EasyRLHF
1.0.0
Easyrlhf vise à fournir une interface facile et minimale pour former des modèles de langage aligné, en utilisant des solutions et des ensembles de données standard (c'est-à-dire un entraîneur HF, des ensembles de données HF, Deeppeed, TRL).
Les sections suivantes couvriront des concepts approximatifs de méthodes d'alignement (RLHF, RRHF, DPO, IPO) et fourniront des exemples d'exécution.
Comme le montre le papier instructgpt, nous pouvons former un modèle de récompense et renforcer un modèle de langue pour mieux suivre les instructions humaines. Nous pouvons d'abord entraîner le modèle de récompense et SFT-LM avec un ensemble de données hh-rlhf et un ensemble de données slimorca-dedup respectivement. Ensuite, PPO-LM peut être formé avec la bibliothèque TRL.
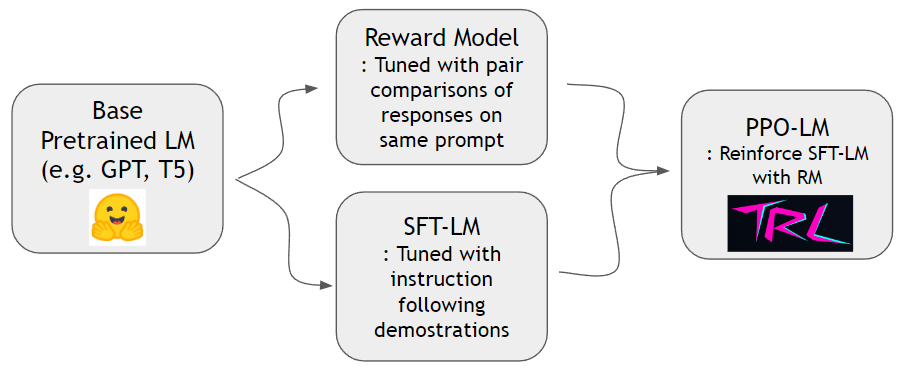
Nous avons besoin d'un ensemble de données de comparaison par paire pour former un modèle de récompense. Dans le document InstructGpt, les auteurs ont utilisé 4 ~ 9 continuations classées sur la même invite. Par exemple, A < B < C = D < E est une séquence classée et on peut échantillonner deux échantillons arbitraires (A et C). Ici, C gagne sur A sur la préférence humaine. Ainsi, nous modélisons logit of C - logit of A pour être les cotes logarithmiques de C étant une meilleure démonstration que A. logit of X peut être calculé par une tête linéaire attachée en haut d'un décodeur de transformateur. Nous utilisons un ensemble de données standard à partir de HH-RLHF par Anthropic. Cet ensemble de données est déjà plat, nous n'avons donc pas à nous soucier des schémas d'échantillonnage discutés dans InstructGpt Paper.
Nous pouvons former un modèle SFT avec une prédiction standard à l'aide de Slimorca-Dedup.
Maintenant que nous avons un modèle de récompense et un modèle SFT, nous pouvons faire l'apprentissage du renforcement avec des packages RL standard conçus pour les modèles de langage. Nous utilisons TRLTO renforcer le modèle SFT. Au stade PPO, nous conservons la copie du modèle SFT pour référence. Ce modèle de référence permet au modèle de comportement d'apprendre à augmenter les préférences humaines tout en évitant le piratage de récompense. Plus précisément, le modèle de comportement génère d'abord une invite d'achèvement donnée. Les distributions de jetons sont maintenues à proximité du modèle de référence en minimisant la divergence de KL par rapport à la distribution de jetons du modèle de référence. Un achèvement est alimenté pour récompenser le modèle pour obtenir un score de récompense. Le terme KL et le score de récompense sont additionnés et considérés comme une récompense pour l'algorithme PPO.
conda create -n easy-rlhf python=3.8
git clone https://github.com/DaehanKim/EasyRLHF.git
cd EasyRLHF
pip install .
rm_train CMD cd data
find . -name '*.gz' -print0 | xargs -0 gzip -d
rm_train --devices "0,1,2,3"
--output_dir "outputs/my-model"
--train_data data/helpful-base/train.jsonl,data/helpful-online/train.jsonl,data/helpful-rejection-sampled/train.jsonl
--valid_data data/helpful-base/test.jsonl,data/helpful-online/test.jsonl,data/helpful-rejection-sampled/test.jsonl
scripts/rm_train.sh pour des paramètres plus personnalisésconfigs/ds_config.yaml où vous pouvez définir votre paramètre distribué préféré. La valeur par défaut est définie sur un parallélisme zéro-2.TBD
TBD
TBD
Ce projet lie simplement les bibliothèques et les ensembles de données provenant de diverses sources, ce qui est en vertu des termes de licence de sources correspondantes. Le script de liaison lui-même est le MIT sous licence.


