法的獎勵。
conda create -n easy-rlhf python=3.8
git clone https://github.com/DaehanKim/EasyRLHF.git
cd EasyRLHF
pip install .
rm_train CMD訓練獎勵模型 cd data
find . -name '*.gz' -print0 | xargs -0 gzip -d
rm_train --devices "0,1,2,3"
--output_dir "outputs/my-model"
--train_data data/helpful-base/train.jsonl,data/helpful-online/train.jsonl,data/helpful-rejection-sampled/train.jsonl
--valid_data data/helpful-base/test.jsonl,data/helpful-online/test.jsonl,data/helpful-rejection-sampled/test.jsonl
scripts/rm_train.sh進行更多自定義的設置configs/ds_config.yaml中,您可以在其中設置首選的分佈式設置。默認值設置為零2並行性。TBD
TBD
TBD
該項目僅綁定了來自各種來源的庫和數據集,因此在相應來源的許可條款下。綁定腳本本身是許可的麻省理工學院。


