conv emotion
1.0.0
For those enquiring about how to extract visual and audio features, please check this out: https://github.com/soujanyaporia/MUStARD
| 日期 | 公告 |
|---|---|
| 10/03/2024 | 如果您對智商測試LLM感興趣,請查看我們的新作品:algopuzzlevqa |
| 03/08/2021 | ? ?我們發布了一個新的數據集M2H2:一種多模式多派對印地語數據集,用於對話中的幽默識別。檢查一下:M2H2。 M2H2數據集的基線是根據Dialoguernn和BCLSTM創建的。 |
| 18/05/2021 | ? ?我們發布了一個包含模型的新存儲庫,以解決情感問題在對話中引起識別。檢查一下:情緒原因萃取。感謝Pengfei Hong對此進行了彙編。 |
| 24/12/2020 | ? ?對識別對話中情感原因的話題感興趣嗎?我們剛剛發布了一個數據集。前往https://github.com/declare-lab/reccon。 |
| 06/10/2020 | ? ?新論文和SOTA在對話中的情感識別中。請參閱代碼目錄宇宙。閱讀論文 - 宇宙:對話中情感識別的常識知識。 |
| 30/09/2020 | 發表了發言級對話理解中的新論文和基線。閱讀我們的紙張話語級對話理解:一項實證研究。分叉代碼。 |
| 26/07/2020 | 新的對話GCN代碼已發布。請訪問https://github.com/declare-lab/conv-emotion/tree/master/dialoguegcn-mianzhang。所有的榮譽都歸功於Mian Zhang(https://github.com/mianzhang/) |
| 11/07/2020 | 有興趣閱讀有關ERC或相關任務的論文,例如對話中的諷刺檢測?我們已經彙編了有關論文的全面閱讀列表。請訪問https://github.com/declare-lab/awesome-emotion-rcognition-in-conversations |
| 07/06/2020: | ERC任務的最新結果將很快發布。 |
| 07/06/2020: | Conv-emotion回購將在https://github.com/declare-lab/上維護 |
| 22/12/2019: | 對話代碼已發布。 |
| 2019年11月10日: | 新論文:情感識別的會話轉移學習。 |
| 09/08/2019: | 關於對話中情感識別的新論文(ERC)。 |
| 06/03/2019: | 已發布了在MELD數據集上訓練Dialoguernn的功能和代碼。 |
| 20/11/2018: | 端到端版本的圖標和Dialoguernn已發布。 |
宇宙是此存儲庫中最佳性能模型,請訪問下面的鏈接以比較不同的ERC數據集上的模型。
該存儲庫包含對話方法中幾種情緒識別的實現,以及識別對話中情緒原因的算法:
與其他情感檢測模型不同,這些技術考慮了黨派和黨派依賴性,以建模與情感識別相關的會話環境。所有這些技術的主要目的是為同理心對話的產生預算一個情感檢測模型。
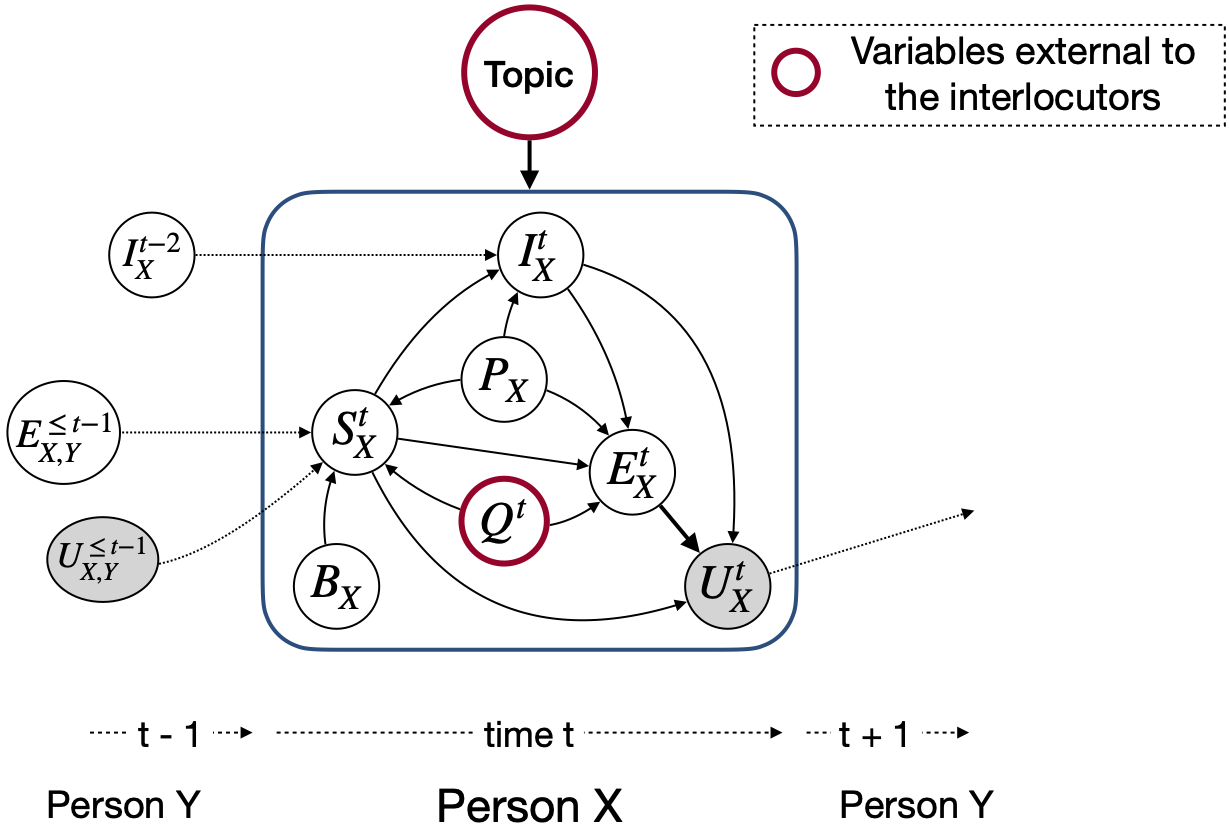
情緒識別對於善解人意和情感對話的產生非常有用 -
這些網絡期望在對話中的每種話語中的情感/情感標籤和揚聲器信息
Party 1: I hate my girlfriend (angry)
Party 2: you got a girlfriend?! (surprise)
Party 1: yes (angry)
但是,可以將代碼擬合以執行只有前面的話語而沒有相應標籤的任務,因為上下文和目標是僅標記當前/目標話語。例如,上下文是
Party 1: I hate my girlfriend
Party 2: you got a girlfriend?!
目標是
Party 1: yes (angry)
目標情緒生氣的地方。此外,該代碼也可以模製以以端到端的方式訓練網絡。我們很快將推動這些有用的更改。
| 方法 | Iemocap | DailyDialog | 融合 | emorynlp | |||
|---|---|---|---|---|---|---|---|
| w-avg f1 | 宏F1 | 微F1 | W-avg F1(3-CLS) | W-AVG F1(7-CLS) | W-avg F1(3-CLS) | W-AVG F1(7-CLS) | |
| 羅伯塔 | 54.55 | 48.20 | 55.16 | 72.12 | 62.02 | 55.28 | 37.29 |
| 羅伯塔對話 | 64.76 | 49.65 | 57.32 | 72.14 | 63.61 | 55.36 | 37.44 |
| 羅伯塔宇宙 | 65.28 | 51.05 | 58.48 | 73.20 | 65.21 | 56.51 | 38.11 |
宇宙通過使用常識知識在對話中解決了話語水平情感識別的任務。這是一個新框架,結合了常識性的不同要素,例如精神狀態,事件和因果關係,並在他們基礎上學習參加對話的對話者之間的互動。當前的最新方法通常在上下文傳播,情感轉移檢測以及相關情緒類別之間遇到困難。通過學習不同的常識性表示,宇宙解決了這些挑戰,並在四個不同的基準對話數據集上實現了新的最新結果,以識別情感。

首先在此處下載Roberta和Comet功能,並將其保留在COSMIC/erc-training中的適當目錄中。然後,對四個數據集進行培訓和評估應如下完成:
python train_iemocap.py --active-listenerpython train_dailydialog.py --active-listener --class-weight --residualpython train_meld.py --active-listener --attention simple --dropout 0.5 --rec_dropout 0.3 --lr 0.0001 --mode1 2 --classify emotion --mu 0 --l2 0.00003 --epochs 60python train_meld.py --active-listener --class-weight --residual --classify sentimentpython train_emorynlp.py --active-listener --class-weight --residualpython train_emorynlp.py --active-listener --class-weight --residual --classify sentiment如果您發現此代碼對您的工作有用,請引用以下論文。
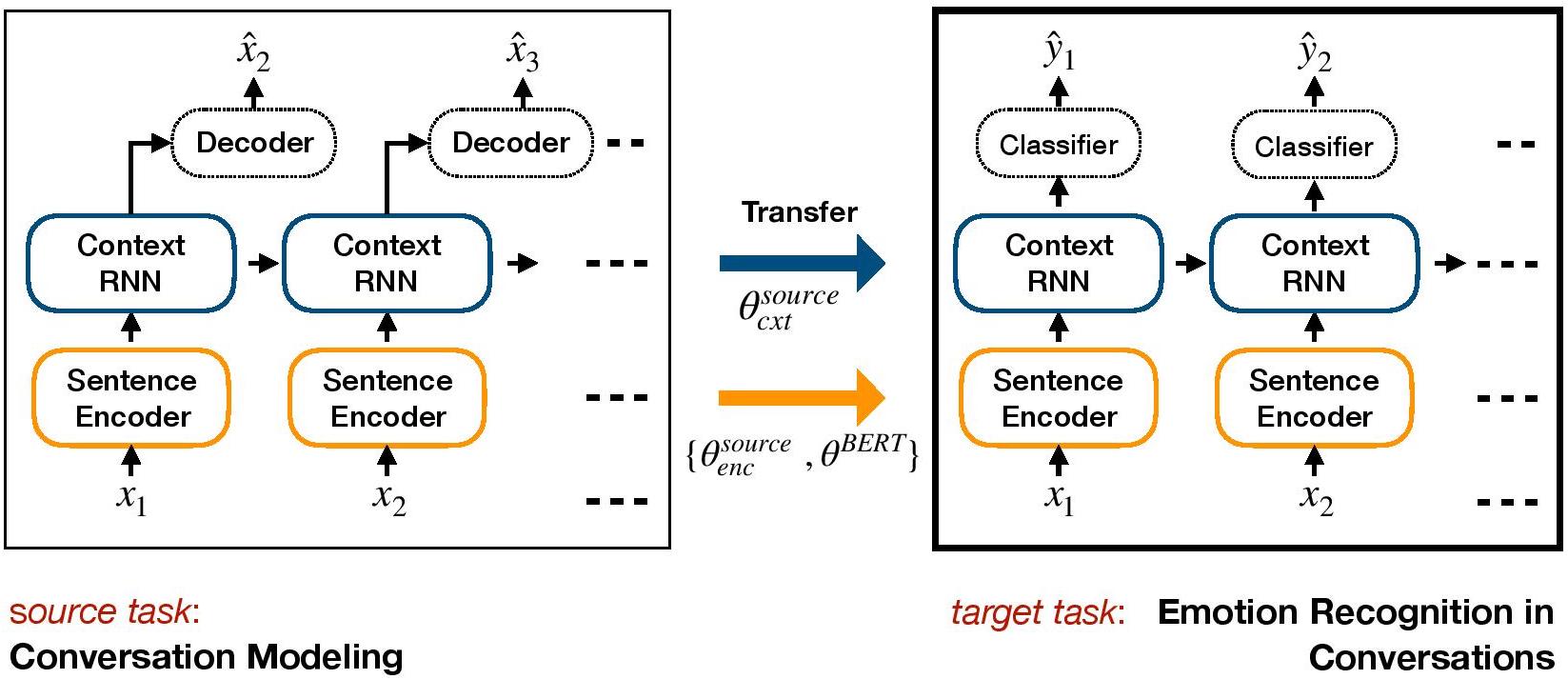
COSMIC: COmmonSense knowledge for eMotion Identification in Conversations. D. Ghosal, N. Majumder, A. Gelbukh, R. Mihalcea, & S. Poria. Findings of EMNLP 2020.TL-ERC是ERC的基於轉移學習的框架。它可以預先培訓生成對話模型,並將上下文級別的權重傳輸,這些權重包括情感知識到ERC的目標判別模型中。
使用Conda設置環境:
conda env create -f environment.yml
conda activate TL_ERC
cd TL_ERC
python setup.py下載數據集文件IEMocap,DailyDialog並將其存儲在./datasets/中。
下載康奈爾和Ubuntu數據集上HRED的預./generative_weights/的重量
[可選]:要訓練對話模型的新生成權重,請參閱https://github.com/ctr4si/a-hierarchical-latent-sonstructure-for-variational-conversation-modeling。
cd bert_modelpython train.py --load_checkpoint=../generative_weights/cornell_weights.pkl --data=iemocap 。cornell更改為ubuntu和iemocap ,以dailydialog其他數據集組合。load_checkpoint以避免初始化上下文權重。configs.pypython iemocap_preprocess.py 。同樣適用於dailydialog 。如果您發現此代碼對您的工作有用,請引用以下論文。
Conversational transfer learning for emotion recognition. Hazarika, D., Poria, S., Zimmermann, R., & Mihalcea, R. (2020). Information Fusion.對話GCN (對話圖卷積網絡)是基於圖神經網絡的ERC方法。我們利用對話者的自我和言論揚聲器的依賴性來模擬情緒識別的對話環境。通過圖表網絡,對話核能解決了當前基於RNN的方法中存在的上下文傳播問題。對話GCN自然適合多方對話。

注意:Pytorch幾何形狀大量使用了CUDA原子操作,並且是非確定性的來源。為了複製論文中報告的結果,我們建議使用以下執行命令。請注意,此腳本將在CPU中執行。我們使用以下命令遵守機器中的加權平均F1分數為64.67,而Iemocap數據集的Google合作製作中有64.44個。
python train_IEMOCAP.py --base-model 'LSTM' --graph-model --nodal-attention --dropout 0.4 --lr 0.0003 --batch-size 32 --class-weight --l2 0.0 --no-cuda如果您發現此代碼對您的工作有用,請引用以下論文。
DialogueGCN: A Graph Convolutional Neural Network for Emotion Recognition in Conversation. D. Ghosal, N. Majumder, S. Poria, N. Chhaya, & A. Gelbukh. EMNLP-IJCNLP (2019), Hong Kong, China.Pytorch實施到“對話:對話中情感識別的圖形卷積神經網絡”。
您可以很容易地運行整個過程。以Iemocap語料庫為例:
./scripts/iemocap.sh preprocess./scripts/iemocap.sh train| - | 數據集 | 加權F1 |
|---|---|---|
| 原來的 | Iemocap | 64.18% |
| 這個實現 | Iemocap | 64.10% |
Mian Zhang(Github:Mianzhang)
如果您發現此代碼對您的工作有用,請引用以下論文。
DialogueGCN: A Graph Convolutional Neural Network for Emotion Recognition in Conversation. D. Ghosal, N. Majumder, S. Poria, N. Chhaya, & A. Gelbukh. EMNLP-IJCNLP (2019), Hong Kong, China.Dialoguernn基本上是一種自定義的複發性神經網絡(RNN),它在即時的對話/對話中介紹了每個說話者,而同時對話的上下文進行了建模。該模型可以輕鬆地擴展到多方方案。同樣,它可以用作循環訓練的模型,用於產生同理心對話。
注意:代碼中的默認設置(超參數和命令行參數)用於bidialoguernn+att。用戶需要優化其他變體和更改的設置。 
請提取DialogueRNN_features.zip的內容。
python train_IEMOCAP.py <command-line arguments>python train_AVEC.py <command-line arguments>--no-cuda :不使用GPU--lr :學習率--l2 :L2正則重量--rec-dropout :recurrent輟學--dropout :輟學--batch-size :批量大小--epochs :時代的數量--class-weight :班級體重(不適用於AVEC)--active-listener :明確的Lisnener模式--attention :注意類型--tensorboard :啟用張板日誌--attribute :屬性1至4(僅適用於AVEC; 1 = VAINCE,2 =激活/喚醒,3 =預期/期望,4 =功率)如果您發現此代碼對您的工作有用,請引用以下論文。
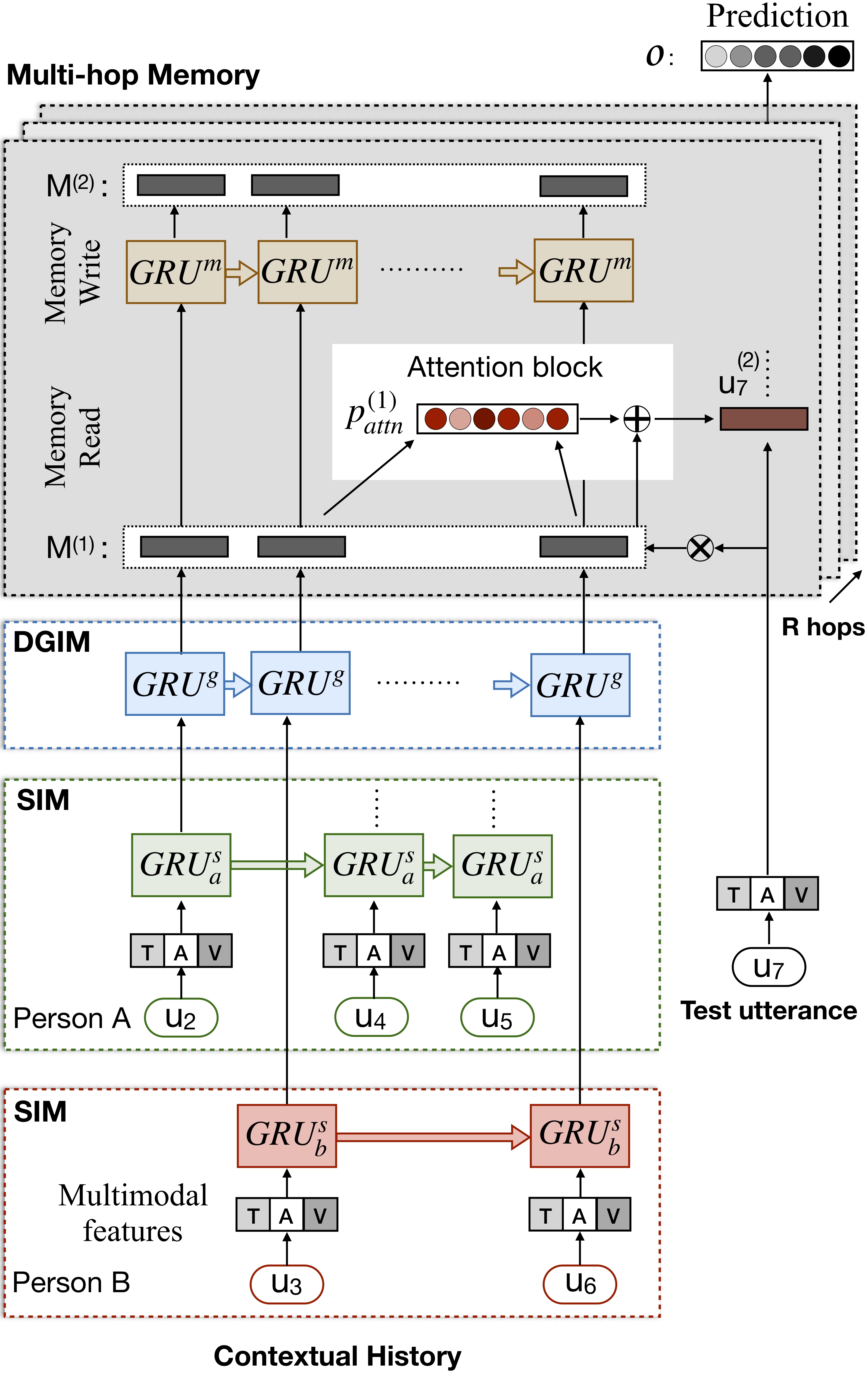
DialogueRNN: An Attentive RNN for Emotion Detection in Conversations. N. Majumder, S. Poria, D. Hazarika, R. Mihalcea, E. Cambria, and G. Alexander. AAAI (2019), Honolulu, Hawaii, USA交互式對話記憶網絡(ICON)是一個多模式的情感檢測框架,從對話視頻中提取多模式特徵,並層次對 textit {self}和 textit {self textit {speacher}情感影響到全球記憶。這些記憶產生了上下文摘要,有助於預測話語視頻的情感取向。
cd ICON
解壓縮數據如下:
/ICON/IEMOCAP/data/ 。示例命令要實現這一目標: unzip {path_to_zip_file} -d ./IEMOCAP/訓練圖標模型:
python train_iemocap.py for IemocapICON: Interactive Conversational Memory Networkfor Multimodal Emotion Detection. D. Hazarika, S. Poria, R. Mihalcea, E. Cambria, and R. Zimmermann. EMNLP (2018), Brussels, Belgium CMN是二元對話中情感檢測的神經框架。它利用文本,音頻和視覺方式的mutlimodal信號。它專門將特定於說話者的依賴項納入其體系結構以進行上下文建模。然後使用多跳存儲網絡從此上下文中生成摘要。 
cd CMN
解壓縮數據如下:
/CMN/IEMOCAP/data/ 。示例命令要實現這一目標: unzip {path_to_zip_file} -d ./IEMOCAP/訓練圖標模型:
python train_iemocap.py for Iemocap如果您發現此代碼對您的工作有用,請引用以下論文。
Hazarika, D., Poria, S., Zadeh, A., Cambria, E., Morency, L.P. and Zimmermann, R., 2018. Conversational Memory Network for Emotion Recognition in Dyadic Dialogue Videos. In Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long Papers) (Vol. 1, pp. 2122-2132).BC-LSTM-PYTORCH是一個網絡,用於使用上下文來檢測對話中的話語。該模型是簡單但有效的,它僅使用LSTM來建模話語之間的時間關係。在此存儲庫中,我們提供了Semeval 2019 Task 3的數據。我們使用並提供了Semeval 2019 Task 3發布的數據3-“情感識別”組織者。在此任務中,只提供了3個話語-Tustance1(user1),Tusterance2(user2),Tusterance3(user1)連續。任務是預測話語的情感標籤3。尚未提供每種話語的情感標籤。但是,如果您的數據包含每個話語的情感標籤,則您仍然可以使用此代碼並相應地調整它。因此,此代碼對於Mosi,Mosei,Iemocap,AVEC,DailyDialogue等數據集仍然可以合理化。 BC-LSTM不利用諸如CMN,ICON和DIALOGUERERNN之類的揚聲器信息。
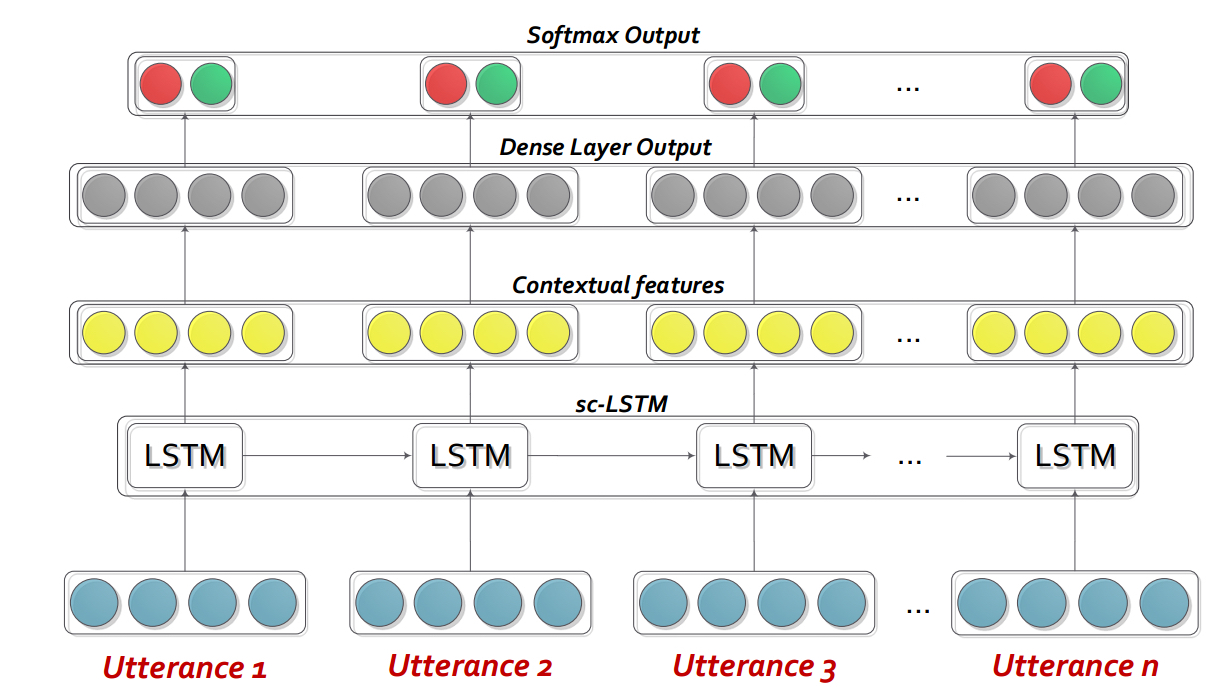
cd bc-LSTM-pytorch
訓練BC-LSTM模型:
python train_IEMOCAP.py for Iemocap如果您發現此代碼對您的工作有用,請引用以下論文。
Poria, S., Cambria, E., Hazarika, D., Majumder, N., Zadeh, A. and Morency, L.P., 2017. Context-dependent sentiment analysis in user-generated videos. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) (Vol. 1, pp. 873-883).KERAS實施BC-LSTM 。
cd bc-LSTM
訓練BC-LSTM模型:
python baseline.py -config testBaseline.config如果您發現此代碼對您的工作有用,請引用以下論文。
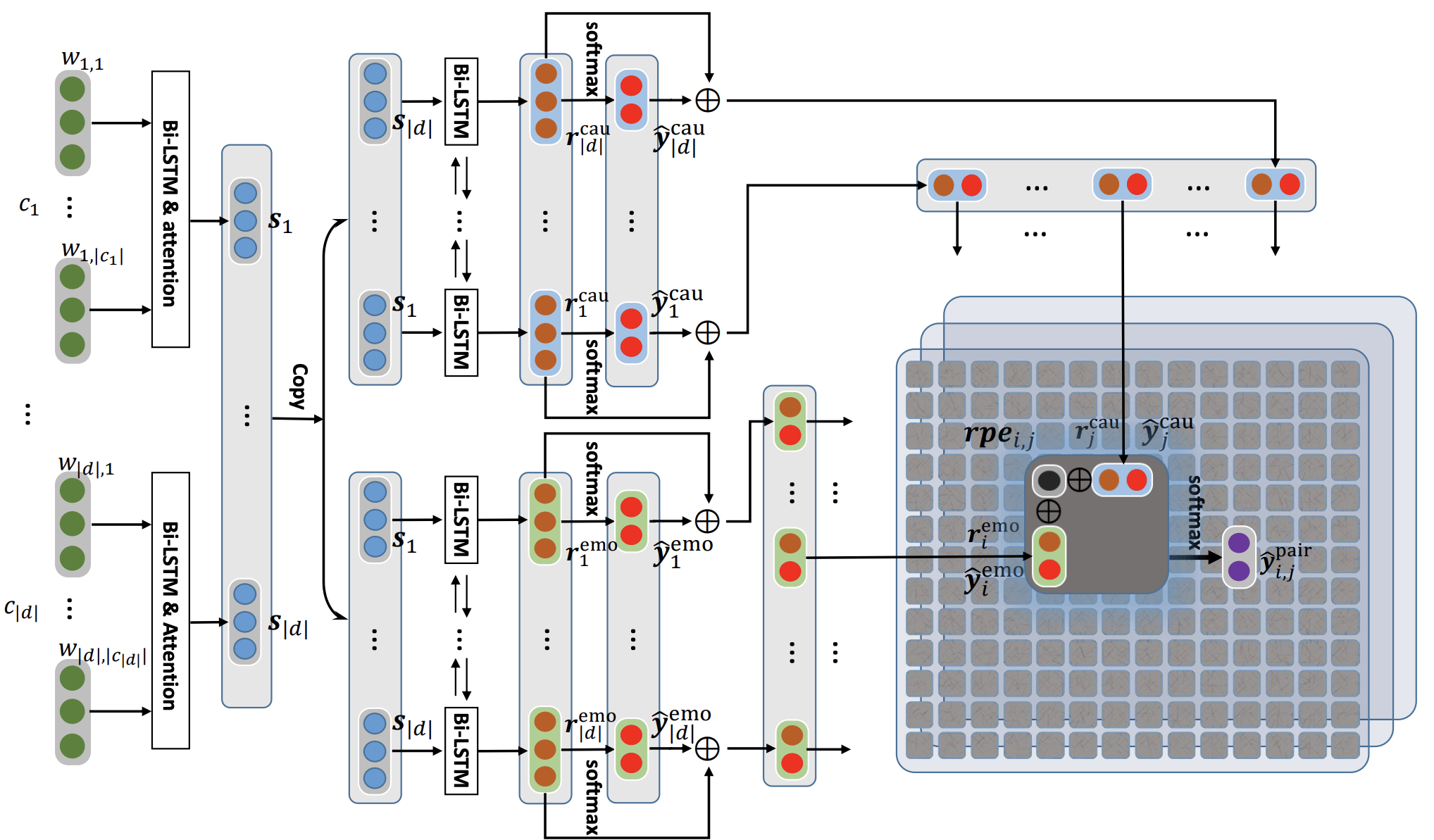
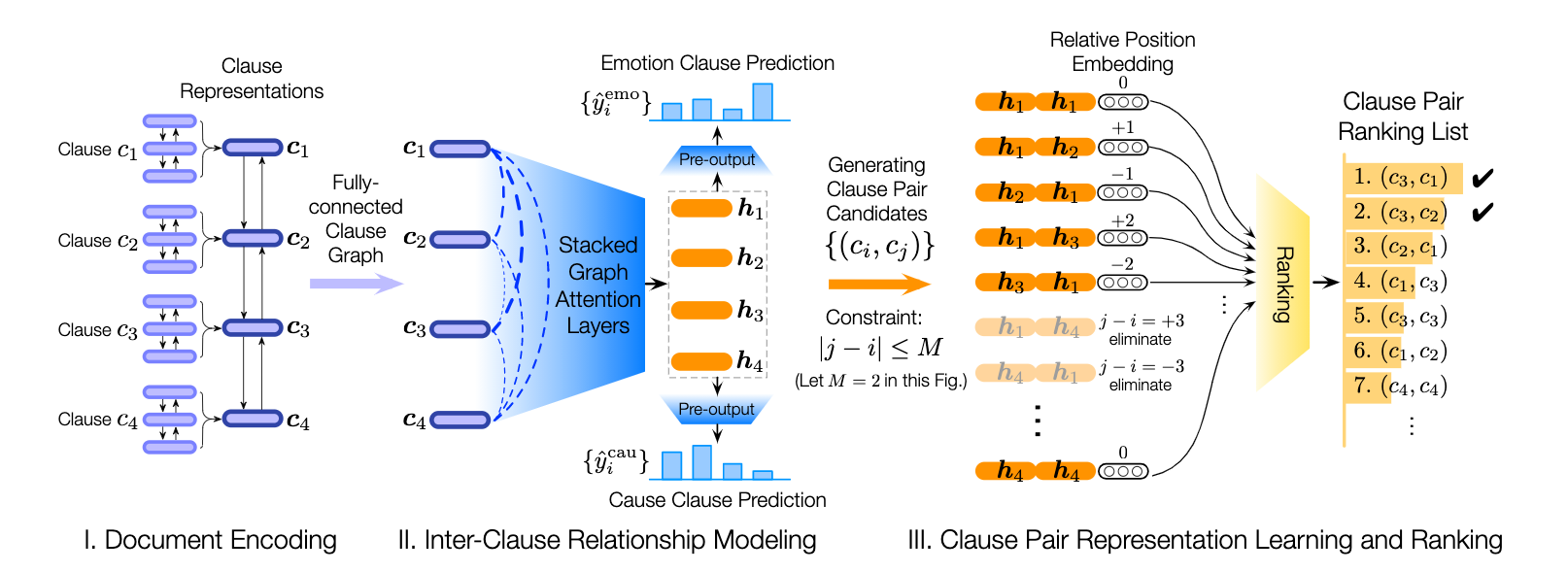
Poria, S., Cambria, E., Hazarika, D., Majumder, N., Zadeh, A. and Morency, L.P., 2017. Context-dependent sentiment analysis in user-generated videos. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) (Vol. 1, pp. 873-883).該存儲庫還包含不同體系結構的實現,以檢測對話中的情感原因。

| 模型 | emo_f1 | POS_F1 | neg_f1 | macro_avg |
|---|---|---|---|---|
| ECPE-2D Cross_Rad (0變換層) | 52.76 | 52.39 | 95.86 | 73.62 |
| ECPE-2D窗口_受限 (1個變換層) | 70.48 | 48.80 | 93.85 | 71.32 |
| ECPE-2D Cross_Rad (2變換層) | 52.76 | 55.50 | 94.96 | 75.23 |
| ECPE-MLL | - | 48.48 | 94.68 | 71.58 |
| 排名情感原因 | - | 33.00 | 97.30 | 65.15 |
| 羅伯塔基地 | - | 64.28 | 88.74 | 76.51 |
| 羅伯塔·萊爾格(Roberta-Large) | - | 66.23 | 87.89 | 77.06 |
引用:如果您使用此代碼,請引用以下論文。
引用:如果您使用此代碼,請引用以下論文。
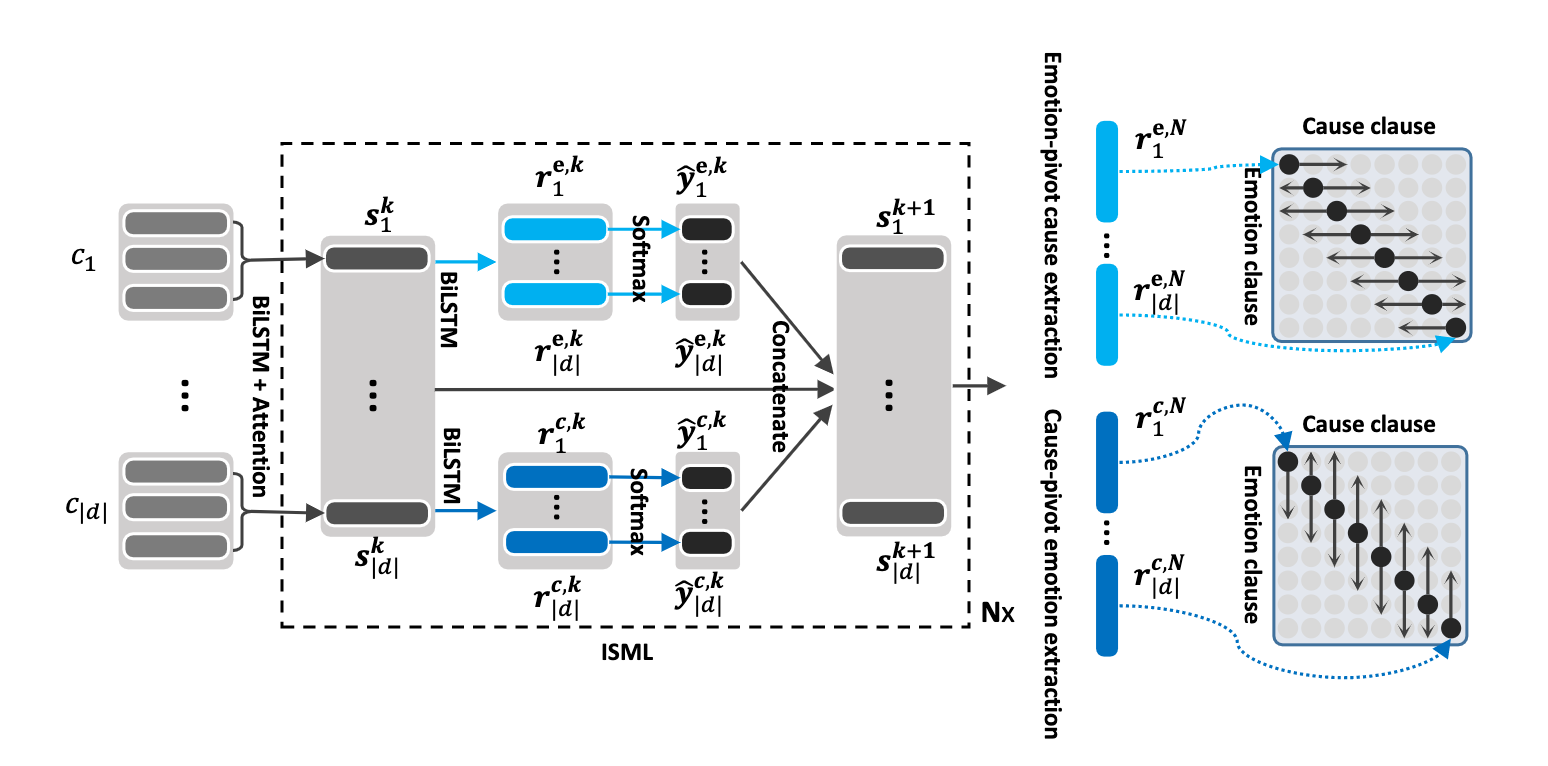
引用:如果您使用此代碼,請引用以下論文。
原始Reccon論文中解釋了羅伯塔和Spanbert Baselines。請參考。
引用:如果您使用此代碼,請引用以下論文。


