KoreanTTS
1.0.0
Tacotron2 모델과 Vocoder모델(Griffinlim, Wavenet, MelGan)을 결합하여 한국어 TTS를 구현하는 프로젝트입니다.
Based on
https://github.com/TensorSpeech/TensorFlowTTS
https://github.com/hccho2/Tacotron2-Wavenet-Korean-TTS
https://carpedm20.github.io/tacotron/
Koran Single Speaker Speech
배우 유인나 목소리
반려동물 훈련사 강형욱 목소리
학습에 진행한 오디오 데이터는 저작권 문제로 공유하지 않습니다. 각 데이터 출처에서 확인해주세요.
KSS: https://www.kaggle.com/bryanpark/korean-single-speaker-speech-dataset
KBS 라디오: http://program.kbs.co.kr/2fm/radio/uvolum/pc/index.html
wav 파일을 numpy 파일로 변환
‘audio’, ‘mel’, ‘linear’, ‘text’ 등의 메타데이터를 묶어 저장
Data/kss/"음성파일이름.npz" 생성
Mel-spectrogram, Linear-spectrogram 정답셋을 생성
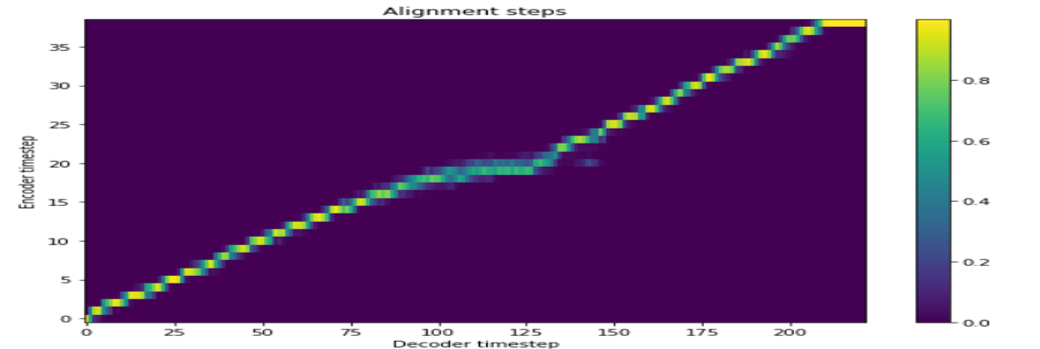
총 4가지의 학습을 진행하였습니다.
Tacotron2 + GriffinLim + Singlespeaker
Tacotron2 + GriffinLim + Multispeaker(Deep Voice 2)
Tacotron2 + Melgan + Single Speaker
Tacotron2 + Melgan + Multispeaker (Transfer learning)
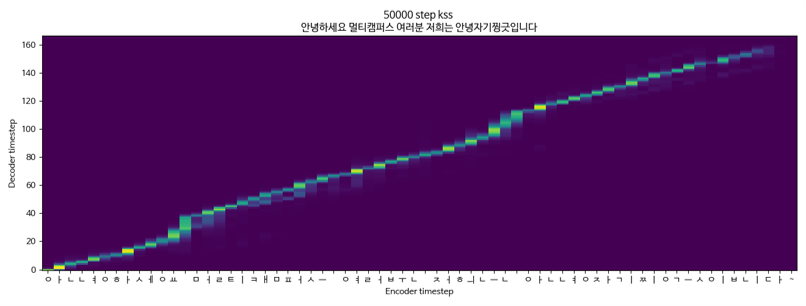
Tacotron2 + GriffinLim + Multispeaker(KSS + 유인나) 중 KSS 데이터
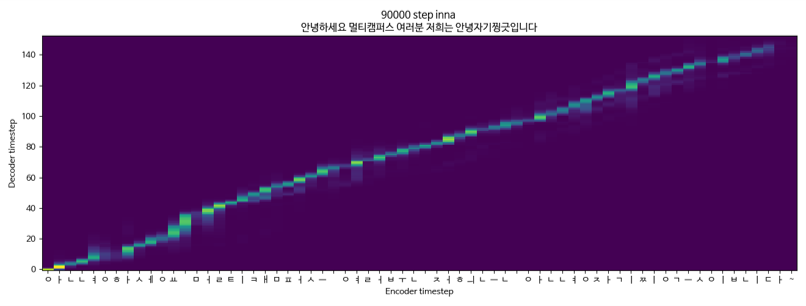
Tacotron2 + GriffinLim + Multispeaker(KSS + 유인나) 중 유인나 데이터
Tacotron2 + MelGan + Singlespeaker(KSS)