EasyRLHF
1.0.0
EASYRLHF стремится предоставить простой и минимальный интерфейс для обучения выровненных языковых моделей, используя готовые решения и наборы данных (т.е. тренер HF, наборы данных HF, DeepSpeed, TRL).
Следующие разделы будут охватывать грубые концепции методов выравнивания (RLHF, RRHF, DPO, IPO) и предоставит примеры.
Как показано в документе «Инструктор», мы можем обучить модель вознаграждения и усилить языковую модель, чтобы лучше следовать человеческим инструкциям. Мы можем сначала построить модель вознаграждения и SFT-LM с набором данных hh-rlhf и набором данных slimorca-dedup , соответственно. Затем PPO-LM может быть обучен библиотекой TRL.
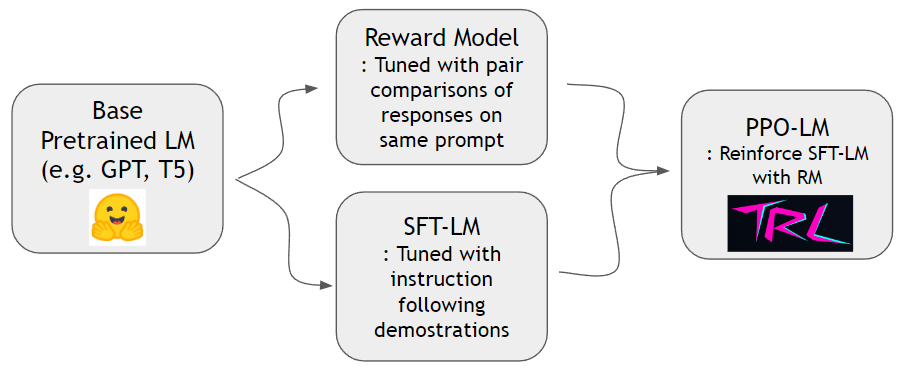
Нам нужен набор данных для парного сравнения для обучения модели вознаграждения. В документе «Инструктор» авторы использовали 4 ~ 9 ранжированных продолжений по той же подсказке. Например, A < B < C = D < E - ранга, и можно обратить внимание на два произвольных образца (a и c). Здесь C выигрывает над человеческими предпочтениями. Таким образом, мы моделируем logit of C - logit of A чтобы быть логическим шансом на C, лучшую демонстрацию, чем A. logit of X может быть рассчитана с помощью линейной головки, прикрепленной в верхней части декодера трансформатора. Мы используем готовый набор данных от HH-RLHF от антропного. Этот набор данных уже ровный, поэтому нам не нужно беспокоиться о схемах выборки, обсуждаемых в документе «Инструктор».
Мы можем обучить модель SFT со стандартной следующей точкой, используя Slimorca-Dedup.
Теперь, когда у нас есть модель вознаграждения и модель SFT, мы можем провести обучение подкреплению с помощью готовых пакетов RL, предназначенных для языковых моделей. Мы используем TRLTO Укрепление модели SFT. На этапе PPO мы сохраняем копию модели SFT для справки. Эта эталонная модель позволяет модели поведения научиться увеличивать предпочтения человека, избегая при этом взлома вознаграждения. В частности, модель поведения сначала генерирует подсказку о завершении. Распределения токенов хранятся близко к эталонной модели, минимизируя KL-дивергентность по сравнению с распределением токенов эталонной модели. Завершение питается для вознаграждения, чтобы получить оценку вознаграждения. КОР КЛ и Оценка вознаграждения суммируются и рассматриваются как награда за алгоритм ППО.
conda create -n easy-rlhf python=3.8
git clone https://github.com/DaehanKim/EasyRLHF.git
cd EasyRLHF
pip install .
rm_train CMD cd data
find . -name '*.gz' -print0 | xargs -0 gzip -d
rm_train --devices "0,1,2,3"
--output_dir "outputs/my-model"
--train_data data/helpful-base/train.jsonl,data/helpful-online/train.jsonl,data/helpful-rejection-sampled/train.jsonl
--valid_data data/helpful-base/test.jsonl,data/helpful-online/test.jsonl,data/helpful-rejection-sampled/test.jsonl
scripts/rm_train.sh для более индивидуальных настроекconfigs/ds_config.yaml где вы можете установить предпочтительную распределенную настройку. По умолчанию установлено параллелизм Zero-2.TBD
TBD
TBD
Этот проект просто связывает библиотеки и наборы данных из различных источников, поэтому находится в условиях лицензии соответствующих источников. Сам сценарий привязки является лицензированным MIT.


