TextBox
TextBox 2.0 Release

"李太白少时 , 梦所用之笔头上生花后天才赡逸 名闻天下。 名闻天下。" —— 王仁裕《开元天宝遗事 · 梦笔头生花》
Textbox 2.0: una biblioteca de generación de texto con modelos de lenguaje previamente capacitados
Textbox 2.0 es una biblioteca de generación de texto actualizada basada en Python y Pytorch, centrándose en construir una tubería unificada y estandarizada para aplicar modelos de lenguaje previamente capacitados a la generación de texto:
En comparación con la versión anterior de TextBox, esta extensión se centra principalmente en construir un marco unificado, flexible y estandarizado para que los modelos de generación de texto basados en PLM sean mejor soportados. Hay tres ventajas de TextBox 2.0:
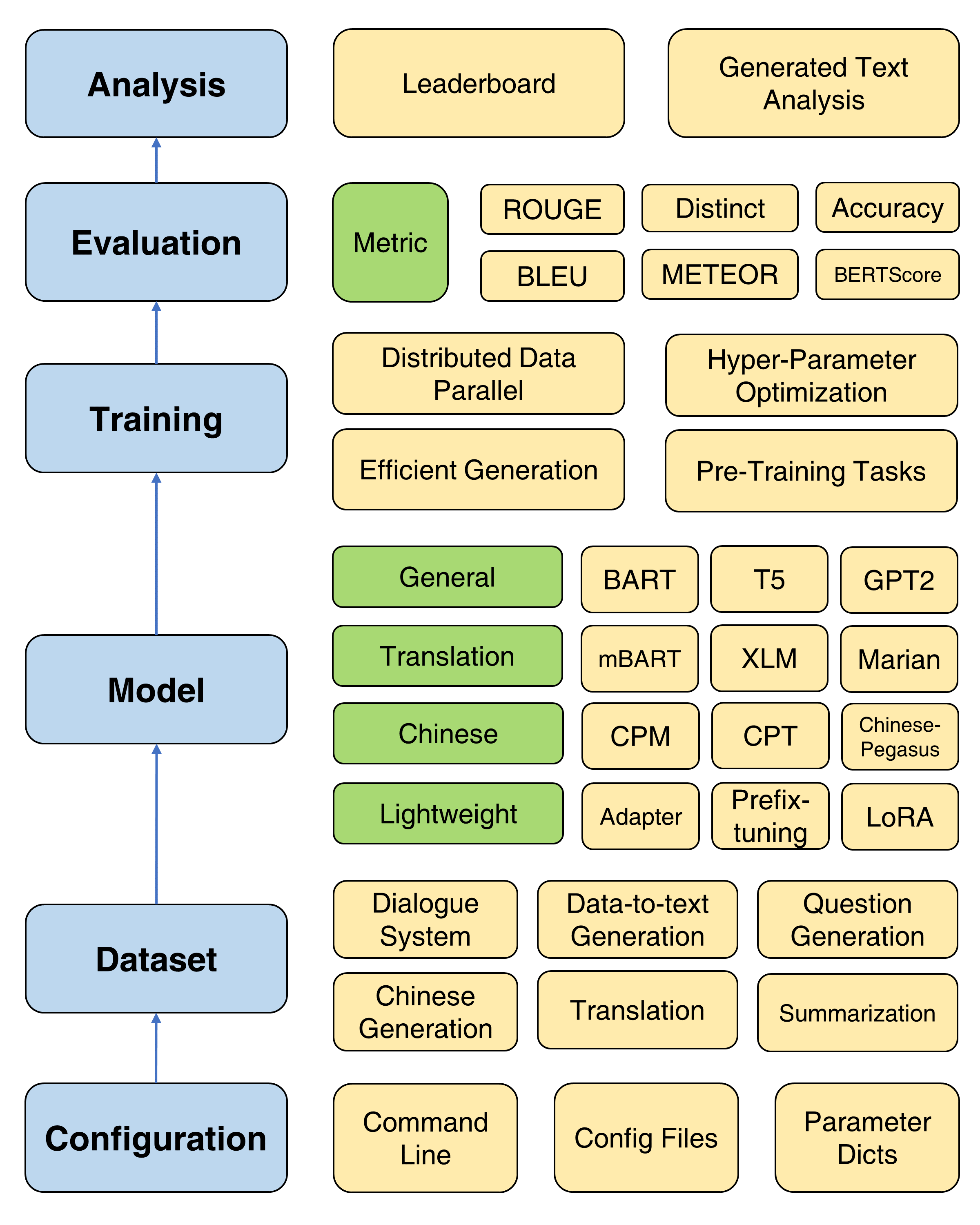
El marco general de Textbox 2.0
Teniendo en cuenta que se instalará una versión modificada de Transformers, se recomienda crear un nuevo entorno de conda:
conda create -n TextBox python=3.8Luego, puede clonar nuestro repositorio e instalarlo con un solo clic.
git clone https://github.com/RUCAIBox/TextBox.git && cd TextBox
bash install.sh Si se enfrenta a un problema ROUGE-1.5.5.pl - XML::Parser dependency error Al instalar files2rouge , puede consultar este problema.
Esta es una plantilla de script para ejecutar Textbox 2.0 en una tubería de extremo a extremo:
python run_textbox.py --model= < model-name > --dataset= < dataset-name > --model_path= < hf-or-local-path > Sustituye --model=<xxx> , --dataset=<xxx> y --model_path=<xxx> con sus opciones.
Las opciones de model y model_path se pueden encontrar en el modelo. Proporcionamos la instrucción detallada de cada modelo en esa página.
Las opciones del dataset se pueden encontrar en el conjunto de datos. Debe descargar el conjunto de datos en https://huggingface.co/rucaibox y colocar el conjunto de datos descargado en la carpeta dataset al igual que Samsum. Si desea usar su propio conjunto de datos, consulte aquí.
El script a continuación ejecutará el modelo BART-base de Facebook en el conjunto de datos samsum :
python run_textbox.py --model=BART --dataset=samsum --model_path=facebook/bart-basePara la capacitación básica, proporcionamos un tutorial detallado (aquí) para establecer parámetros de uso común como optimizador, programador, frecuencia de validación, parada temprana, etc.
Textbox 2.0 proporciona cuatro objetivos de pre-entrenamiento para ayudar a los usuarios a pre-entrenar un modelo desde cero, incluido el modelado de idiomas, el modelado de secuencia a secuencia enmascarado, la codificación automática y la predicción enmascarada del tramo. Vea el documento de pre-entrenamiento para un tutorial detallado.
Se proporcionan cuatro métodos de entrenamiento útiles para mejorar la optimización de los PLM: datos distribuidos paralelos, decodificación eficiente, optimización de hiperparaméter y experimentos repetidos. Se proporcionan instrucciones detalladas aquí.
Para respaldar el rápido progreso de las PLM en la generación de texto, Textbox 2.0 incorpora 47 modelos/módulos, que cubre las categorías de modelos generales, de traducción, chino, diálogo, controlable, destilado, de solicitud y liviano (módulos). Consulte el modelo Doc para obtener información sobre instrucciones de uso detalladas de cada modelo, parámetros del modelo previamente capacitado y parámetros de generación.
Ahora apoyamos 13 tareas de generación (por ejemplo, traducción y generación de historias) y sus 83 conjuntos de datos correspondientes. También proporcionamos la descripción, las estadísticas básicas, las muestras de capacitación/validación/prueba y la clasificación para cada conjunto de datos. Vea más detalles aquí.
Textbox 2.0 admite 17 métricas automáticas de 4 categorías y varias herramientas de visualización para explorar y analizar los textos generados en varias dimensiones. Para detalles de evaluación, consulte el Doc de Evaluación.
| Lanzamientos | Fecha | Características |
|---|---|---|
| v2.0.1 | 24/12/2022 | Textbox 2.0 |
| v2.0.0 | 20/08/2022 | Textbox 2.0 beta |
| V0.2.1 | 15/04/2021 | Cuadro de texto |
| V0.1.5 | 11/01/2021 | Cuadro de texto básico |
Háganos saber si encuentra un error o tiene alguna sugerencia presentando un problema.
Agradecemos todas las contribuciones de correcciones de errores a nuevas características y extensiones.
Esperamos todas las contribuciones discutidas en el rastreador de problemas y pasando por relaciones públicas.
Agradecemos a @Lucastsui0725 por contribuir con el modelo HRED y varias métricas de evaluación.
Agradecemos a @WXDAI por contribuir con Pointernet y más de 20 modelos de idiomas en la API Transformers.
TextBox es desarrollado y mantenido por AI Box.
TextBox usa la licencia MIT.
Si encuentra que TextBox 2.0 es útil para su investigación o desarrollo, cite los siguientes documentos:
@inproceedings{tang-etal-2022-textbox,
title = "{T}ext{B}ox 2.0: A Text Generation Library with Pre-trained Language Models",
author = "Tang, Tianyi and Li, Junyi and Chen, Zhipeng and Hu, Yiwen and Yu, Zhuohao and Dai, Wenxun and Zhao, Wayne Xin and Nie, Jian-yun and Wen, Ji-rong",
booktitle = "Proceedings of the The 2022 Conference on Empirical Methods in Natural Language Processing: System Demonstrations",
month = dec,
year = "2022",
address = "Abu Dhabi, UAE",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2022.emnlp-demos.42",
pages = "435--444",
}
@inproceedings{textbox,
title = "{T}ext{B}ox: A Unified, Modularized, and Extensible Framework for Text Generation",
author = "Li, Junyi and Tang, Tianyi and He, Gaole and Jiang, Jinhao and Hu, Xiaoxuan and Xie, Puzhao and Chen, Zhipeng and Yu, Zhuohao and Zhao, Wayne Xin and Wen, Ji-Rong",
booktitle = "Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing: System Demonstrations",
month = aug,
year = "2021",
address = "Online",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2021.acl-demo.4",
doi = "10.18653/v1/2021.acl-demo.4",
pages = "30--39",
}


