TextBox
TextBox 2.0 Release

“李太白少时 , 梦所用之笔头上生花后天才赡逸 , 名闻天下。” —— 王仁裕《开元天宝遗事 · 梦笔头生花》
TextBox 2.0: Uma biblioteca de geração de texto com modelos de idiomas pré-treinados
TextBox 2.0 é uma biblioteca de geração de texto atualizada com base em Python e Pytorch, com foco na construção de um pipeline unificado e padronizado para aplicar modelos de idiomas pré-treinados à geração de texto:
Comparado com a versão anterior da caixa de texto, essa extensão se concentra principalmente na criação de uma estrutura unificada, flexível e padronizada para melhor suportar modelos de geração de texto baseados em PLM. Existem três vantagens do TextBox 2.0:
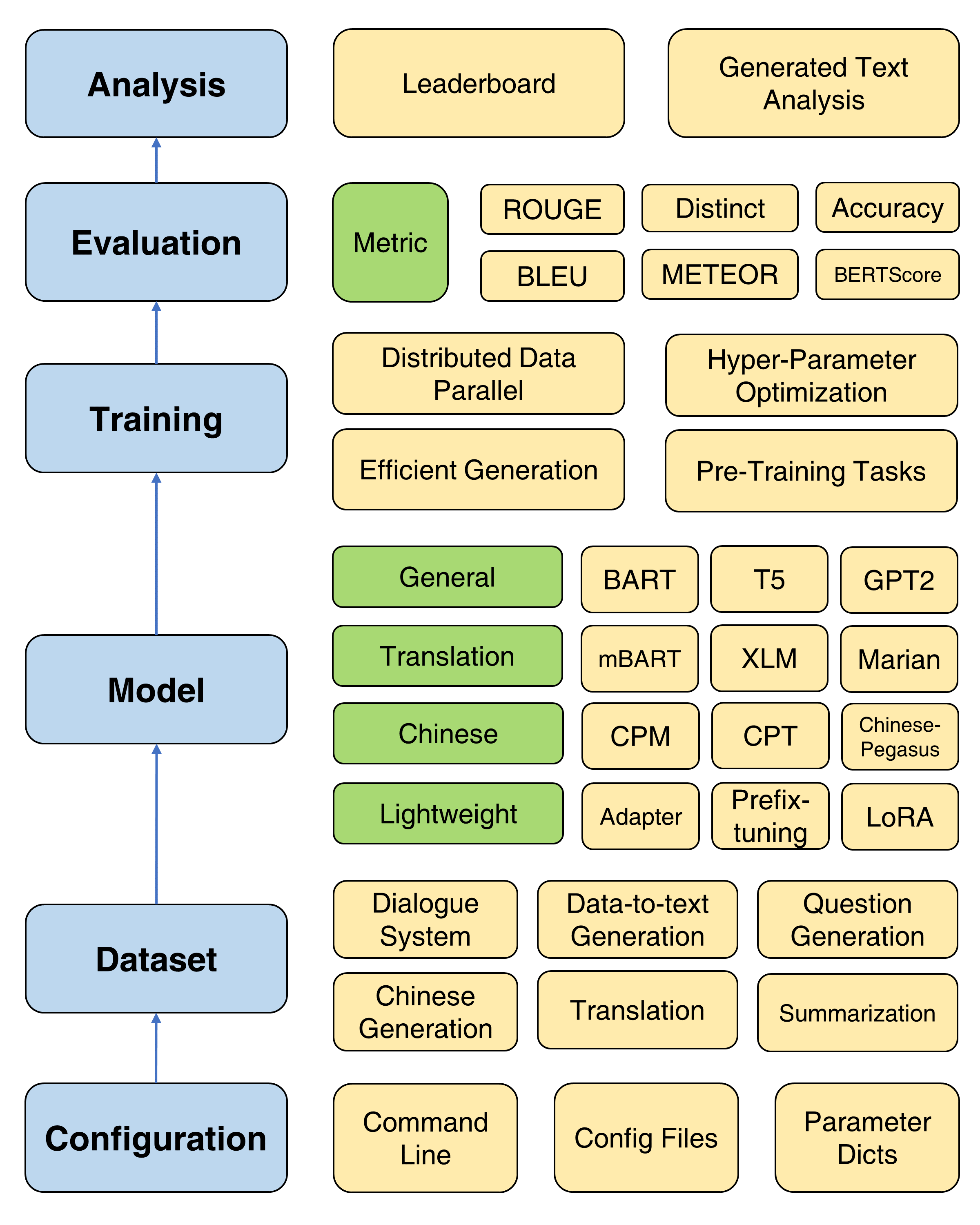
A estrutura geral da caixa de texto 2.0
Considerando que uma versão modificada dos Transformers será instalada, é recomendável criar um novo ambiente do CONDA:
conda create -n TextBox python=3.8Em seguida, você pode clonar nosso repositório e instalá-lo com um clique.
git clone https://github.com/RUCAIBox/TextBox.git && cd TextBox
bash install.sh Se você enfrentar um problema ROUGE-1.5.5.pl - XML::Parser dependency error Ao instalar files2rouge , poderá consultar esse problema.
Este é um modelo de script para executar o TextBox 2.0 em um pipeline de ponta a ponta:
python run_textbox.py --model= < model-name > --dataset= < dataset-name > --model_path= < hf-or-local-path > Substituto --model=<xxx> , --dataset=<xxx> e --model_path=<xxx> com suas opções.
As opções de model e model_path podem ser encontradas no modelo. Fornecemos a instrução detalhada de cada modelo nessa página.
As opções do dataset podem ser encontradas no conjunto de dados. Você deve baixar o conjunto de dados em https://huggingface.co/rucabox e colocar o conjunto de dados baixado na pasta dataset , como o samsum. Se você quiser usar seu próprio conjunto de dados, consulte aqui.
O script abaixo executará o modelo do Facebook BART-base no conjunto de dados samsum :
python run_textbox.py --model=BART --dataset=samsum --model_path=facebook/bart-basePara treinamento básico, fornecemos um tutorial detalhado (aqui) para definir parâmetros comumente usados como otimizador, agendador, frequência de validação, parada precoce e assim por diante.
O TextBox 2.0 fornece quatro objetivos de pré-treinamento para ajudar os usuários a treinar um modelo a partir do zero, incluindo modelagem de idiomas, modelagem de sequência a sequência mascarada, codificação automática de denoising e previsão de span mascarada. Consulte o documento pré-treinamento para um tutorial detalhado.
São fornecidos quatro métodos de treinamento úteis para melhorar a otimização de PLMs: dados distribuídos de dados paralelos e eficientes, otimização de hiper-parâmetro e experimentos repetidos. Instruções detalhadas são fornecidas aqui.
Para suportar o rápido progresso do PLMS na geração de texto, o TextBox 2.0 incorpora 47 modelos/módulos, cobrindo as categorias de modelos gerais, tradução, chinês, diálogo, controlável, destilado, impulsionado e leve (módulos). Consulte o Model Doc para obter informações sobre instruções de uso detalhadas de cada modelo, parâmetros de modelo pré-treinado e parâmetros de geração.
Agora, apoiamos 13 tarefas de geração (por exemplo, tradução e geração de histórias) e seus 83 conjuntos de dados correspondentes. Também fornecemos a descrição, estatísticas básicas, amostras de treinamento/validação/teste e tabela de classificação para cada conjunto de dados. Veja mais detalhes aqui.
O TextBox 2.0 suporta 17 métricas automáticas de 4 categorias e várias ferramentas de visualização para explorar e analisar os textos gerados em várias dimensões. Para detalhes da avaliação, consulte o documento de avaliação.
| Lançamentos | Data | Características |
|---|---|---|
| v2.0.1 | 24/12/2022 | TextBox 2.0 |
| v2.0.0 | 20/08/2022 | TextBox 2.0 Beta |
| v0.2.1 | 15/04/2021 | Caixa de texto |
| v0.1.5 | 01/11/2021 | Caixa de texto básica |
Informe -nos se você encontrar um bug ou tiver alguma sugestão, apresentando um problema.
Congratulamo -nos com todas as contribuições de correções de bugs para novos recursos e extensões.
Esperamos todas as contribuições discutidas no rastreador de questões e passando pelo PRS.
Agradecemos ao @LucastSui0725 por contribuir com o HRED Model e várias métricas de avaliação.
Agradecemos ao @WXDAI por contribuir com Pointernet e mais de 20 modelos de idiomas na API Transformers.
O TextBox é desenvolvido e mantido pela caixa AI.
TextBox usa o MIT License.
Se você encontrar o TextBox 2.0 útil para sua pesquisa ou desenvolvimento, cite os seguintes trabalhos:
@inproceedings{tang-etal-2022-textbox,
title = "{T}ext{B}ox 2.0: A Text Generation Library with Pre-trained Language Models",
author = "Tang, Tianyi and Li, Junyi and Chen, Zhipeng and Hu, Yiwen and Yu, Zhuohao and Dai, Wenxun and Zhao, Wayne Xin and Nie, Jian-yun and Wen, Ji-rong",
booktitle = "Proceedings of the The 2022 Conference on Empirical Methods in Natural Language Processing: System Demonstrations",
month = dec,
year = "2022",
address = "Abu Dhabi, UAE",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2022.emnlp-demos.42",
pages = "435--444",
}
@inproceedings{textbox,
title = "{T}ext{B}ox: A Unified, Modularized, and Extensible Framework for Text Generation",
author = "Li, Junyi and Tang, Tianyi and He, Gaole and Jiang, Jinhao and Hu, Xiaoxuan and Xie, Puzhao and Chen, Zhipeng and Yu, Zhuohao and Zhao, Wayne Xin and Wen, Ji-Rong",
booktitle = "Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing: System Demonstrations",
month = aug,
year = "2021",
address = "Online",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2021.acl-demo.4",
doi = "10.18653/v1/2021.acl-demo.4",
pages = "30--39",
}


