EasyRLHF
1.0.0
EasyRLHF旨在使用现成的解决方案和数据集(即HF Trainer,HF数据集,DeepSpeed,TRL)提供简单且最小的接口来训练对齐语言模型。
以下各节将涵盖对齐方法的粗略概念(RLHF,RRHF,DPO,IPO),并提供如何运行示例。
如《指示》论文所示,我们可以训练奖励模型并加强语言模型以更好地遵循人类的指示。我们可以首先使用hh-rlhf数据集和slimorca-dedup数据集进行培训奖励模型和SFT-LM。然后可以使用TRL库培训PPO-LM。
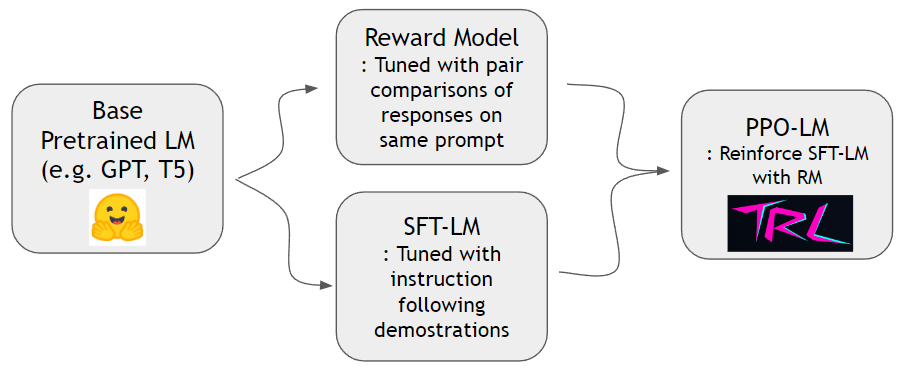
我们需要成对比较数据集来训练奖励模型。在指示纸中,作者在同一提示下使用了4〜9排名的连续性。例如, A < B < C = D < E是一个排名序列,一个可以采样两个任意样本(A和C)。在这里,C赢得了人类偏好的一项。因此,我们将logit of C - logit of A建模为c的log频率比A。x logit of X log频率比A。我们通过人类使用HH-RLHF的现成数据集。该数据集已经平坦,因此我们不必担心指令纸中讨论的采样方案。
我们可以使用Slimorca-Dedup培训SFT模型。
现在,我们有了奖励模型和SFT模型,我们可以使用为语言模型设计的现成的RL软件包进行增强学习。我们使用TRLTO加强SFT模型。在PPO阶段,我们将SFT模型的副本保留为参考。该参考模型允许行为模型学会在避免奖励黑客攻击的同时学习增加人类偏好。具体而言,行为模型首先生成给定提示的完成。通过最小化针对参考模型的令牌分布的KL差异,令牌分布可保持接近参考模型。完成一个完成奖励模型以获得奖励分数。 KL期限和奖励分数被求和,并被视为PPO算法的奖励。
conda create -n easy-rlhf python=3.8
git clone https://github.com/DaehanKim/EasyRLHF.git
cd EasyRLHF
pip install .
rm_train CMD训练奖励模型 cd data
find . -name '*.gz' -print0 | xargs -0 gzip -d
rm_train --devices "0,1,2,3"
--output_dir "outputs/my-model"
--train_data data/helpful-base/train.jsonl,data/helpful-online/train.jsonl,data/helpful-rejection-sampled/train.jsonl
--valid_data data/helpful-base/test.jsonl,data/helpful-online/test.jsonl,data/helpful-rejection-sampled/test.jsonl
scripts/rm_train.sh进行更多自定义的设置configs/ds_config.yaml中,您可以在其中设置首选的分布式设置。默认值设置为零2并行性。TBD
TBD
TBD
该项目仅绑定了来自各种来源的库和数据集,因此在相应来源的许可条款下。绑定脚本本身是许可的麻省理工学院。


