KoreanTTS
1.0.0
Es ist ein Projekt, das das Tacotron2 -Modell und das Vocoder -Modell (Griffinlim, Wavenet, Melgan) kombiniert, um koreanische TTs zu implementieren.
Bezogen auf
https://github.com/tensorspeech/tensorflowtts
https://github.com/hccho2/tacotron2-korean-tts
https://carpedm20.github.io/tacotron/
Koran Single Speaker Rede
Schauspieler Yoo Innas Stimme
Haustiertrainer Kang Hyung -Wook Stimme
Audiodaten zum Lernen werden nicht mit Urheberrechtsfragen geteilt. Bitte überprüfen Sie jede Datenquelle.
KSS: https://www.kaggle.com/bryanpark/korean-lespeaker-speech-dataset
KBS Radio: http://program.kbs.co.kr/2fm/radio/uvolum/pc/index.html
Konvertieren Sie die WAV -Datei in eine Numpy -Datei
'Audio', 'Mel', 'linear', 'Text', usw.
Daten/KSS/"Sprachdateiname.npz Erstellung
Melspektogramm, linearspektrogramm richtiger Antwortsatz
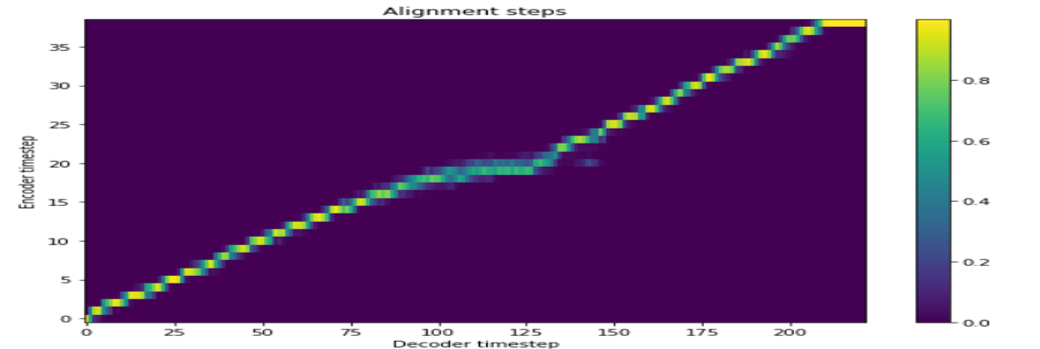
Es gibt insgesamt vier Lernen.
Tacotron2 + Griffinlim + Singlespeaker
Tacotron2 + Griffinlim + Multispeaker (Deep Voice 2)
Tacotron2 + Melgan + Einzellautsprecher
Tacotron2 + Melgan + Multispeaker (Transfer Learning)
Tacotron2 + Griffinlim + Multispeaker (KSS + Yoo Inna) KSS -Daten
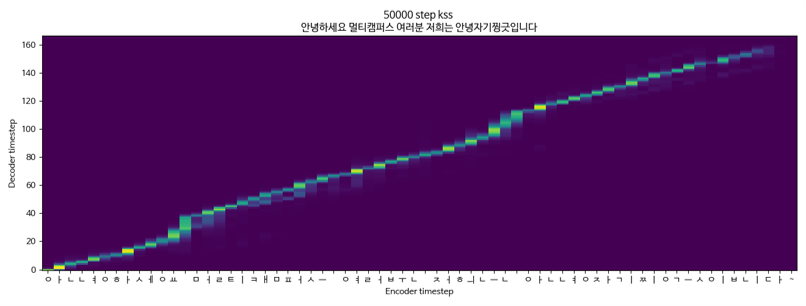
Tacotron2 + Griffinlim + Multispeaker (KSS + Yoo in -na)
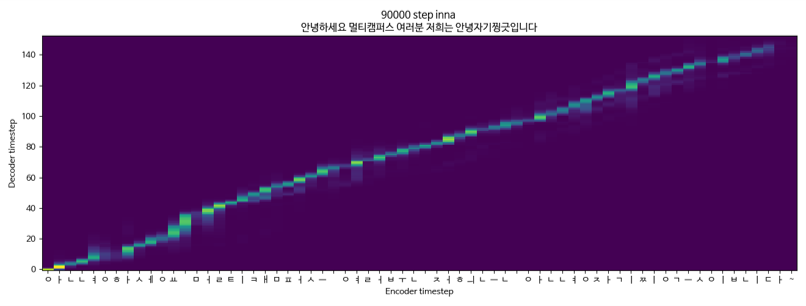
Tacotron2 + Melgan + Singlespeaker (KSS)