KoreanTTS
1.0.0
Il s'agit d'un projet qui combine le modèle Tacotron2 et le modèle Vocoder (Griffinlim, Wavenet, Melgan) pour mettre en œuvre des TT coréens.
Basé sur
https://github.com/tensorspeech/tensorflowtts
https://github.com/hccho2/tacotron2-korean-tts
https://carpedm20.github.io/tacotron/
Discours de conférencier unique Koran
La voix de l'acteur Yoo Inna
Pet Pet Trainer Kang Hyung - VOIRE
Les données audio menées sur l'apprentissage ne sont pas partagées avec les problèmes de droit d'auteur. Veuillez vérifier chaque source de données.
KSS: https://www.kaggle.com/bryanpark/korean-le-speaker-disech-dataset
KBS Radio: http://program.kbs.co.kr/2fm/radio/uvolum/pc/index.html
Convertir le fichier WAV en un fichier Numpy
«Audio», «Mel», «linéaire», «texte», etc.
Data / kSS / "nom de fichier vocal.NPZ Création
Spectrogramme de Mel, ensemble de réponses correct-spectrogramme linéaire
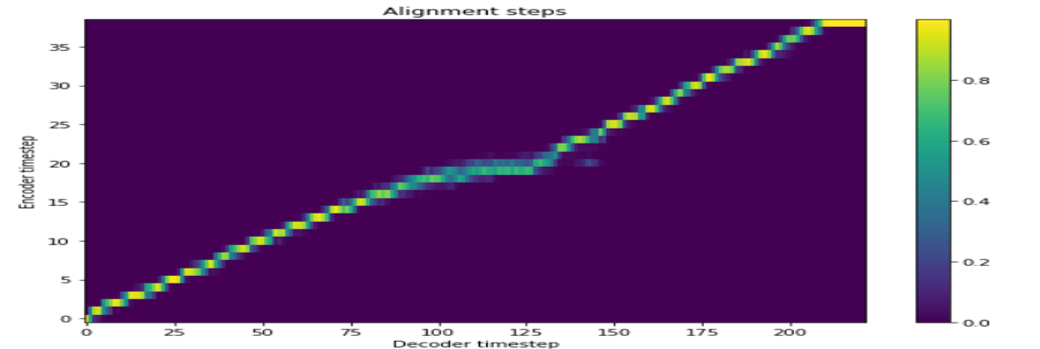
Il y a un total de quatre apprentissage.
Tacotron2 + Griffinlim + singleSpeaker
Tacotron2 + Griffinlim + Multippeaker (voix profonde 2)
Tacotron2 + Melgan + Président unique
Tacotron2 + Melgan + Multippeaker (apprentissage transfert)
Tacotron2 + Griffinlim + Multippeaker (KSS + YOO INNA) KSS DATA
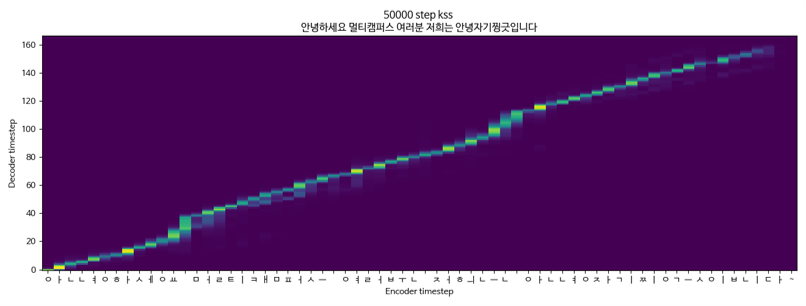
Tacotron2 + Griffinlim + Multippeaker (KSS + Yoo in -na)
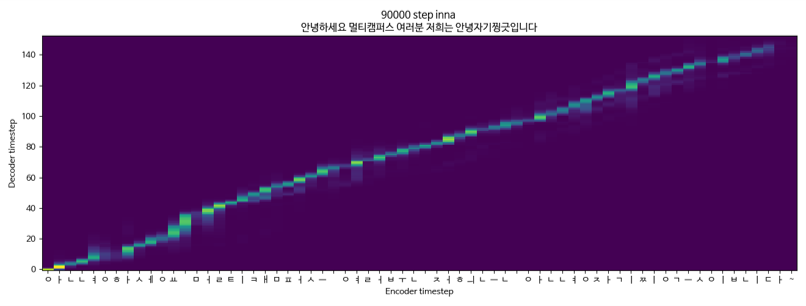
Tacotron2 + Melgan + singleSpeaker (KSS)