conv emotion
1.0.0
For those enquiring about how to extract visual and audio features, please check this out: https://github.com/soujanyaporia/MUStARD
| 日付 | 発表 |
|---|---|
| 10/03/2024 | IQテストLLMSに興味がある場合は、新しい作品をご覧ください:algopuzzlevqa |
| 03/08/2021 | ? ?新しいデータセットM2H2:マルチモーダルマルチパーティヒンディー語データセットをリリースして、会話でユーモア認識のために。それをチェックしてください:M2H2。 M2H2データセットのベースラインは、DialoguernnとBCLSTMに基づいて作成されます。 |
| 18/05/2021 | ? ?モデルを含む新しいリポジトリをリリースして、感情の問題を解決し、会話の認識を引き起こします。それをチェックしてください:感情原因と抽出。これをコンパイルしてくれたPengfei Hongに感謝します。 |
| 24/12/2020 | ? ?会話で感情の原因を認識するトピックに興味がありますか?このためのデータセットをリリースしました。 https://github.com/declare-lab/recconにアクセスしてください。 |
| 06/10/2020 | ? ?会話の感情認識における新しい紙とソタ。コードのディレクトリコスミックを参照してください。論文を読む - 宇宙:会話における感情識別のための常識的な知識。 |
| 30/09/2020 | 発話レベルの対話の理解における新しい論文とベースラインがリリースされました。私たちの論文の発言レベルの対話の理解:経験的研究を読んでください。コードをフォークします。 |
| 26/07/2020 | 新しいDialogueGCNコードがリリースされました。 https://github.com/declare-lab/conv-emotion/tree/master/dialoguegcn-mianzhangにアクセスしてください。すべてのクレジットはミアン・チャン(https://github.com/mianzhang/)に送られます |
| 11/07/2020 | ERCに関する論文や、会話での皮肉検出などの関連するタスクを読むことに興味がありますか?論文の包括的な読書リストをまとめました。 https://github.com/declare-lab/awesome-emotion-ecognition-in conversationsをご覧ください |
| 07/06/2020: | ERCタスクの新しい最先端の結果はまもなくリリースされます。 |
| 07/06/2020: | Conv-Emotion Repoはhttps://github.com/declare-lab/に維持されます |
| 22/12/2019: | DialogueGCNのコードがリリースされました。 |
| 2019年11月10日: | 新しい論文:感情認識のための会話転送学習。 |
| 09/08/2019: | 会話における感情認識に関する新しい論文(ERC)。 |
| 06/03/2019: | MELDデータセットでDialoguernnをトレーニングする機能とコードがリリースされました。 |
| 20/11/2018: | アイコンとDialogunnのエンドツーエンドバージョンがリリースされました。 |
Cosmicはこのレポで最高のパフォーマンスモデルであり、以下のリンクにアクセスして、異なるERCデータセットのモデルを比較してください。
このリポジトリには、会話方法におけるいくつかの感情認識の実装と、会話の感情原因を認識するためのアルゴリズムが含まれています。
他の感情検出モデルとは異なり、これらの手法は、感情認識に関連する会話のコンテキストをモデル化するためのパーティーステートとパーティー間依存関係を考慮します。これらすべての手法の主な目的は、共感的な対話生成のための感情検出モデルを冒険することです。
感情の認識は、共感的で感情的な対話の生成に非常に役立ちます -
これらのネットワークは、次のような対話に存在する各発話の感情/センチメントラベルとスピーカー情報を期待しています
Party 1: I hate my girlfriend (angry)
Party 2: you got a girlfriend?! (surprise)
Party 1: yes (angry)
ただし、コンテキストと目標は現在/ターゲットの発話のみにラベルを付けることであるため、対応するラベルなしで、前の発話のみが利用可能なタスクを実行するためにコードを添付することができます。たとえば、コンテキストはです
Party 1: I hate my girlfriend
Party 2: you got a girlfriend?!
ターゲットはです
Party 1: yes (angry)
ターゲットの感情が怒っているところ。さらに、このコードは、エンドツーエンドの方法でネットワークをトレーニングするために成形することもできます。すぐにこれらの有用な変更をプッシュします。
| 方法 | iEmocap | DailyDialog | 融合 | emorynlp | |||
|---|---|---|---|---|---|---|---|
| W-AVG F1 | マクロF1 | マイクロF1 | W-AVG F1(3-CLS) | W-AVG F1(7-CLS) | W-AVG F1(3-CLS) | W-AVG F1(7-CLS) | |
| ロベルタ | 54.55 | 48.20 | 55.16 | 72.12 | 62.02 | 55.28 | 37.29 |
| Roberta Dialoguernn | 64.76 | 49.65 | 57.32 | 72.14 | 63.61 | 55.36 | 37.44 |
| ロベルタ・コスミック | 65.28 | 51.05 | 58.48 | 73.20 | 65.21 | 56.51 | 38.11 |
Cosmicは、常識的な知識を使用して会話における発話レベルの感情認識のタスクに対処します。これは、精神状態、出来事、因果関係など、常識のさまざまな要素を組み込んでおり、会話に参加する対話者間の相互作用を学ぶためにそれらに基づいて構築する新しいフレームワークです。現在の最先端の方法は、コンテキストの伝播、感情シフトの検出、および関連する感情のクラスを区別する困難に遭遇することがよくあります。個別の常識表現を学ぶことにより、Cosmicはこれらの課題に対処し、4つの異なるベンチマーク会話データセットで感情認識のための新しい最新の結果を達成します。

最初にRobertaとCometの機能をここにダウンロードし、 COSMIC/erc-trainingの適切なディレクトリに保管してください。次に、4つのデータセットでのトレーニングと評価を次のように行う必要があります。
python train_iemocap.py --active-listenerpython train_dailydialog.py --active-listener --class-weight --residualpython train_meld.py --active-listener --attention simple --dropout 0.5 --rec_dropout 0.3 --lr 0.0001 --mode1 2 --classify emotion --mu 0 --l2 0.00003 --epochs 60python train_meld.py --active-listener --class-weight --residual --classify sentimentpython train_emorynlp.py --active-listener --class-weight --residualpython train_emorynlp.py --active-listener --class-weight --residual --classify sentimentこのコードがあなたの作品に役立つ場合は、次の論文を引用してください。
COSMIC: COmmonSense knowledge for eMotion Identification in Conversations. D. Ghosal, N. Majumder, A. Gelbukh, R. Mihalcea, & S. Poria. Findings of EMNLP 2020.TL-ERCは、ERCの転送学習ベースのフレームワークです。発生的な対話モデルを事前にトレーニングし、ERCのターゲット識別モデルに感情的な知識を含むコンテキストレベルの重みを転送します。
コンドラで環境をセットアップする:
conda env create -f environment.yml
conda activate TL_ERC
cd TL_ERC
python setup.pyデータセットファイルiEmocap、dailydialogをダウンロードして、 ./datasets/ /に保存します。
CornellおよびUbuntuデータセットでhredの事前に訓練されたウェイトをダウンロードして、 ./generative_weights/ generative_weights/に保存します
[オプション]:ダイアログモデルからの新しい生成ウェイトをトレーニングするには、https://github.com/ctr4si/a-hierarchical-latent-structure-for-variational-conversation-modelingを参照してください。
cd bert_modelpython train.py --load_checkpoint=../generative_weights/cornell_weights.pkl --data=iemocap 。cornell ubuntuに変更し、 iemocap dailydialogに変更します。load_checkpointをドロップして、コンテキストウェイトの初期化を避けます。configs.py確認してくださいpython iemocap_preprocess.py 。同様に、 dailydialogについて。このコードがあなたの作品に役立つ場合は、次の論文を引用してください。
Conversational transfer learning for emotion recognition. Hazarika, D., Poria, S., Zimmermann, R., & Mihalcea, R. (2020). Information Fusion.DialogueGCN (Dialogue Graph Convolution Network)は、ERCへのグラフニューラルネットワークベースのアプローチです。私たちは、対話者の自己およびスピーカー間依存関係を活用して、感情認識のために会話のコンテキストをモデル化します。グラフネットワークを介して、DialogueGCNは、現在のRNNベースの方法に存在するコンテキスト伝播の問題に対処します。 DialogueGCNは、マルチパーティダイアログに自然に適しています。

注:Pytorch Geometricは、CUDA原子作業を大量に使用し、非決定的な源です。論文で報告されている結果を再現するには、次の実行コマンドを使用することをお勧めします。このスクリプトはCPUで実行されることに注意してください。次のコマンドを使用して、私たちのマシンで64.67の加重平均F1スコア、Google Colaboratoraty for IEMoCapデータセットで64.44を採用しました。
python train_IEMOCAP.py --base-model 'LSTM' --graph-model --nodal-attention --dropout 0.4 --lr 0.0003 --batch-size 32 --class-weight --l2 0.0 --no-cudaこのコードがあなたの作品に役立つ場合は、次の論文を引用してください。
DialogueGCN: A Graph Convolutional Neural Network for Emotion Recognition in Conversation. D. Ghosal, N. Majumder, S. Poria, N. Chhaya, & A. Gelbukh. EMNLP-IJCNLP (2019), Hong Kong, China.Pytorchの紙「DialogueGcn:会話における感情認識のためのグラフ畳み込みニューラルネットワーク」への実装。
プロセス全体を非常に簡単に実行できます。 IEMOCAPコーパスを取り上げます。例:
./scripts/iemocap.sh preprocess./scripts/iemocap.sh train| - | データセット | 加重F1 |
|---|---|---|
| オリジナル | iEmocap | 64.18% |
| この実装 | iEmocap | 64.10% |
ミアン・チャン(Github:Mianzhang)
このコードがあなたの作品に役立つ場合は、次の論文を引用してください。
DialogueGCN: A Graph Convolutional Neural Network for Emotion Recognition in Conversation. D. Ghosal, N. Majumder, S. Poria, N. Chhaya, & A. Gelbukh. EMNLP-IJCNLP (2019), Hong Kong, China.Dialoguernnは基本的に、各スピーカーをその場での会話/対話でプロファイルするカスタマイズされた再発性ニューラルネットワーク(RNN)であり、同時に会話のコンテキストをモデル化します。このモデルは、マルチパーティシナリオに簡単に拡張できます。また、共感的な対話生成のための事前トレーニングモデルとして使用できます。
注:コードのデフォルト設定(ハイパーパラメーターとコマンドライン引数)は、Bidialoguernn+attを対象としています。ユーザーは、他のバリアントと変更の設定を最適化する必要があります。 
DialogueRNN_features.zipの内容を抽出してください。
python train_IEMOCAP.py <command-line arguments>python train_AVEC.py <command-line arguments>--no-cuda :GPUは使用しません--lr :学習率--l2 :L2正規化重量--rec-dropout :再発ドロップアウト--dropout :ドロップアウト--batch-size :バッチサイズ--epochs :エポックの数--class-weight :クラスの重量(AVECには適用できません)--active-listener :明示的なLisnenerモード--attention :注意タイプ--tensorboard :テンソルボードログを有効にします--attribute :属性1〜4(AVEC; 1 = Valence、2 = Activation/Aurousal、3 =期待/期待、4 =パワー)このコードがあなたの作品に役立つ場合は、次の論文を引用してください。
DialogueRNN: An Attentive RNN for Emotion Detection in Conversations. N. Majumder, S. Poria, D. Hazarika, R. Mihalcea, E. Cambria, and G. Alexander. AAAI (2019), Honolulu, Hawaii, USAインタラクティブな会話メモリネットワーク(アイコン)は、会話型ビデオからマルチモーダル機能を抽出し、 textit {self}および textit {interpeaker}感情的な影響をグローバルな記憶に階層的にモデル化するマルチモーダル感情検出フレームワークです。このような記憶は、発話と自由の感情的な方向性を予測するのに役立つ文脈的要約を生成します。
cd ICON
次のようにデータを解凍します。
/ICON/IEMOCAP/data/ 。これを達成するためのサンプルコマンド: unzip {path_to_zip_file} -d ./IEMOCAP/アイコンモデルをトレーニングします:
python train_iemocap.pyICON: Interactive Conversational Memory Networkfor Multimodal Emotion Detection. D. Hazarika, S. Poria, R. Mihalcea, E. Cambria, and R. Zimmermann. EMNLP (2018), Brussels, Belgium CMNは、ダイアディックな会話における感情検出のための神経枠組みです。テキスト、オーディオ、視覚的なモダリティからのミトリモーダル信号を活用します。特に、コンテキストモデリングのためのアーキテクチャにスピーカー固有の依存関係を組み込んでいます。次に、マルチホップメモリネットワークを使用して、このコンテキストから概要が生成されます。 
cd CMN
次のようにデータを解凍します。
/CMN/IEMOCAP/data/ 。これを達成するためのサンプルコマンド: unzip {path_to_zip_file} -d ./IEMOCAP/アイコンモデルをトレーニングします:
python train_iemocap.pyこのコードがあなたの作品に役立つ場合は、次の論文を引用してください。
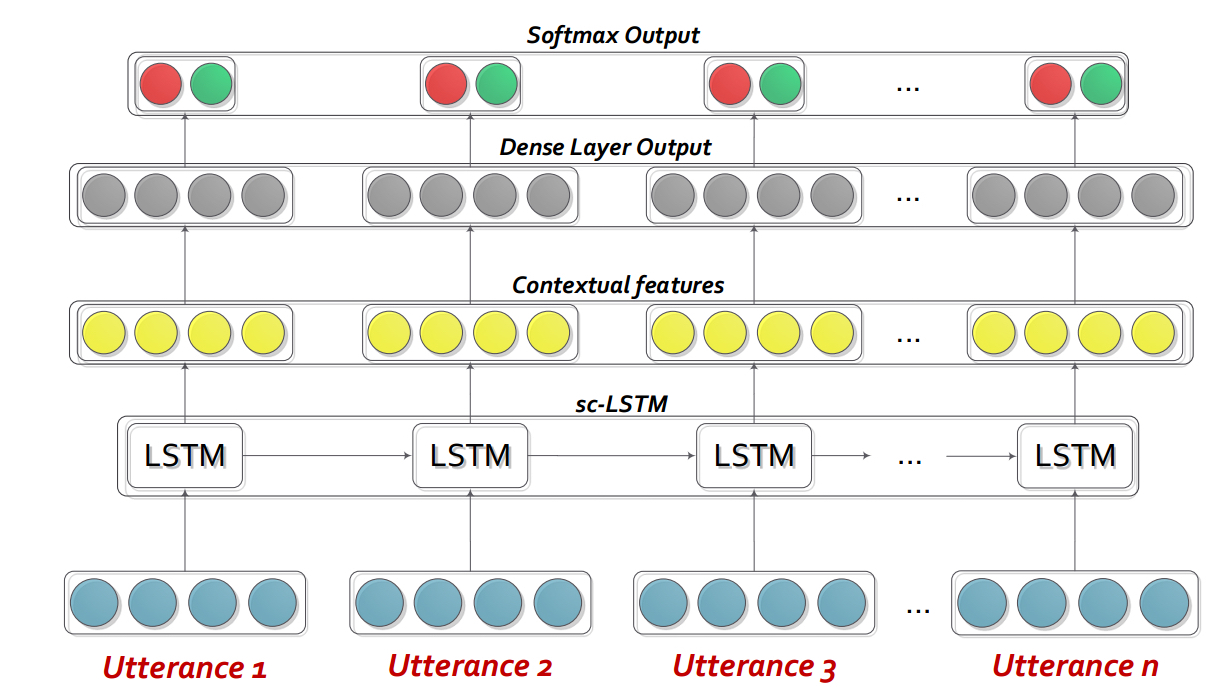
Hazarika, D., Poria, S., Zadeh, A., Cambria, E., Morency, L.P. and Zimmermann, R., 2018. Conversational Memory Network for Emotion Recognition in Dyadic Dialogue Videos. In Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long Papers) (Vol. 1, pp. 2122-2132).BC-LSTM-Pytorchは、コンテキストを使用して対話で発話の感情を検出するためのネットワークです。モデルはシンプルですが効率的で、LSTMのみを使用して発話間の時間的関係をモデル化します。このレポでは、Semeval 2019タスク3のデータを提供しました。Semeval2019タスク3がリリースしたデータを使用して提供し、「コンテキストでの感情認識」主催者を提供しました。このタスクでは、3つの発言のみが提供されています-Utterance1(user1)、utterance2(user2)、utterance3(user1)連続して。タスクは、発言の感情ラベルを予測することです3。各発話の感情ラベルは提供されていません。ただし、データに各発話の感情ラベルが含まれている場合、このコードを使用してそれに応じて適応させることができます。したがって、このコードは、MOSI、Mosei、IEMOCAP、AVEC、AveC、DailyDialogueなどのデータセットに対してまだ識別できません。BC-LSTMは、CMN、アイコン、Dialoguernnなどのスピーカー情報を使用していません。
cd bc-LSTM-pytorch
BC-LSTMモデルをトレーニングします:
python train_IEMOCAP.pyこのコードがあなたの作品に役立つ場合は、次の論文を引用してください。
Poria, S., Cambria, E., Hazarika, D., Majumder, N., Zadeh, A. and Morency, L.P., 2017. Context-dependent sentiment analysis in user-generated videos. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) (Vol. 1, pp. 873-883).KERAS BC-LSTMの実装。
cd bc-LSTM
BC-LSTMモデルをトレーニングします:
python baseline.py -config testBaseline.config for iEmocapこのコードがあなたの作品に役立つ場合は、次の論文を引用してください。
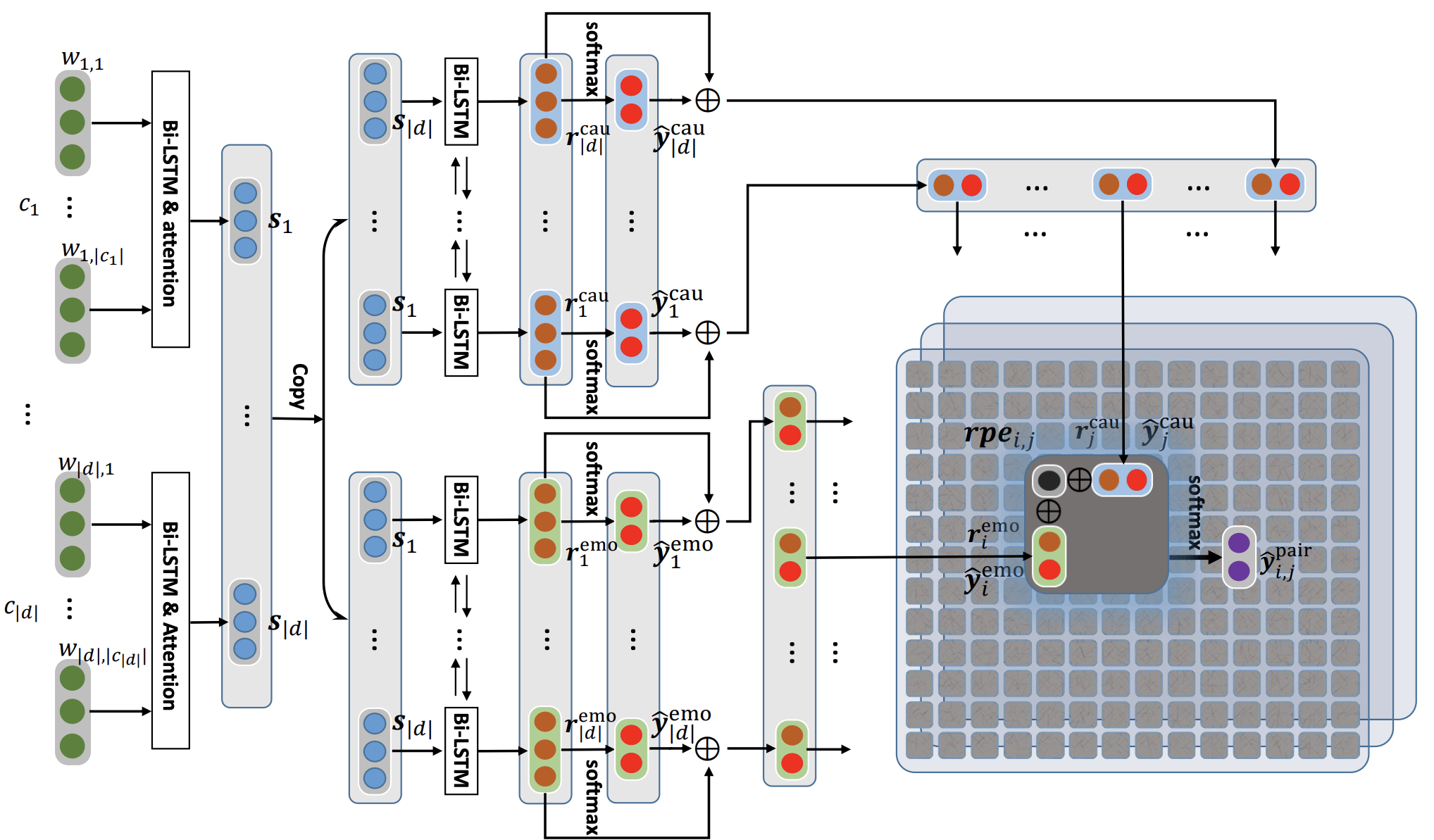
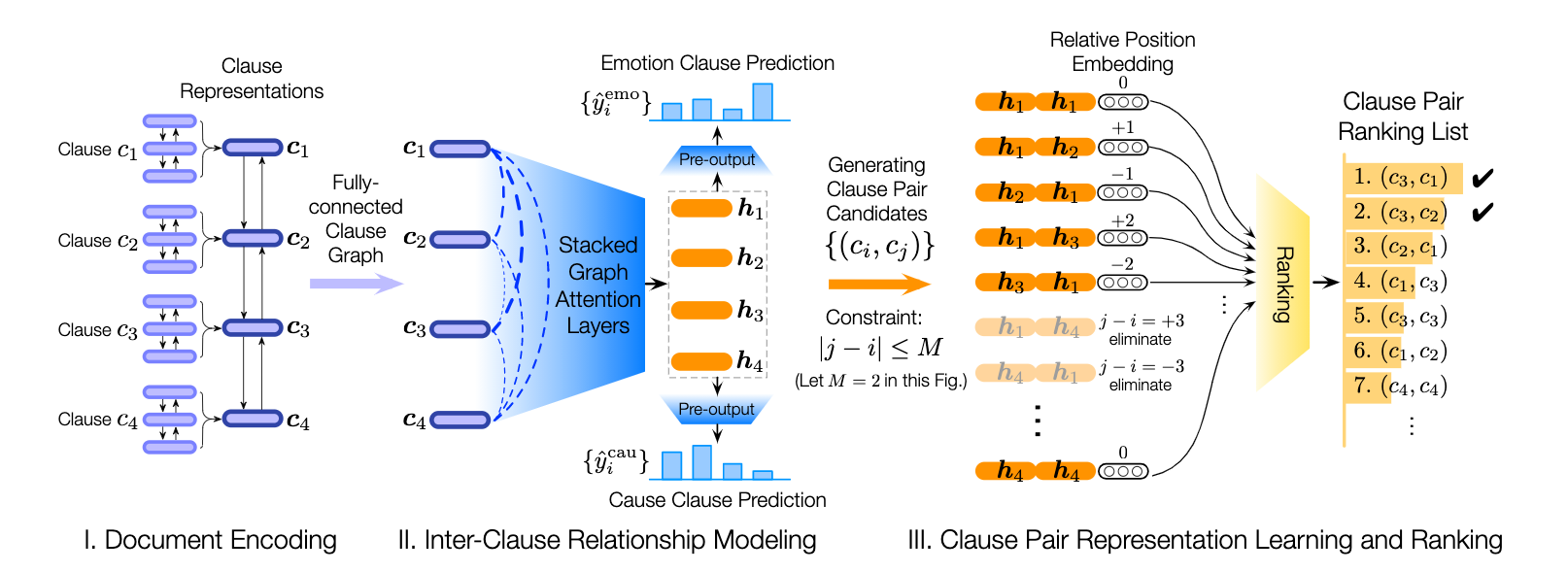
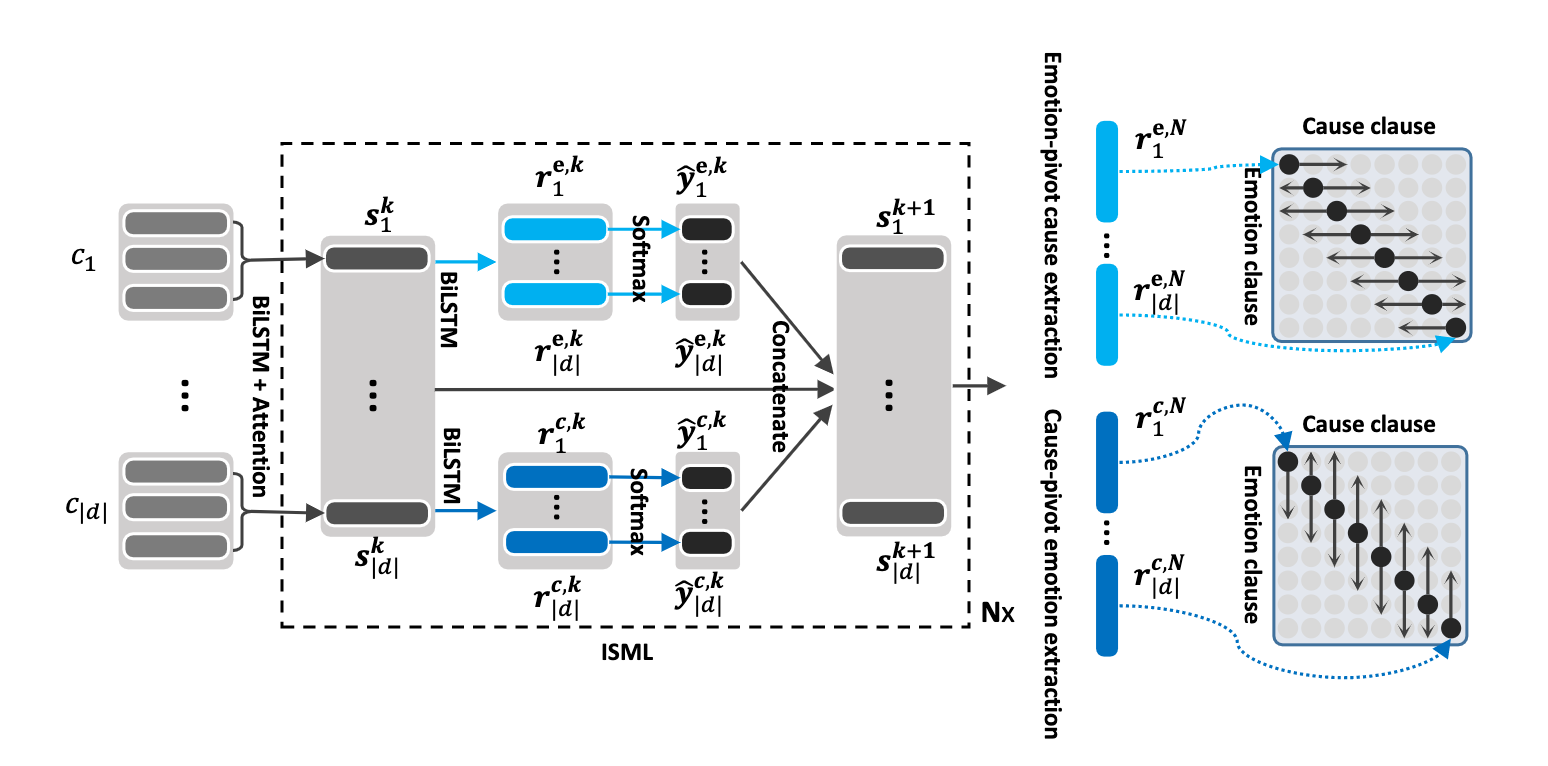
Poria, S., Cambria, E., Hazarika, D., Majumder, N., Zadeh, A. and Morency, L.P., 2017. Context-dependent sentiment analysis in user-generated videos. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) (Vol. 1, pp. 873-883).このリポジトリには、会話の感情原因を検出するためのさまざまなアーキテクチャの実装も含まれています。

| モデル | emo_f1 | POS_F1 | neg_f1 | Macro_Avg |
|---|---|---|---|---|
| ECPE-2D Cross_road (0変換層) | 52.76 | 52.39 | 95.86 | 73.62 |
| ECPE-2D Window_Constrained (1つの変換層) | 70.48 | 48.80 | 93.85 | 71.32 |
| ECPE-2D Cross_road (2つの変換層) | 52.76 | 55.50 | 94.96 | 75.23 |
| ecpe-mll | - | 48.48 | 94.68 | 71.58 |
| ランク感情原因 | - | 33.00 | 97.30 | 65.15 |
| ロベルタベース | - | 64.28 | 88.74 | 76.51 |
| ロベルタ・ラージ | - | 66.23 | 87.89 | 77.06 |
引用:このコードを使用する場合は、次の論文を引用してください。
引用:このコードを使用する場合は、次の論文を引用してください。
引用:このコードを使用する場合は、次の論文を引用してください。
元のReccon Paperで説明されているように、RobertaとSpanbertのベースライン。これを参照してください。
引用:このコードを使用する場合は、次の論文を引用してください。


