EasyRLHF
1.0.0
Easyrlhf bertujuan untuk menyediakan antarmuka yang mudah dan minim untuk melatih model bahasa yang selaras, menggunakan solusi dan dataset di luar rak (yaitu pelatih HF, dataset HF, Deepspeed, TRL).
Bagian berikut akan mencakup konsep kasar metode penyelarasan (RLHF, RRHF, DPO, IPO) dan memberikan cara menjalankan contoh.
Seperti yang ditunjukkan dalam Paper Instruktur, kita dapat melatih model hadiah dan memperkuat model bahasa untuk mengikuti instruksi manusia dengan lebih baik. Pertama-tama kita dapat melatih model hadiah dan SFT-LM dengan dataset hh-rlhf dan dataset slimorca-dedup masing-masing. Kemudian PPO-LM dapat dilatih dengan perpustakaan TRL.
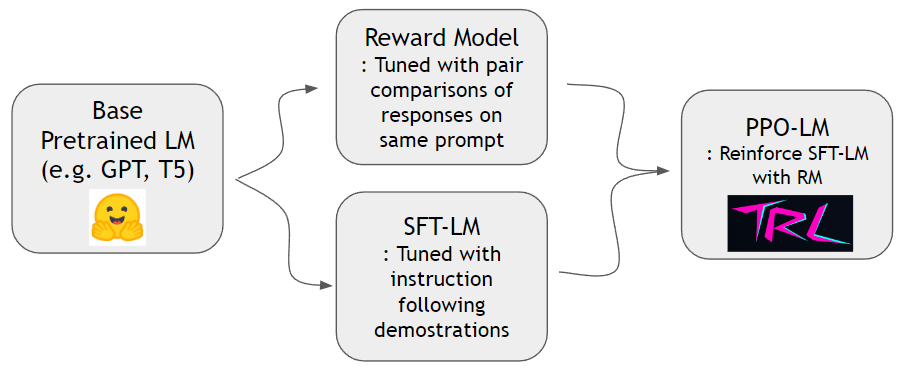
Kami membutuhkan dataset perbandingan berpasangan untuk melatih model hadiah. Dalam makalah Instruktur, penulis menggunakan 4 ~ 9 peringkat kelanjutan pada prompt yang sama. Misalnya, A < B < C = D < E adalah urutan peringkat dan satu dapat mencicipi dua sampel sewenang -wenang (A dan C). Di sini, C menang atas preferensi manusia. Dengan demikian kami memodelkan logit of C - logit of A menjadi peluang log C menjadi demonstrasi yang lebih baik daripada A. logit of X dapat dihitung oleh kepala linier yang terpasang di bagian atas dekoder transformator. Kami menggunakan dataset off-the-shelf dari HH-RLHF oleh Anthropic. Dataset ini sudah datar sehingga kita tidak perlu khawatir tentang skema pengambilan sampel yang dibahas dalam kertas Instruktur.
Kami dapat melatih model SFT dengan prediksi standar berikutnya menggunakan slimorca-dedup.
Sekarang kami memiliki model hadiah dan model SFT, kami dapat melakukan pembelajaran penguatan dengan paket RL di luar rak yang dirancang untuk model bahasa. Kami menggunakan TRLTO memperkuat model SFT. Pada tahap PPO, kami menyimpan salinan model SFT untuk referensi. Model referensi ini memungkinkan model perilaku untuk belajar meningkatkan preferensi manusia sambil menghindari peretasan hadiah. Secara khusus, Model Perilaku pertama -tama menghasilkan penyelesaian yang diberikan prompt. Distribusi token tetap dekat dengan model referensi melalui meminimalkan divergensi KL terhadap distribusi token model referensi. Penyelesaian diberi makan model hadiah untuk mendapatkan skor hadiah. Istilah KL dan skor hadiah dijumlahkan dan dianggap sebagai hadiah untuk algoritma PPO.
conda create -n easy-rlhf python=3.8
git clone https://github.com/DaehanKim/EasyRLHF.git
cd EasyRLHF
pip install .
rm_train CMD cd data
find . -name '*.gz' -print0 | xargs -0 gzip -d
rm_train --devices "0,1,2,3"
--output_dir "outputs/my-model"
--train_data data/helpful-base/train.jsonl,data/helpful-online/train.jsonl,data/helpful-rejection-sampled/train.jsonl
--valid_data data/helpful-base/test.jsonl,data/helpful-online/test.jsonl,data/helpful-rejection-sampled/test.jsonl
scripts/rm_train.sh untuk pengaturan yang lebih disesuaikanconfigs/ds_config.yaml di mana Anda dapat mengatur pengaturan terdistribusi yang Anda sukai. Default diatur ke paralelisme nol-2.Tbd
Tbd
Tbd
Proyek ini hanya mengikat pustaka dan dataset dari berbagai sumber, sehingga berada di bawah ketentuan lisensi sumber yang sesuai. Binding Script itu sendiri adalah MIT berlisensi.


