EasyRLHF
1.0.0
EasyRLHFは、既製のソリューションとデータセット(IE HFトレーナー、HFデータセット、DeepSpeed、TRL)を使用して、アライメントされた言語モデルをトレーニングするための簡単で最小限のインターフェイスを提供することを目指しています。
次のセクションでは、アライメントメソッドの大まかな概念(RLHF、RRHF、DPO、IPO)をカバーし、例を実行する方法を提供します。
Instructgpt Paperに示されているように、報酬モデルを訓練し、人間の指示に従うために言語モデルを強化することができます。 hh-rlhfデータセットとslimorca-dedup Datasetを使用して、まず報酬モデルとSFT-LMをトレーニングできます。その後、PPO-LMはTRLライブラリでトレーニングできます。
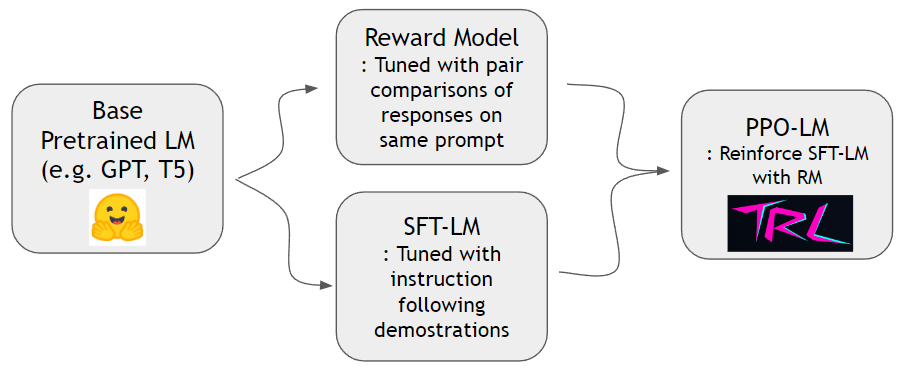
報酬モデルをトレーニングするには、ペアワイズ比較データセットが必要です。 Instructgpt Paperでは、著者は同じプロンプトで4〜9ランク付けされた継続を使用しました。たとえば、 A < B < C = D < Eランク付けされたシーケンスであり、2つの任意のサンプル(AとC)をサンプリングできます。ここで、Cは人間の好みに勝ちます。したがって、 logit of C - logit of Aモデル化して、cがAよりも優れたデモンストレーションであるというログオッズになりますlogit of Xトランスデコーダーの上部に取り付けられた線形ヘッドによって計算できます。人類によってHH-RLHFの既製のデータセットを使用します。このデータセットはすでにフラットなので、instructgptペーパーで説明されているサンプリングスキームについて心配する必要はありません。
Slimorca-Dedupを使用して、標準の次のトークン予測でSFTモデルをトレーニングできます。
報酬モデルとSFTモデルができたので、言語モデル向けに設計された既製のRLパッケージを使用して、強化学習を行うことができます。 SFTモデルを補強するTRLTOを使用します。 PPO段階では、参照のためにSFTモデルのコピーを保持します。この参照モデルにより、行動モデルは報酬のハッキングを避けながら、人間の好みを高めることを学ぶことができます。具体的には、動作モデルは最初に完了したプロンプトを生成します。トークン分布は、参照モデルのトークン分布に対するkl-divergenceを最小化することにより、参照モデルの近くに保持されます。報酬スコアを取得するためにモデルに報酬を与えるために完了が提供されます。 KLタームと報酬スコアは合計され、PPOアルゴリズムの報酬と見なされます。
conda create -n easy-rlhf python=3.8
git clone https://github.com/DaehanKim/EasyRLHF.git
cd EasyRLHF
pip install .
rm_train CMDを使用して、HH-RLHFデータセットを解凍し、報酬モデルをトレーニングします cd data
find . -name '*.gz' -print0 | xargs -0 gzip -d
rm_train --devices "0,1,2,3"
--output_dir "outputs/my-model"
--train_data data/helpful-base/train.jsonl,data/helpful-online/train.jsonl,data/helpful-rejection-sampled/train.jsonl
--valid_data data/helpful-base/test.jsonl,data/helpful-online/test.jsonl,data/helpful-rejection-sampled/test.jsonl
scripts/rm_train.shを使用できますconfigs/ds_config.yamlで、優先分布設定を設定できます。デフォルトはZero-2並列性に設定されています。TBD
TBD
TBD
このプロジェクトは、さまざまなソースからのライブラリとデータセットを拘束するだけなので、対応するソースのライセンス条件にもかかっています。バインディングスクリプト自体はライセンスされたMITです。


