KoreanTTS
1.0.0
這是一個結合了Tacotron2模型和Vocoder模型(Griffinlim,Wavenet,Melgan)來實施韓國TTS的項目。
基於
https://github.com/tensorspeech/tensorflowtts
https://github.com/hccho2/tacotron2-korean-tts
https://carpedm20.github.io/tacotron/
《古蘭經單揚聲器》演講
演員Yoo Inna的聲音
寵物寵物教練康亨-Wook聲音
對學習進行的音頻數據沒有與版權問題共享。請檢查每個數據源。
KSS:https://www.kaggle.com/bryanpark/korean-le-speaker-spech-dataset
KBS廣播:http://program.kbs.co.kr/2fm/radio/uvolum/pc/index.html
將WAV文件轉換為numpy文件
“音頻”,“梅爾”,“線性”,“文本”,等。
data/kss/"語音文件名.npz創建
MEL光譜圖,線性光譜圖正確答案集
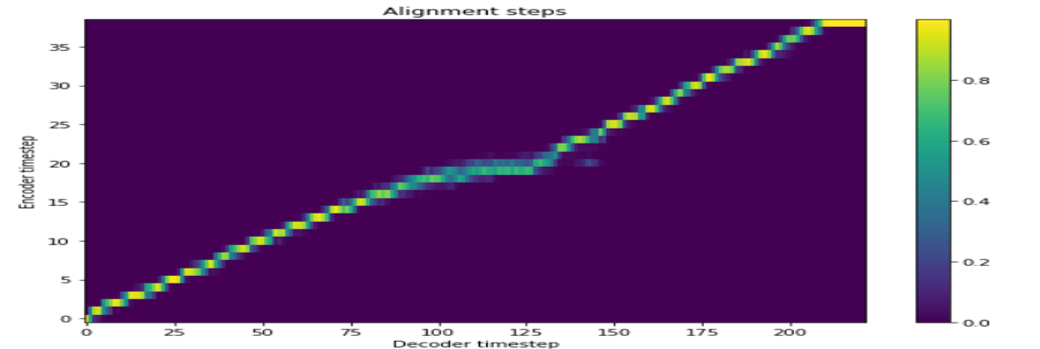
共有四個學習。
TACOTRON2 + Griffinlim +單身揚聲器
tacotron2 + griffinlim + MultiSpeaker(Deep Voice 2)
tacotron2 +梅爾根 +單揚聲器
TACOTRON2 + Melgan + MultiSpeaker(轉移學習)
TACOTRON2 + Griffinlim + MultiSpeaker(KSS + Yoo Inna)KSS數據
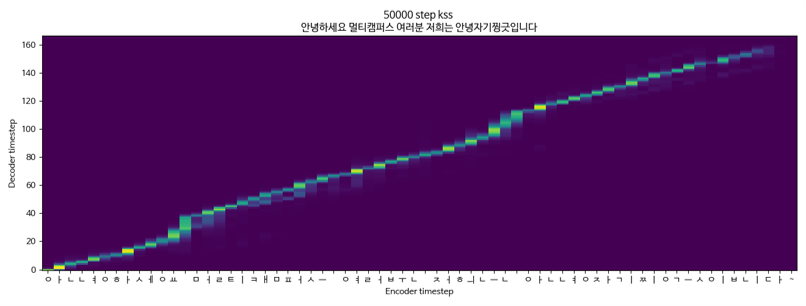
TACOTRON2 + GRIFFINLIM + MULTISPEAKER(-na中的KSS + YOO)
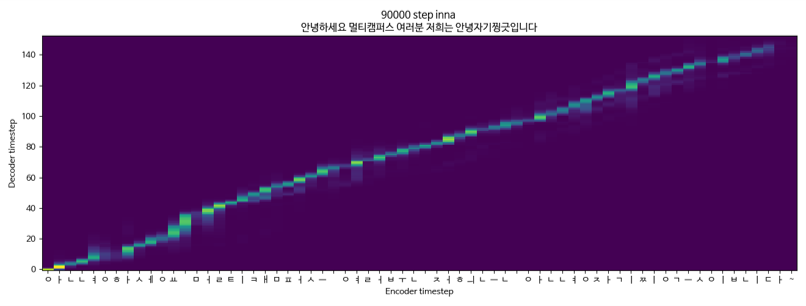
TACOTRON2 + Melgan +單身座談會(KSS)