KoreanTTS
1.0.0
มันเป็นโครงการที่รวมโมเดล Tacotron2 และโมเดล Vocoder (Griffinlim, Wavenet, Melgan) เพื่อใช้ TTS เกาหลี
ขึ้นอยู่กับ
https://github.com/tensorspeech/tensorflowtts
https://github.com/hccho2/tacotron2-korean-tts
https://carpedm20.github.io/tacotron/
คำปราศรัยของวิทยากรอัลกุรอาน
เสียงของนักแสดงยูอินา
ผู้ฝึกสอนสัตว์เลี้ยงสัตว์เลี้ยงคังฮยอง -เสียงวู๊ด
ข้อมูลเสียงที่ดำเนินการเกี่ยวกับการเรียนรู้ไม่ได้ถูกแบ่งปันกับปัญหาลิขสิทธิ์ โปรดตรวจสอบแหล่งข้อมูลแต่ละแหล่ง
KSS: https://www.kaggle.com/bryanpark/korean-le-speaker-speech-dataset
วิทยุ KBS: http://program.kbs.co.kr/2fm/radio/uvolum/pc/index.html
แปลงไฟล์ wav เป็นไฟล์ numpy
'เสียง', 'mel', 'linear', 'text' ฯลฯ
Data/KSS/" ชื่อไฟล์เสียงการสร้าง NPZ
mel-spectrogram, ชุดคำตอบที่ถูกต้อง
มีการเรียนรู้ทั้งหมดสี่ครั้ง
tacotron2 + griffinlim + singlespeaker
Tacotron2 + Griffinlim + Multispeaker (Deep Voice 2)
Tacotron2 + Melgan + ลำโพงเดี่ยว
Tacotron2 + Melgan + Multispeaker (การเรียนรู้การถ่ายโอน)
tacotron2 + griffinlim + multispeaker (kss + yoo inna) ข้อมูล KSS
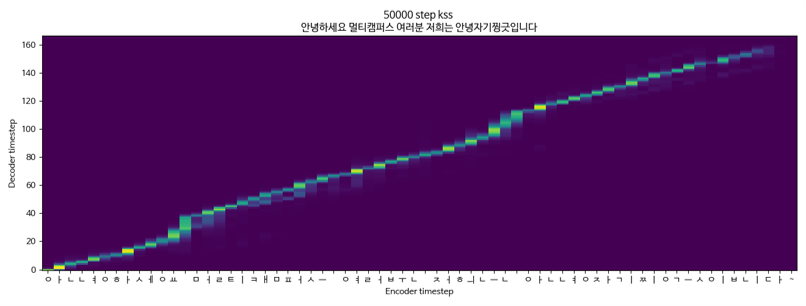
Tacotron2 + Griffinlim + Multispeaker (KSS + YOO ใน -NA)
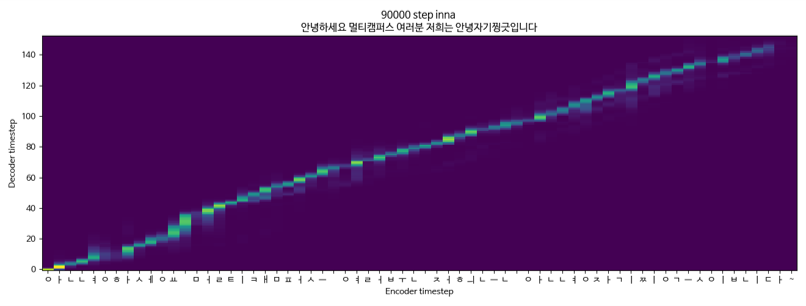
Tacotron2 + Melgan + Singlespeaker (KSS)