TextBox
TextBox 2.0 Release

«李太白少时 , 梦所用之笔头上生花后天才赡逸 , 名闻天下。” —— 王仁裕《开元天宝遗事 · 梦笔头生花》
TextBox 2.0: une bibliothèque de génération de texte avec des modèles de langue pré-formés
TextBox 2.0 est une bibliothèque de génération de texte à jour basée sur Python et Pytorch se concentrant sur la construction d'un pipeline unifié et standardisé pour appliquer des modèles de langage pré-formés à la génération de texte:
Par rapport à la version précédente de TextBox, cette extension se concentre principalement sur la construction d'un cadre unifié, flexible et standardisé pour mieux supporter des modèles de génération de texte basés sur PLM. Il y a trois avantages de TextBox 2.0:
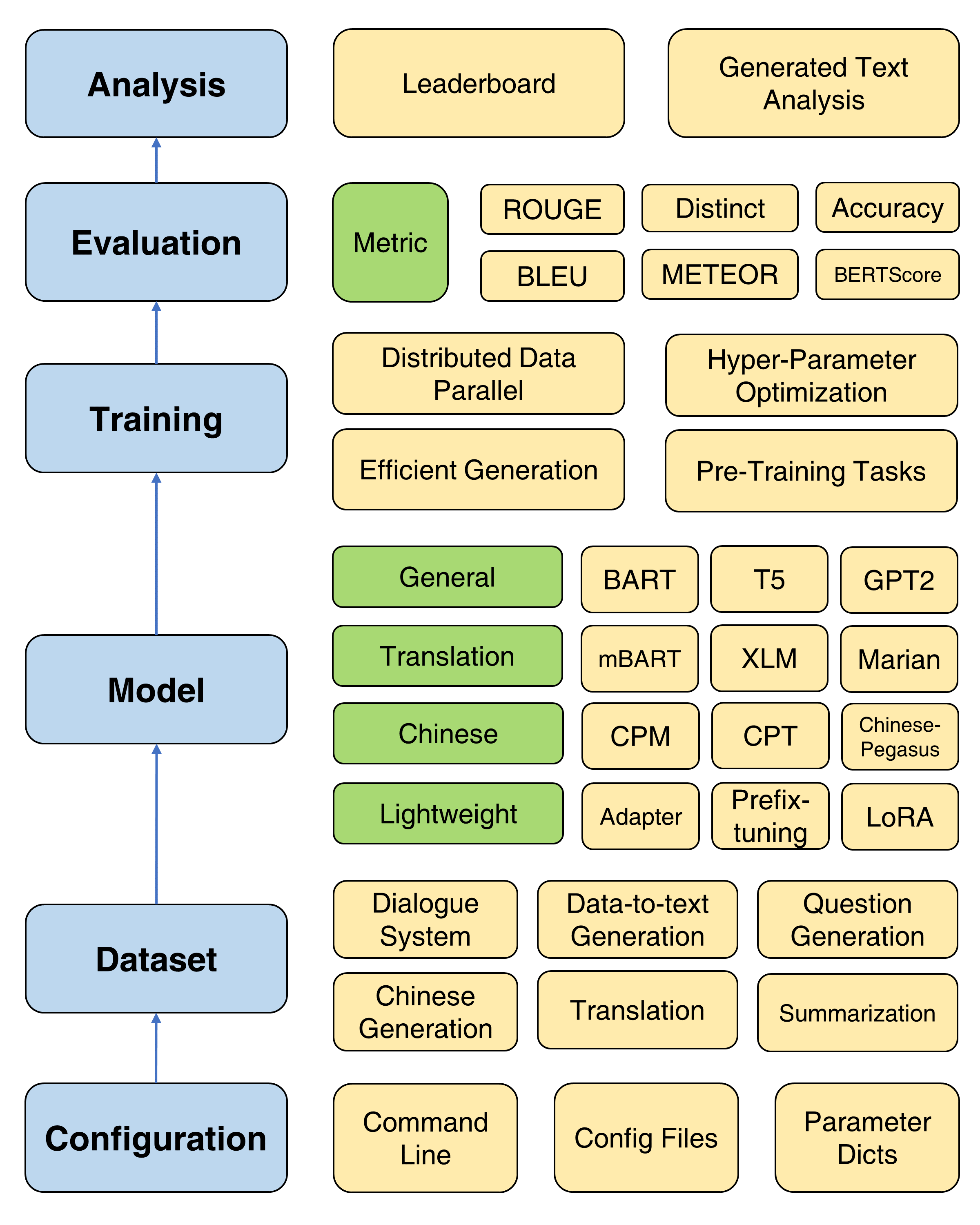
Le cadre global de la zone de texte 2.0
Étant donné qu'une version modifiée des transformateurs sera installée, il est recommandé de créer un nouvel environnement conda:
conda create -n TextBox python=3.8Ensuite, vous pouvez cloner notre référentiel et l'installer en un clic.
git clone https://github.com/RUCAIBox/TextBox.git && cd TextBox
bash install.sh Si vous faites face à un problème ROUGE-1.5.5.pl - XML::Parser dependency error lors de l'installation files2rouge , vous pouvez vous référer à ce problème.
Ceci est un modèle de script pour exécuter TextBox 2.0 dans un pipeline de bout en bout:
python run_textbox.py --model= < model-name > --dataset= < dataset-name > --model_path= < hf-or-local-path > Substitut --model=<xxx> , --dataset=<xxx> et --model_path=<xxx> avec vos choix.
Les choix de model et model_path peuvent être trouvés dans le modèle. Nous fournissons l'instruction détaillée de chaque modèle de cette page.
Les choix de dataset se trouvent dans l'ensemble de données. Vous devez télécharger l'ensemble de données sur https://huggingface.co/rucaibox et mettre le jeu de données téléchargé dans le dossier dataset comme Samsum. Si vous souhaitez utiliser votre propre ensemble de données, veuillez vous référer à ici.
Le script ci-dessous exécutera le modèle Facebook BART-base sur l'ensemble de données samsum :
python run_textbox.py --model=BART --dataset=samsum --model_path=facebook/bart-basePour la formation de base, nous fournissons un tutoriel détaillé (ici) pour définir des paramètres couramment utilisés comme Optimizer, Scheduler, Fréquence de validation, arrêt précoce, etc.
TextBox 2.0 fournit quatre objectifs de pré-formation pour aider les utilisateurs à pré-entraîner un modèle à partir de zéro, y compris la modélisation du langage, la modélisation de séquence à séquence masquée, le cocodage automatique du débraillé et la prédiction de portée masquée. Voir le doc pré-formation pour un tutoriel détaillé.
Quatre méthodes de formation utiles sont fournies pour améliorer l'optimisation des PLMS: données distribuées parallèles, décodage efficace, optimisation hyper-paramètre et expériences répétées. Des instructions détaillées sont fournies ici.
Pour soutenir les progrès rapides des PLM sur la génération de texte, TextBox 2.0 intègre 47 modèles / modules, couvrant les catégories de modèles généraux, de traduction, chinois, de dialogue, contrôlable, distillé, invite et léger (modules). Voir le modèle DOC pour obtenir des informations sur les instructions d'utilisation détaillées de chaque modèle, les paramètres du modèle pré-formé et les paramètres de génération.
Maintenant, nous soutenons 13 tâches de génération (par exemple, traduction et génération d'histoires) et leurs 83 ensembles de données correspondants. Nous fournissons également la description, les statistiques de base, les échantillons de formation / validation / test et de classement pour chaque ensemble de données. Voir plus de détails ici.
TextBox 2.0 prend en charge 17 mesures automatiques de 4 catégories et plusieurs outils de visualisation pour explorer et analyser les textes générés en différentes dimensions. Pour les détails de l'évaluation, consultez l'évaluation DOC.
| Sorties | Date | Caractéristiques |
|---|---|---|
| v2.0.1 | 24/12/2022 | Zone de texte 2.0 |
| v2.0.0 | 20/08/2022 | TextBox 2.0 Beta |
| v0.2.1 | 15/04/2021 | Zone de texte |
| v0.1.5 | 01/11/2021 | Zone de texte de base |
Veuillez nous faire savoir si vous rencontrez un bogue ou si vous avez des suggestions en déposant un problème.
Nous accueillons toutes les contributions des corrections de bogues aux nouvelles fonctionnalités et extensions.
Nous nous attendons à toutes les contributions discutées dans le tracker du numéro et en passant par PRS.
Nous remercions @ Lucastsui0725 d'avoir contribué le modèle Hred et plusieurs mesures d'évaluation.
Nous remercions @wxdai d'avoir contribué Pointernet et plus de 20 modèles de langue dans l'API Transformers.
La zone de texte est développée et maintenue par Box AI.
TextBox utilise la licence MIT.
Si vous trouvez TextBox 2.0 utile pour votre recherche ou votre développement, veuillez citer les articles suivants:
@inproceedings{tang-etal-2022-textbox,
title = "{T}ext{B}ox 2.0: A Text Generation Library with Pre-trained Language Models",
author = "Tang, Tianyi and Li, Junyi and Chen, Zhipeng and Hu, Yiwen and Yu, Zhuohao and Dai, Wenxun and Zhao, Wayne Xin and Nie, Jian-yun and Wen, Ji-rong",
booktitle = "Proceedings of the The 2022 Conference on Empirical Methods in Natural Language Processing: System Demonstrations",
month = dec,
year = "2022",
address = "Abu Dhabi, UAE",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2022.emnlp-demos.42",
pages = "435--444",
}
@inproceedings{textbox,
title = "{T}ext{B}ox: A Unified, Modularized, and Extensible Framework for Text Generation",
author = "Li, Junyi and Tang, Tianyi and He, Gaole and Jiang, Jinhao and Hu, Xiaoxuan and Xie, Puzhao and Chen, Zhipeng and Yu, Zhuohao and Zhao, Wayne Xin and Wen, Ji-Rong",
booktitle = "Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing: System Demonstrations",
month = aug,
year = "2021",
address = "Online",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2021.acl-demo.4",
doi = "10.18653/v1/2021.acl-demo.4",
pages = "30--39",
}


