KoreanTTS
1.0.0
Es un proyecto que combina el modelo Tacotron2 y el modelo Vocoder (Griffinlim, Wavenet, Melgan) para implementar TTS coreanos.
Residencia en
https://github.com/tensorspeech/tensorflowtts
https://github.com/hccho2/tacotron2-korean-tts
https://carpedm20.github.io/tacotron/
Discurso de orador único de Corán
Voz del actor Yoo Inna
Entrenador de mascotas Kang Hyung -wook Voice
Los datos de audio realizados en el aprendizaje no se comparten con problemas de derechos de autor. Verifique cada fuente de datos.
KSS: https://www.kaggle.com/bryanpark/korean-le-peaker-sepeech-dataset
Radio KBS: http://program.kbs.co.kr/2fm/radio/uvolum/pc/index.html
Convertir el archivo wav en un archivo numpy
'Audio', 'mel', 'lineal', 'texto', etc.
Data/kss/"nombre de archivo de voz.npz creación
Espectrograma MEL, espectrograma lineal Conjunto de respuestas correctas
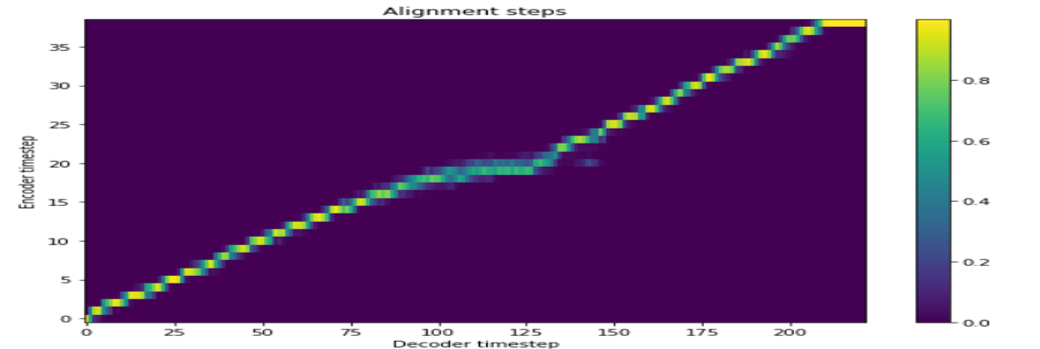
Hay un total de cuatro aprendizaje.
Tacotron2 + griffinlim + sencillo
Tacotron2 + griffinlim + multiespeaker (voz profunda 2)
Tacotron2 + Melgan + altavoz único
Tacotron2 + Melgan + Multispeaker (Transfer Learning)
Tacotron2 + griffinlim + multiespeaker (kss + yoo inna) datos KSS
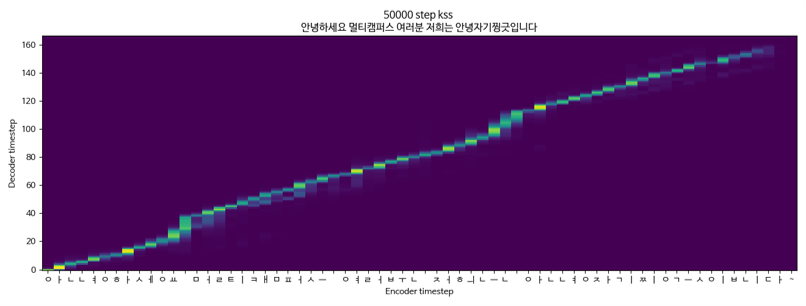
Tacotron2 + griffinlim + multiespeaker (kss + yoo en -na)
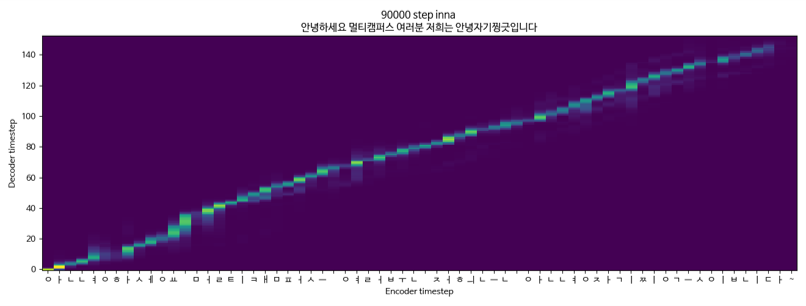
Tacotron2 + Melgan + SingleSpeaker (KSS)