TextBox
TextBox 2.0 Release

"李太白少时 , 梦所用之笔头上生花后天才赡逸 , 名闻天下。" - 王仁裕《开元天宝遗事 · 梦笔头生花》
Textbox 2.0: Eine Bibliothek für Textgenerierungsbibliothek mit vorgeborenen Sprachmodellen
Textbox 2.0 ist eine aktuelle Bibliothek für Textgenerierung, die auf Python und Pytorch basiert und sich auf den Aufbau einer einheitlichen und standardisierten Pipeline für die Anwendung vorgeburerer Sprachmodelle auf die Textgenerierung konzentriert:
Im Vergleich zur vorherigen Version von Textbox konzentriert sich diese Erweiterung hauptsächlich auf den Aufbau eines einheitlichen, flexiblen und standardisierten Frameworks für besser unterstützende PLM-basierte Textgenerierungsmodelle. Es gibt drei Vorteile von Textbox 2.0:
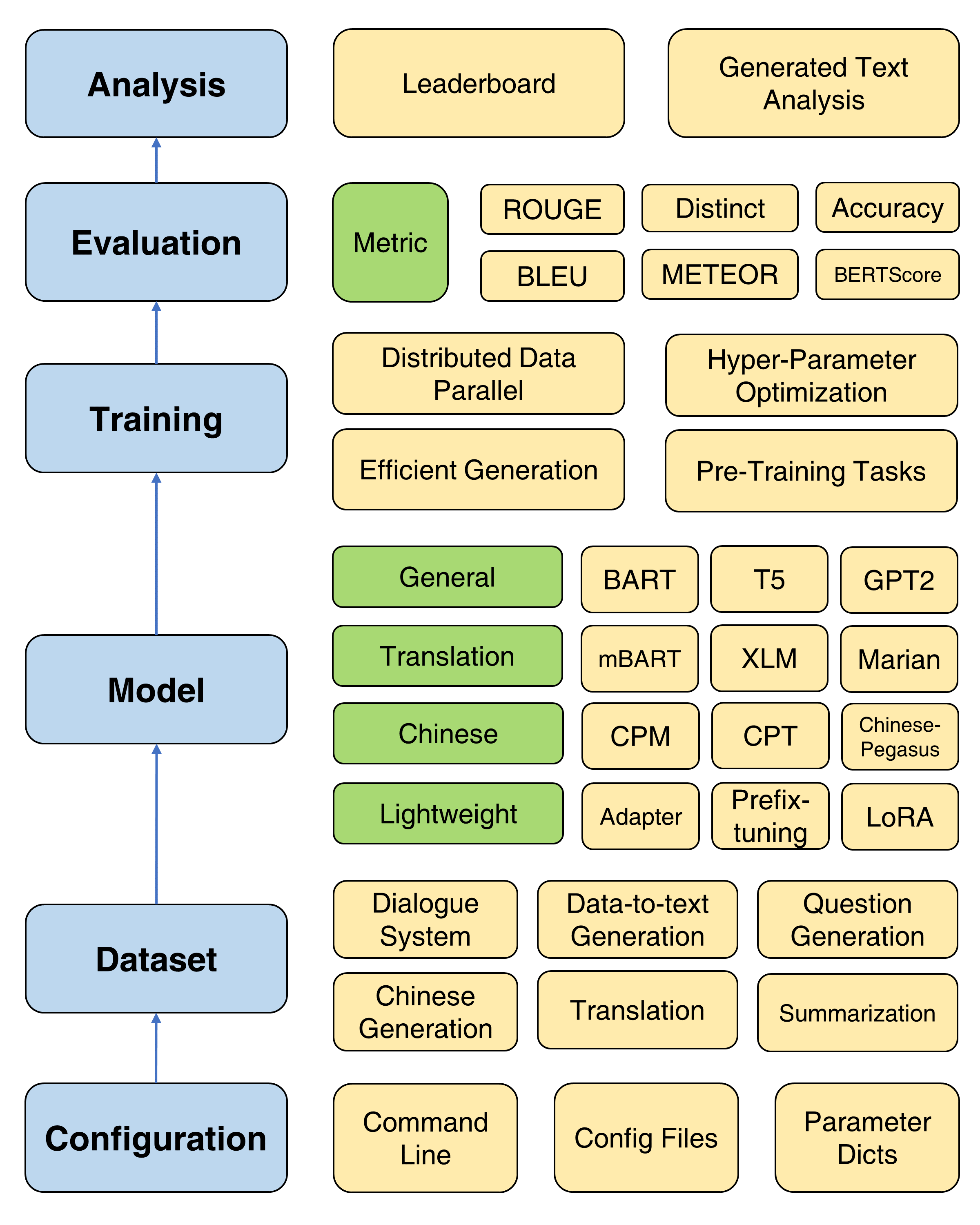
Der Gesamtrahmen von Textbox 2.0
Wenn man bedenkt, dass eine modifizierte Version von Transformers installiert wird, wird empfohlen, eine neue Conda -Umgebung zu erstellen:
conda create -n TextBox python=3.8Dann können Sie unser Repository klonen und mit einem Klick installieren.
git clone https://github.com/RUCAIBox/TextBox.git && cd TextBox
bash install.sh Wenn Sie sich mit einem Problem ROUGE-1.5.5.pl - XML::Parser dependency error bei der Installation files2rouge befassen, können Sie sich auf dieses Problem verweisen.
Dies ist eine Skriptvorlage, mit der Textbox 2.0 in einer End-to-End-Pipeline ausgeführt wird:
python run_textbox.py --model= < model-name > --dataset= < dataset-name > --model_path= < hf-or-local-path > Ersetzt --model=<xxx> , --dataset=<xxx> und --model_path=<xxx> mit Ihren Auswahlmöglichkeiten.
Die Auswahlmöglichkeiten von model und model_path finden Sie im Modell. Wir geben die detaillierte Anweisung jedes Modells auf dieser Seite an.
Die Auswahl des dataset finden Sie im Datensatz. Sie sollten den Datensatz unter https://huggingface.co/rucaibox herunterladen und den heruntergeladenen Datensatz wie Samsum in den dataset -Ordner einstellen. Wenn Sie Ihren eigenen Datensatz verwenden möchten, finden Sie hier hier.
Das folgende Skript wird das Facebook- BART-base Modell im samsum Datensatz ausgeführt:
python run_textbox.py --model=BART --dataset=samsum --model_path=facebook/bart-baseFür die Grundausbildung bieten wir ein detailliertes Tutorial (hier) zum Einstellen von häufig verwendeten Parametern wie Optimierer, Scheduler, Validierungsfrequenz, frühzeitiger Stopp usw.
Textbox 2.0 bietet vier Ziele vor dem Training, mit denen Benutzer ein Modell von Grund auf vorziehen können, einschließlich Sprachmodellierung, maskierter Modellierung von Sequence-to-Sequence, der Beenierung von automatischen Kodierung und maskierter Vorhersage. Ein detailliertes Tutorial finden Sie im Dokument vor dem Training.
Vier nützliche Trainingsmethoden werden zur Verbesserung der Optimierung von PLMs vorgesehen: verteilte Daten parallel, effizientes Dekodieren, Hyperparameteroptimierung und wiederholte Experimente. Hier finden Sie detaillierte Anweisungen.
Um den schnellen Fortschritt von PLMs bei der Textgenerierung zu unterstützen, enthält Textbox 2.0 47 Module/Module, die die Kategorien allgemeiner, Übersetzungen, Chinesisch, Dialogs, kontrollierbar, destilliert, auffordert und leichte Module (Module) abdecken. Informationen zu den detaillierten Verwendungsanweisungen jedes Modells, vor ausgebildeten Modellparametern und Erzeugungsparametern finden Sie im Model DOC.
Jetzt unterstützen wir 13 Generationenaufgaben (z. B. Übersetzungs- und Geschichtenerzeugung) und ihre entsprechenden 83 Datensätze. Wir bieten auch die Beschreibung, grundlegende Statistiken, Schulungen/Validierungs-/Testproben und Rangliste für jeden Datensatz. Weitere Informationen finden Sie hier.
Textbox 2.0 unterstützt 17 automatische Metriken von 4 Kategorien und mehreren Visualisierungstools, um die generierten Texte in verschiedenen Dimensionen zu untersuchen und zu analysieren. Für Bewertungsdetails finden Sie im Bewertungsdoc.
| Veröffentlichungen | Datum | Merkmale |
|---|---|---|
| v2.0.1 | 24/12/2022 | Textbox 2.0 |
| v2.0.0 | 20/08/2022 | Textbox 2.0 Beta |
| v0.2.1 | 15/04/2021 | Textbox |
| v0.1.5 | 01/11/2021 | Grundlegende Textbox |
Bitte teilen Sie uns mit, ob Sie auf einen Fehler stoßen oder Vorschläge haben, indem Sie ein Problem einreichen.
Wir begrüßen alle Beiträge von Fehlerbehebungen bis hin zu neuen Funktionen und Erweiterungen.
Wir erwarten alle Beiträge, die im Themen -Tracker diskutiert werden und PRs durchlaufen.
Wir danken bei @lucastsui0725 für das Hred -Modell und mehrere Bewertungsmetriken.
Wir danken bei @WXDAI für den Beitrag von Pointernet und mehr als 20 Sprachmodellen in Transformers API.
Textbox wird durch das KI -Feld entwickelt und gepflegt.
Textbox verwendet die MIT -Lizenz.
Wenn Sie Textbox 2.0 für Ihre Forschung oder Entwicklung nützlich finden, geben Sie die folgenden Arbeiten an:
@inproceedings{tang-etal-2022-textbox,
title = "{T}ext{B}ox 2.0: A Text Generation Library with Pre-trained Language Models",
author = "Tang, Tianyi and Li, Junyi and Chen, Zhipeng and Hu, Yiwen and Yu, Zhuohao and Dai, Wenxun and Zhao, Wayne Xin and Nie, Jian-yun and Wen, Ji-rong",
booktitle = "Proceedings of the The 2022 Conference on Empirical Methods in Natural Language Processing: System Demonstrations",
month = dec,
year = "2022",
address = "Abu Dhabi, UAE",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2022.emnlp-demos.42",
pages = "435--444",
}
@inproceedings{textbox,
title = "{T}ext{B}ox: A Unified, Modularized, and Extensible Framework for Text Generation",
author = "Li, Junyi and Tang, Tianyi and He, Gaole and Jiang, Jinhao and Hu, Xiaoxuan and Xie, Puzhao and Chen, Zhipeng and Yu, Zhuohao and Zhao, Wayne Xin and Wen, Ji-Rong",
booktitle = "Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing: System Demonstrations",
month = aug,
year = "2021",
address = "Online",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2021.acl-demo.4",
doi = "10.18653/v1/2021.acl-demo.4",
pages = "30--39",
}


