TextBox
TextBox 2.0 Release

“李太白少時,夢所用之筆頭上生花後天才贍逸,名聞天下。” - - 王仁裕《開元天寶遺事·夢筆頭生花》
TextBox 2.0:具有預訓練語言模型的文本生成庫
TextBox 2.0是基於Python和Pytorch的最新文本生成庫,致力於構建統一和標準化的管道,用於將預訓練的語言模型應用於文本生成:
與以前的文本框相比,此擴展名主要集中在構建一個統一,靈活和標準化的框架上,以更好地支持基於PLM的文本生成模型。 TextBox 2.0有三個優點:
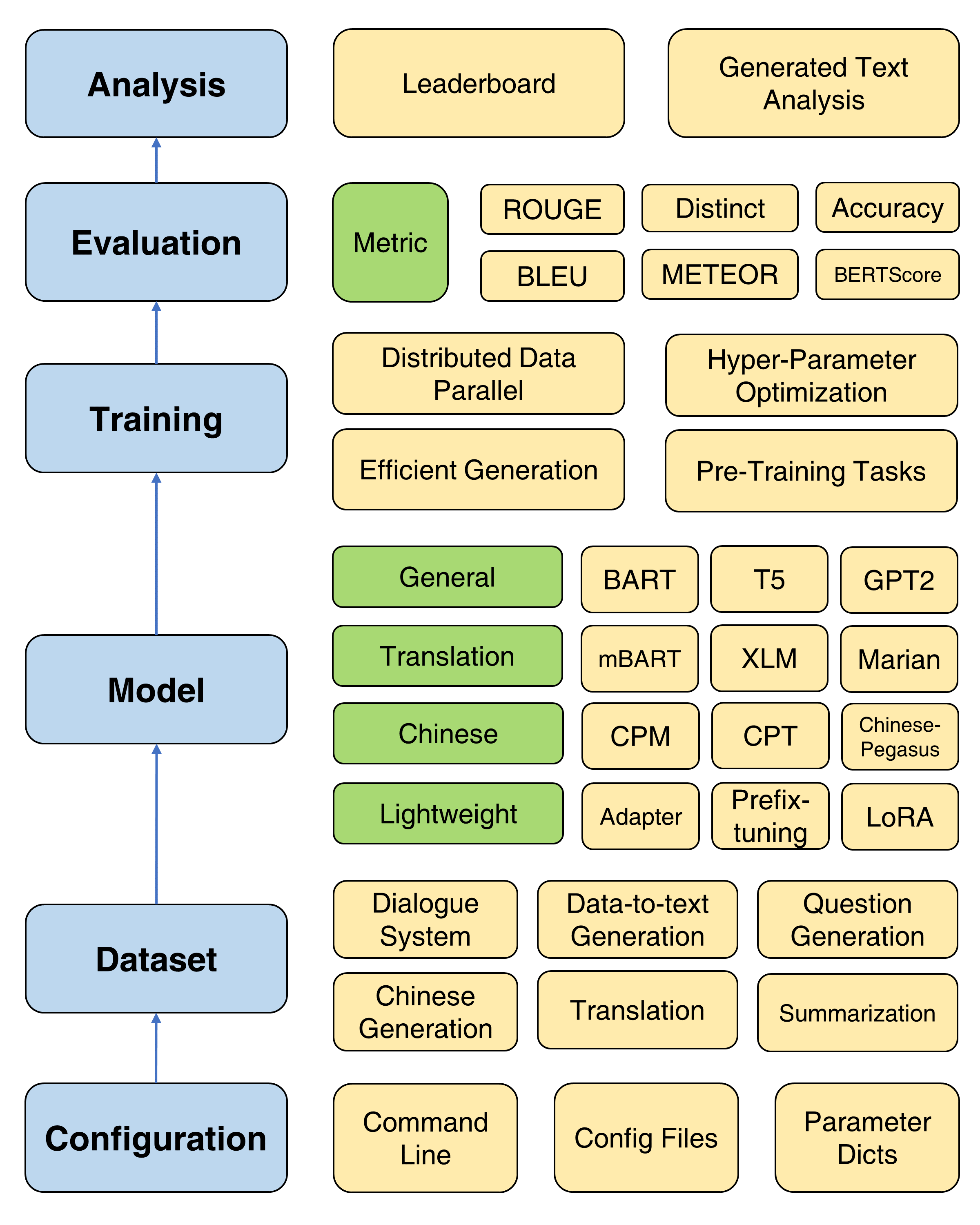
TextBox 2.0的整體框架
考慮到將安裝了變壓器的修改版本,建議創建一個新的Conda環境:
conda create -n TextBox python=3.8然後,您可以克隆我們的存儲庫,並使用一鍵式安裝。
git clone https://github.com/RUCAIBox/TextBox.git && cd TextBox
bash install.sh如果您面對files2rouge ROUGE-1.5.5.pl - XML::Parser dependency error時的問題,則可以參考此問題。
這是一個在端到端管道中運行TextBox 2.0的腳本模板:
python run_textbox.py --model= < model-name > --dataset= < dataset-name > --model_path= < hf-or-local-path >替代--model=<xxx> , --dataset=<xxx>和--model_path=<xxx>您可以選擇。
model和model_path的選擇可以在模型中找到。我們提供該頁面中每個模型的詳細說明。
dataset的選擇可以在數據集中找到。您應該在https://huggingface.co/rucaibox上下載數據集,並將下載的數據集放在dataset集文件夾下,就像Samsum一樣。如果您想使用自己的數據集,請參考此處。
下面的腳本將在samsum數據集上運行Facebook BART-base模型:
python run_textbox.py --model=BART --dataset=samsum --model_path=facebook/bart-base對於基本培訓,我們提供了一個詳細的教程(此處),用於設置常用參數,例如優化器,調度程序,驗證頻率,早期停止等。
TextBox 2.0提供了四個預訓練的目標,以幫助用戶從頭開始預訓練模型,包括語言建模,蒙版序列到序列建模,自動編碼和蒙版跨度預測。有關詳細的教程,請參見預培訓文檔。
提供了四種有用的訓練方法來改善PLM的優化:分佈式數據平行,有效的解碼,超參數優化和重複實驗。此處提供了詳細說明。
為了支持PLM在文本生成上的快速進步,TextBox 2.0包含了47個模型/模塊,涵蓋了一般,翻譯,中文,對話,可控制,蒸餾,提示和輕量級模型(模塊)的類別。有關每個模型,預訓練的模型參數和生成參數的詳細用法指令的信息,請參見模型文檔。
現在,我們支持13個一代任務(例如,翻譯和故事生成)及其相應的83個數據集。我們還為每個數據集提供描述,基本統計信息,培訓/驗證/測試樣本和排行榜。在此處查看更多詳細信息。
TextBox 2.0支持17個4個類別的自動指標和幾種可視化工具,以探索和分析各個維度的生成文本。有關評估詳細信息,請參見評估文檔。
| 發行 | 日期 | 特徵 |
|---|---|---|
| v2.0.1 | 24/12/2022 | TextBox 2.0 |
| v2.0.0 | 20/08/2022 | TextBox 2.0 Beta |
| v0.2.1 | 15/04/2021 | 文本框 |
| V0.1.5 | 01/11/2021 | 基本文本框 |
如果您遇到錯誤或提出問題,請告訴我們是否有任何建議。
我們歡迎從錯誤修復到新功能和擴展的所有貢獻。
我們希望在問題跟踪器中討論所有貢獻並進行PRS。
我們感謝 @lucastsui0725構成了HRED模型和幾個評估指標。
我們感謝@wxdai在變形金剛API中貢獻了Pointernet和20多種語言模型。
TextBox由AI盒開發和維護。
TextBox使用MIT許可證。
如果您發現Textbox 2.0對您的研究或開發有用,請引用以下論文:
@inproceedings{tang-etal-2022-textbox,
title = "{T}ext{B}ox 2.0: A Text Generation Library with Pre-trained Language Models",
author = "Tang, Tianyi and Li, Junyi and Chen, Zhipeng and Hu, Yiwen and Yu, Zhuohao and Dai, Wenxun and Zhao, Wayne Xin and Nie, Jian-yun and Wen, Ji-rong",
booktitle = "Proceedings of the The 2022 Conference on Empirical Methods in Natural Language Processing: System Demonstrations",
month = dec,
year = "2022",
address = "Abu Dhabi, UAE",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2022.emnlp-demos.42",
pages = "435--444",
}
@inproceedings{textbox,
title = "{T}ext{B}ox: A Unified, Modularized, and Extensible Framework for Text Generation",
author = "Li, Junyi and Tang, Tianyi and He, Gaole and Jiang, Jinhao and Hu, Xiaoxuan and Xie, Puzhao and Chen, Zhipeng and Yu, Zhuohao and Zhao, Wayne Xin and Wen, Ji-Rong",
booktitle = "Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing: System Demonstrations",
month = aug,
year = "2021",
address = "Online",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2021.acl-demo.4",
doi = "10.18653/v1/2021.acl-demo.4",
pages = "30--39",
}


