TextBox
TextBox 2.0 Release

“ 李太白少时, 梦所用之笔头上生花后天才赡逸, 名闻天下。名闻天下。” 王仁裕《开元天宝遗事 王仁裕《开元天宝遗事 · 梦笔头生花》
Textbox 2.0: ไลบรารีการสร้างข้อความที่มีรูปแบบภาษาที่ผ่านการฝึกอบรมมาก่อน
Textbox 2.0 เป็นไลบรารีการสร้างข้อความที่ทันสมัยโดยใช้ Python และ Pytorch โดยมุ่งเน้นที่การสร้างท่อส่งข้อมูลแบบครบวงจรและเป็นมาตรฐานสำหรับการใช้แบบจำลองภาษาที่ผ่านการฝึกอบรมมาก่อนกับการสร้างข้อความ:
เมื่อเทียบกับกล่องข้อความรุ่นก่อนหน้าส่วนขยายนี้ส่วนใหญ่มุ่งเน้นไปที่การสร้างกรอบการทำงานแบบครบวงจรยืดหยุ่นและเป็นมาตรฐานเพื่อรองรับรุ่นการสร้างข้อความที่ใช้ PLM ที่ดีกว่า มีข้อดีสามประการของกล่องข้อความ 2.0:
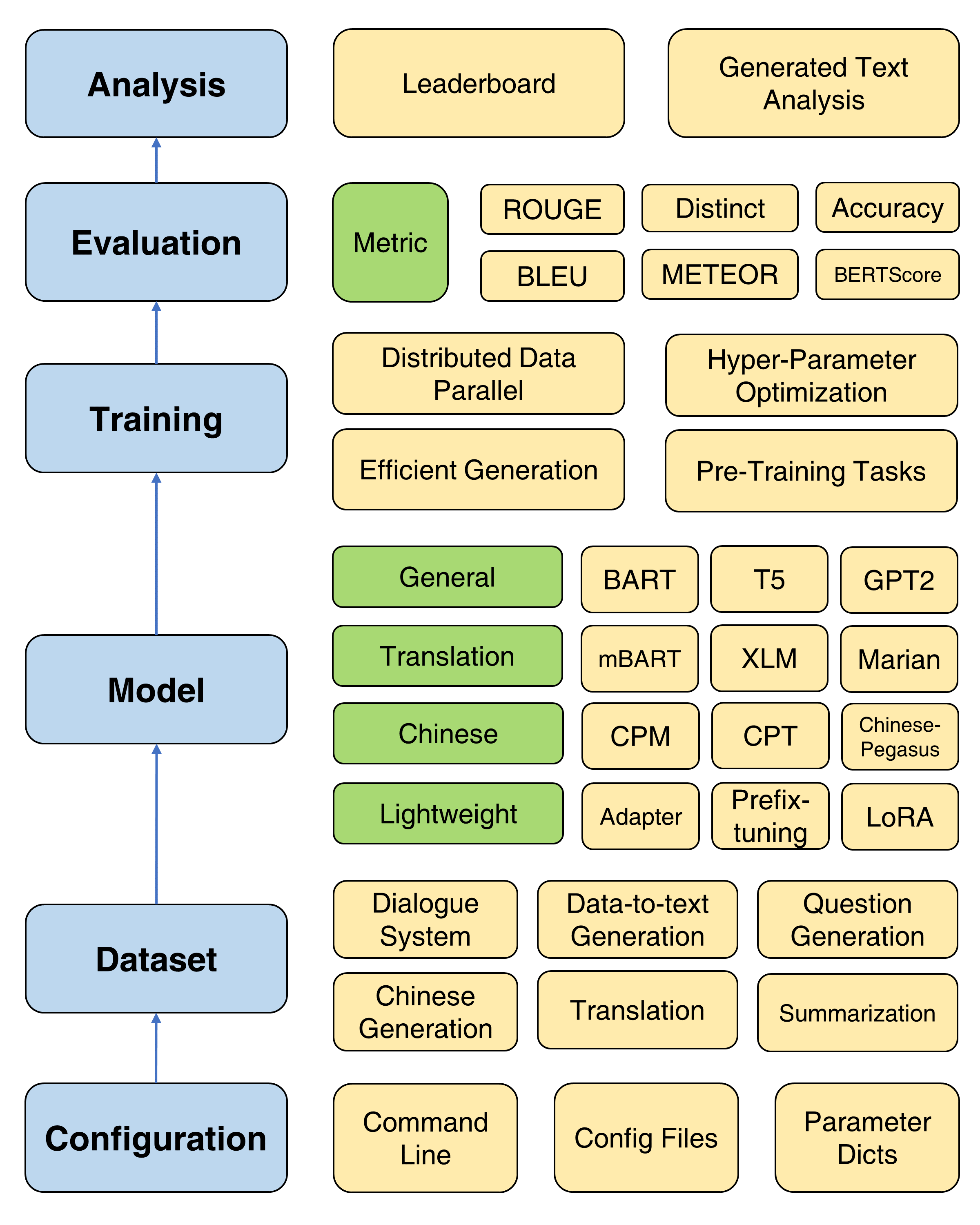
เฟรมเวิร์กโดยรวมของกล่องข้อความ 2.0
เมื่อพิจารณาว่าจะมีการติดตั้งหม้อแปลงเวอร์ชันที่แก้ไขแล้วขอแนะนำให้สร้างสภาพแวดล้อม Conda ใหม่:
conda create -n TextBox python=3.8จากนั้นคุณสามารถโคลนพื้นที่เก็บข้อมูลของเราและติดตั้งด้วยคลิกเดียว
git clone https://github.com/RUCAIBox/TextBox.git && cd TextBox
bash install.sh หากคุณประสบปัญหา ROUGE-1.5.5.pl - XML::Parser dependency error เมื่อติดตั้ง files2rouge คุณสามารถอ้างถึงปัญหานี้ได้
นี่คือเทมเพลตสคริปต์ที่จะเรียกใช้ Textbox 2.0 ในไปป์ไลน์แบบ end-to-end:
python run_textbox.py --model= < model-name > --dataset= < dataset-name > --model_path= < hf-or-local-path > แทน --model=<xxx> , --dataset=<xxx> และ --model_path=<xxx> พร้อมตัวเลือกของคุณ
ตัวเลือกของ model และ model_path สามารถพบได้ในโมเดล เราให้คำแนะนำโดยละเอียดของแต่ละรุ่นในหน้านั้น
ตัวเลือกของ dataset สามารถพบได้ในชุดข้อมูล คุณควรดาวน์โหลดชุดข้อมูลที่ https://huggingface.co/rucaibox และวางชุดข้อมูลที่ดาวน์โหลดไว้ใต้โฟลเดอร์ dataset เช่น Samsum หากคุณต้องการใช้ชุดข้อมูลของคุณเองโปรดดูที่นี่
สคริปต์ด้านล่างจะเรียกใช้โมเดล Facebook BART-base บนชุดข้อมูล samsum :
python run_textbox.py --model=BART --dataset=samsum --model_path=facebook/bart-baseสำหรับการฝึกอบรมขั้นพื้นฐานเรามีการสอนอย่างละเอียด (ที่นี่) สำหรับการตั้งค่าพารามิเตอร์ที่ใช้กันทั่วไปเช่นเครื่องมือเพิ่มประสิทธิภาพ, ตารางเวลา, ความถี่การตรวจสอบความถูกต้อง, การหยุดเร็วและอื่น ๆ
Textbox 2.0 จัดเตรียมวัตถุประสงค์ล่วงหน้าสี่ประการเพื่อช่วยให้ผู้ใช้ฝึกอบรมรุ่นก่อนตั้งแต่เริ่มต้นรวมถึงการสร้างแบบจำลองภาษาการสร้างแบบจำลองลำดับต่อลำดับการจำลองการเข้ารหัสอัตโนมัติ denoising และการทำนายการสวมหน้ากาก ดูเอกสารการฝึกอบรมล่วงหน้าสำหรับการสอนโดยละเอียด
มีวิธีการฝึกอบรมที่มีประโยชน์สี่วิธีสำหรับการปรับปรุงการเพิ่มประสิทธิภาพของ PLM: ข้อมูลแบบกระจายขนานการถอดรหัสที่มีประสิทธิภาพการเพิ่มประสิทธิภาพพารามิเตอร์ไฮเปอร์และการทดลองซ้ำ ๆ คำแนะนำโดยละเอียดมีให้ที่นี่
เพื่อรองรับความคืบหน้าอย่างรวดเร็วของ PLMS ในการสร้างข้อความกล่องข้อความ 2.0 รวม 47 รุ่น/โมดูลครอบคลุมหมวดหมู่ของทั่วไปการแปลภาษาจีนบทสนทนาการควบคุมการกลั่นการกระตุ้นและน้ำหนักเบา (โมดูล) ดูโมเดลเอกสารสำหรับข้อมูลเกี่ยวกับคำแนะนำการใช้งานโดยละเอียดของแต่ละรุ่นพารามิเตอร์แบบจำลองที่ผ่านการฝึกอบรมมาก่อนและพารามิเตอร์การสร้าง
ตอนนี้เราสนับสนุนงาน 13 รุ่น (เช่นการแปลและการสร้างเรื่องราว) และชุดข้อมูล 83 ชุดที่สอดคล้องกัน นอกจากนี้เรายังให้คำอธิบายสถิติพื้นฐานตัวอย่างการฝึกอบรม/การตรวจสอบ/ทดสอบและกระดานผู้นำสำหรับแต่ละชุดข้อมูล ดูรายละเอียดเพิ่มเติมที่นี่
Textbox 2.0 รองรับ 17 ตัวชี้วัดอัตโนมัติ 4 หมวดหมู่และเครื่องมือสร้างภาพข้อมูลหลายอย่างเพื่อสำรวจและวิเคราะห์ข้อความที่สร้างขึ้นในมิติต่าง ๆ สำหรับรายละเอียดการประเมินดูเอกสารการประเมินผล
| ปล่อย | วันที่ | คุณสมบัติ |
|---|---|---|
| v2.0.1 | 24/12/2022 | กล่องข้อความ 2.0 |
| v2.0.0 | 20/08/2022 | กล่องข้อความ 2.0 เบต้า |
| v0.2.1 | 15/04/2021 | กล่องข้อความ |
| v0.1.5 | 01/11/2021 | กล่องข้อความพื้นฐาน |
โปรดแจ้งให้เราทราบหากคุณพบข้อผิดพลาดหรือมีคำแนะนำใด ๆ โดยการยื่นปัญหา
เรายินดีต้อนรับการมีส่วนร่วมทั้งหมดตั้งแต่การแก้ไขข้อผิดพลาดไปจนถึงคุณสมบัติใหม่และส่วนขยาย
เราคาดหวังว่าการมีส่วนร่วมทั้งหมดที่กล่าวถึงในการติดตามปัญหาและผ่าน PRS
เราขอขอบคุณ @lucastsui0725 สำหรับการสนับสนุนรูปแบบ Hred และตัวชี้วัดการประเมินผลหลายอย่าง
เราขอขอบคุณ @wxdai ที่ให้การสนับสนุน Pointernet และโมเดลภาษามากกว่า 20 แบบใน Transformers API
กล่องข้อความได้รับการพัฒนาและบำรุงรักษาโดย AI Box
กล่องข้อความใช้ใบอนุญาต MIT
หากคุณพบว่า Textbox 2.0 มีประโยชน์สำหรับการวิจัยหรือพัฒนาของคุณโปรดอ้างอิงเอกสารต่อไปนี้:
@inproceedings{tang-etal-2022-textbox,
title = "{T}ext{B}ox 2.0: A Text Generation Library with Pre-trained Language Models",
author = "Tang, Tianyi and Li, Junyi and Chen, Zhipeng and Hu, Yiwen and Yu, Zhuohao and Dai, Wenxun and Zhao, Wayne Xin and Nie, Jian-yun and Wen, Ji-rong",
booktitle = "Proceedings of the The 2022 Conference on Empirical Methods in Natural Language Processing: System Demonstrations",
month = dec,
year = "2022",
address = "Abu Dhabi, UAE",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2022.emnlp-demos.42",
pages = "435--444",
}
@inproceedings{textbox,
title = "{T}ext{B}ox: A Unified, Modularized, and Extensible Framework for Text Generation",
author = "Li, Junyi and Tang, Tianyi and He, Gaole and Jiang, Jinhao and Hu, Xiaoxuan and Xie, Puzhao and Chen, Zhipeng and Yu, Zhuohao and Zhao, Wayne Xin and Wen, Ji-Rong",
booktitle = "Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing: System Demonstrations",
month = aug,
year = "2021",
address = "Online",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2021.acl-demo.4",
doi = "10.18653/v1/2021.acl-demo.4",
pages = "30--39",
}


