EasyRLHF
1.0.0
EasyrlHF มีจุดมุ่งหมายเพื่อให้อินเทอร์เฟซที่ง่ายและน้อยที่สุดในการฝึกอบรมแบบจำลองภาษาที่จัดตำแหน่งโดยใช้โซลูชันนอกชั้นวางและชุดข้อมูล (เช่น HF Trainer, ชุดข้อมูล HF, DeepSpeed, TRL)
ส่วนต่อไปนี้จะครอบคลุมแนวคิดคร่าวๆของวิธีการจัดตำแหน่ง (RLHF, RRHF, DPO, IPO) และให้วิธีเรียกใช้ตัวอย่าง
ดังที่แสดงในกระดาษ InstructGPT เราสามารถฝึกอบรมรูปแบบรางวัลและเสริมรูปแบบภาษาเพื่อทำตามคำแนะนำของมนุษย์ได้ดีขึ้น ก่อนอื่นเราสามารถฝึกอบรมรุ่นรางวัลและ SFT-LM ด้วยชุดข้อมูล hh-rlhf และชุดข้อมูล slimorca-dedup ตามลำดับ จากนั้น PPO-LM สามารถได้รับการฝึกฝนด้วยห้องสมุด TRL
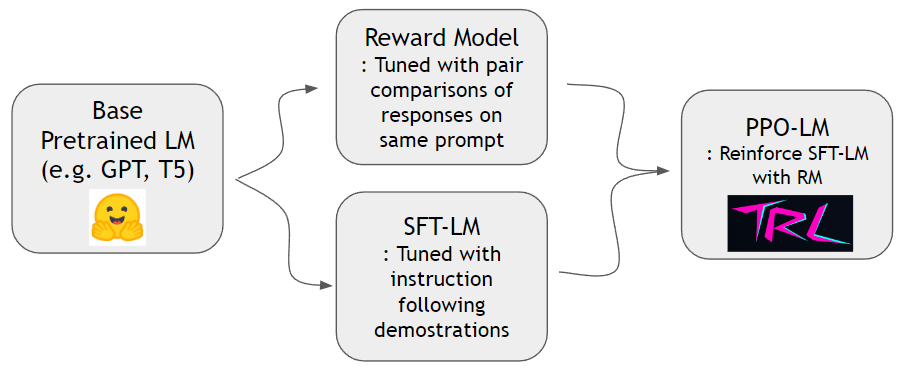
เราต้องการชุดข้อมูลการเปรียบเทียบแบบคู่เพื่อฝึกอบรมรูปแบบรางวัล ในกระดาษ InstructGPT ผู้เขียนใช้ 4 ~ 9 อันดับความต่อเนื่องในพรอมต์เดียวกัน ตัวอย่างเช่น A < B < C = D < E เป็นลำดับการจัดอันดับและหนึ่งสามารถสุ่มตัวอย่างสองตัวอย่างโดยพลการ (A และ C) ที่นี่ C ชนะเหนือความชอบของมนุษย์ ดังนั้นเรารูปแบบ logit of C - logit of A เป็นอัตราต่อรองของ C เป็นสาธิตที่ดีกว่า A. logit of X สามารถคำนวณได้โดยหัวเชิงเส้นที่ติดอยู่ที่ด้านบนของตัวถอดรหัสหม้อแปลง เราใช้ชุดข้อมูลนอกชั้นวางจาก HH-RLHF โดยมานุษยวิทยา ชุดข้อมูลนี้แบนอยู่แล้วดังนั้นเราไม่จำเป็นต้องกังวลเกี่ยวกับรูปแบบการสุ่มตัวอย่างที่กล่าวถึงใน PAPERTICGPT
เราสามารถฝึกอบรมโมเดล SFT ด้วยการคาดการณ์แบบ token มาตรฐานโดยใช้ Slimorca-Dedup
ตอนนี้เรามีรูปแบบรางวัลและโมเดล SFT เราสามารถทำการเรียนรู้การเสริมแรงด้วยแพ็คเกจ RL นอกชั้นวางที่ออกแบบมาสำหรับแบบจำลองภาษา เราใช้ trlto เสริมสร้างโมเดล SFT ในขั้นตอน PPO เราเก็บสำเนาโมเดล SFT ไว้สำหรับการอ้างอิง รูปแบบการอ้างอิงนี้ช่วยให้แบบจำลองพฤติกรรมสามารถเรียนรู้ที่จะเพิ่มความชอบของมนุษย์ในขณะที่หลีกเลี่ยงการแฮ็ครางวัล โดยเฉพาะรูปแบบพฤติกรรมจะสร้างความสำเร็จให้เสร็จสมบูรณ์เป็นครั้งแรก การแจกแจงโทเค็นจะถูกเก็บไว้ใกล้กับโมเดลอ้างอิงผ่านการลด KL-Divergence กับการกระจายโทเค็นของโมเดลอ้างอิง ความสำเร็จจะถูกป้อนให้กับแบบจำลองรางวัลเพื่อให้ได้คะแนนรางวัล คะแนนเทอม KL และรางวัลจะได้รับการสรุปและถือเป็นรางวัลสำหรับอัลกอริทึม PPO
conda create -n easy-rlhf python=3.8
git clone https://github.com/DaehanKim/EasyRLHF.git
cd EasyRLHF
pip install .
rm_train CMD cd data
find . -name '*.gz' -print0 | xargs -0 gzip -d
rm_train --devices "0,1,2,3"
--output_dir "outputs/my-model"
--train_data data/helpful-base/train.jsonl,data/helpful-online/train.jsonl,data/helpful-rejection-sampled/train.jsonl
--valid_data data/helpful-base/test.jsonl,data/helpful-online/test.jsonl,data/helpful-rejection-sampled/test.jsonl
scripts/rm_train.sh สำหรับการตั้งค่าที่กำหนดเองเพิ่มเติมconfigs/ds_config.yaml ซึ่งคุณสามารถตั้งค่าการตั้งค่าแบบกระจายที่คุณต้องการ ค่าเริ่มต้นถูกตั้งค่าเป็น zero-2 parallelismTBD
TBD
TBD
โครงการนี้เพียงเชื่อมโยงห้องสมุดและชุดข้อมูลจากแหล่งต่าง ๆ ดังนั้นอยู่ภายใต้เงื่อนไขใบอนุญาตของแหล่งข้อมูลที่สอดคล้องกัน สคริปต์ที่มีผลผูกพันเองคือ MIT ที่ได้รับใบอนุญาต


