conv emotion
1.0.0
For those enquiring about how to extract visual and audio features, please check this out: https://github.com/soujanyaporia/MUStARD
| 日期 | 公告 |
|---|---|
| 10/03/2024 | 如果您对智商测试LLM感兴趣,请查看我们的新作品:algopuzzlevqa |
| 03/08/2021 | ? ?我们发布了一个新的数据集M2H2:一种多模式多派对印地语数据集,用于对话中的幽默识别。检查一下:M2H2。 M2H2数据集的基线是根据Dialoguernn和BCLSTM创建的。 |
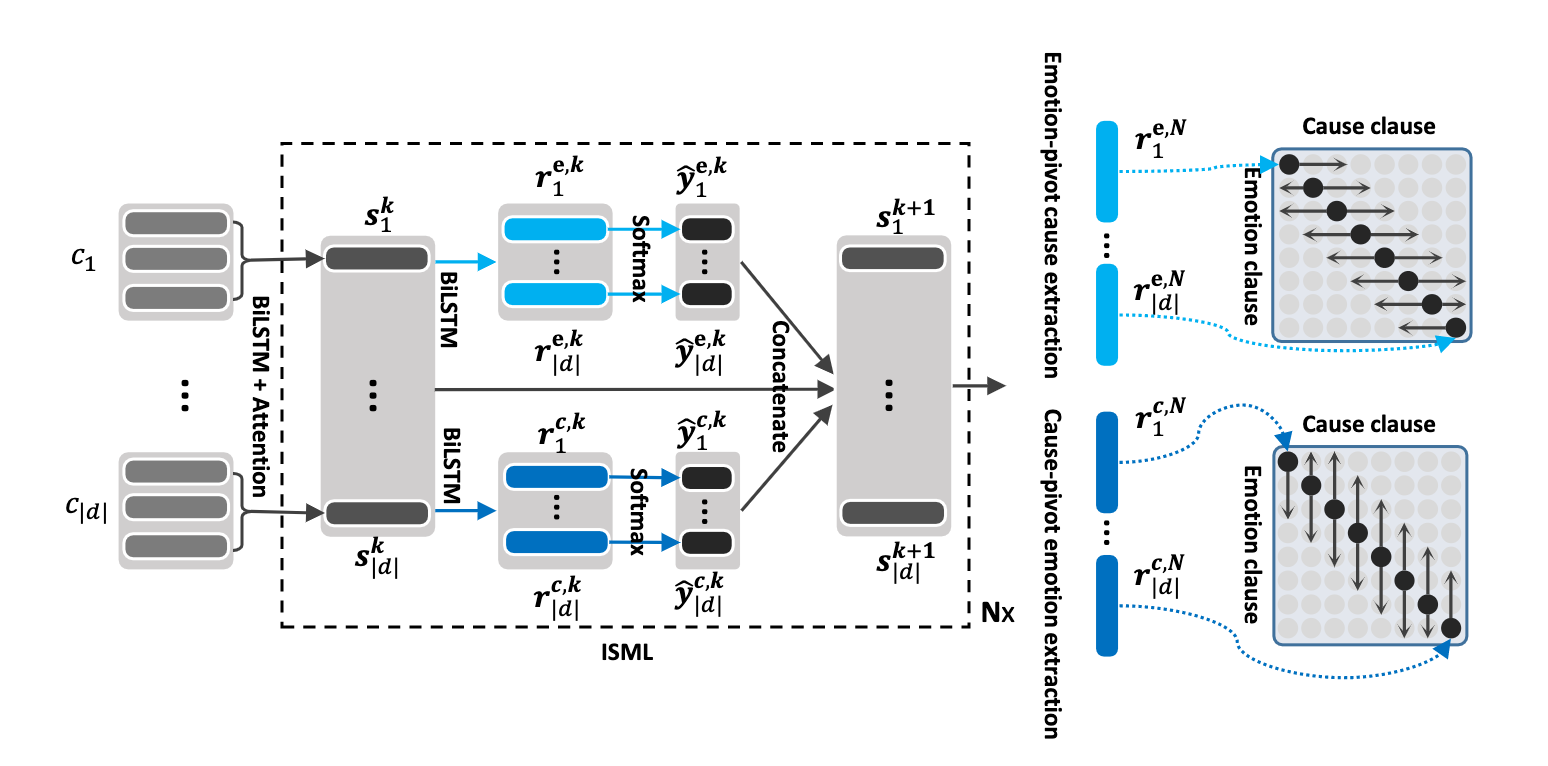
| 18/05/2021 | ? ?我们发布了一个包含模型的新存储库,以解决情感问题在对话中引起识别。检查一下:情绪原因萃取。感谢Pengfei Hong对此进行了汇编。 |
| 24/12/2020 | ? ?对识别对话中情感原因的话题感兴趣吗?我们刚刚发布了一个数据集。前往https://github.com/declare-lab/reccon。 |
| 06/10/2020 | ? ?新论文和SOTA在对话中的情感识别中。请参阅代码目录宇宙。阅读论文 - 宇宙:对话中情感识别的常识知识。 |
| 30/09/2020 | 发表了发言级对话理解中的新论文和基线。阅读我们的纸张话语级对话理解:一项实证研究。分叉代码。 |
| 26/07/2020 | 新的对话GCN代码已发布。请访问https://github.com/declare-lab/conv-emotion/tree/master/dialoguegcn-mianzhang。所有的荣誉都归功于Mian Zhang(https://github.com/mianzhang/) |
| 11/07/2020 | 有兴趣阅读有关ERC或相关任务的论文,例如对话中的讽刺检测?我们已经汇编了有关论文的全面阅读列表。请访问https://github.com/declare-lab/awesome-emotion-rcognition-in-conversations |
| 07/06/2020: | ERC任务的最新结果将很快发布。 |
| 07/06/2020: | Conv-emotion回购将在https://github.com/declare-lab/上维护 |
| 22/12/2019: | 对话代码已发布。 |
| 2019年11月10日: | 新论文:情感识别的会话转移学习。 |
| 09/08/2019: | 关于对话中情感识别的新论文(ERC)。 |
| 06/03/2019: | 已发布了在MELD数据集上训练Dialoguernn的功能和代码。 |
| 20/11/2018: | 端到端版本的图标和Dialoguernn已发布。 |
宇宙是此存储库中最佳性能模型,请访问下面的链接以比较不同的ERC数据集上的模型。
该存储库包含对话方法中几种情绪识别的实现,以及识别对话中情绪原因的算法:
与其他情感检测模型不同,这些技术考虑了党派和党派依赖性,以建模与情感识别相关的会话环境。所有这些技术的主要目的是为同理心对话的产生预算一个情感检测模型。
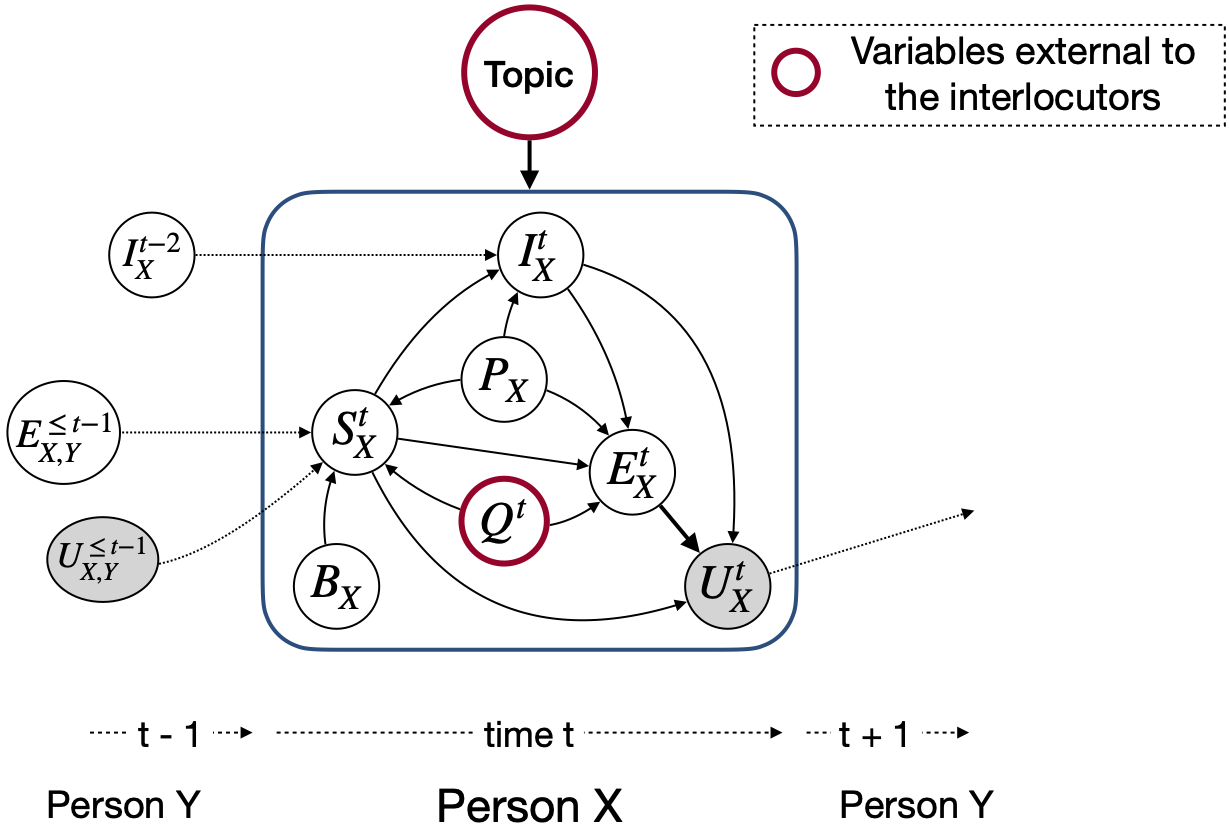
情绪识别对于善解人意和情感对话的产生非常有用 -
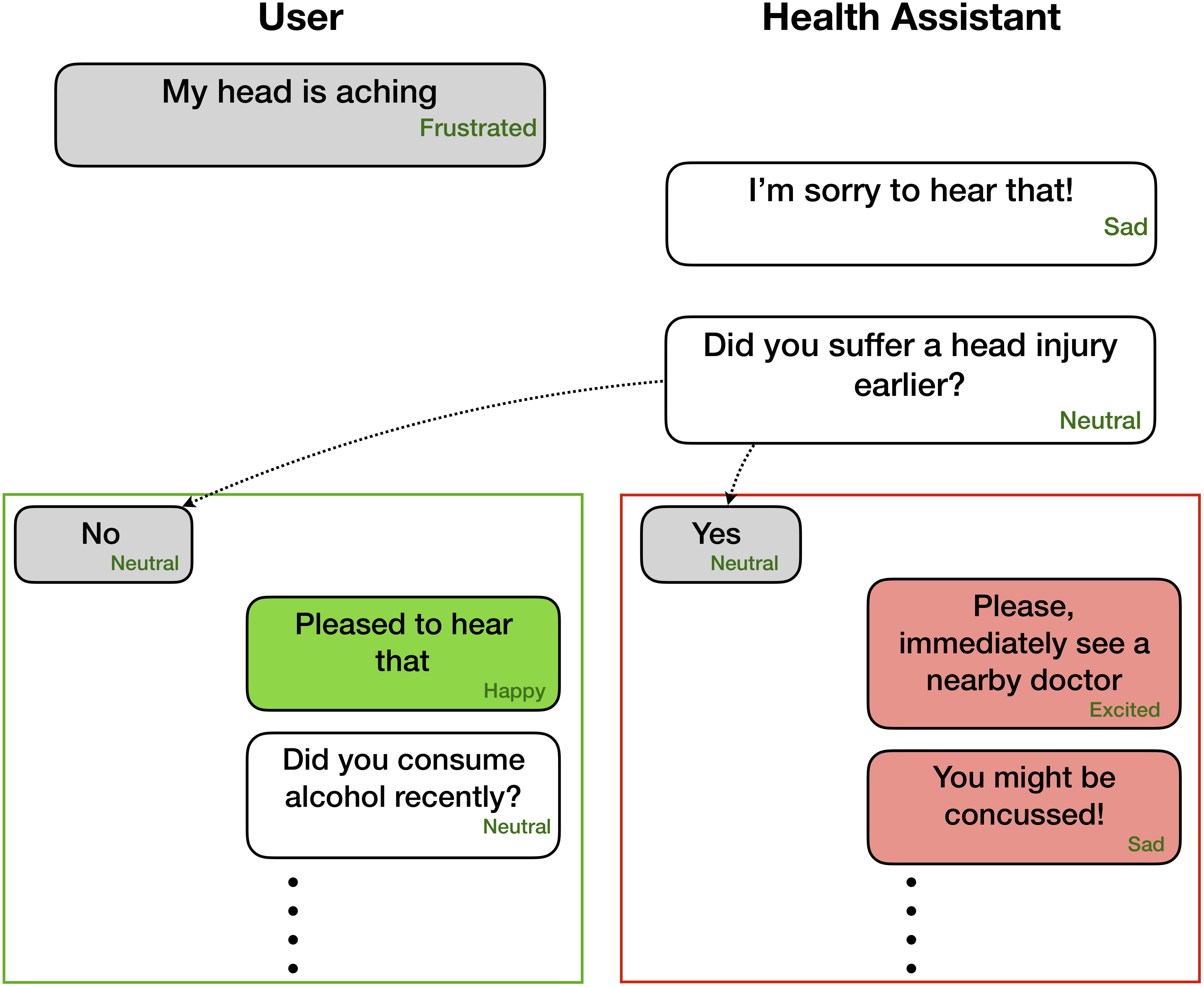
这些网络期望在对话中的每种话语中的情感/情感标签和扬声器信息
Party 1: I hate my girlfriend (angry)
Party 2: you got a girlfriend?! (surprise)
Party 1: yes (angry)
但是,可以将代码拟合以执行只有前面的话语而没有相应标签的任务,因为上下文和目标是仅标记当前/目标话语。例如,上下文是
Party 1: I hate my girlfriend
Party 2: you got a girlfriend?!
目标是
Party 1: yes (angry)
目标情绪生气的地方。此外,该代码也可以模制以以端到端的方式训练网络。我们很快将推动这些有用的更改。
| 方法 | Iemocap | DailyDialog | 融合 | emorynlp | |||
|---|---|---|---|---|---|---|---|
| w-avg f1 | 宏F1 | 微F1 | W-avg F1(3-CLS) | W-AVG F1(7-CLS) | W-avg F1(3-CLS) | W-AVG F1(7-CLS) | |
| 罗伯塔 | 54.55 | 48.20 | 55.16 | 72.12 | 62.02 | 55.28 | 37.29 |
| 罗伯塔对话 | 64.76 | 49.65 | 57.32 | 72.14 | 63.61 | 55.36 | 37.44 |
| 罗伯塔宇宙 | 65.28 | 51.05 | 58.48 | 73.20 | 65.21 | 56.51 | 38.11 |
宇宙通过使用常识知识在对话中解决了话语水平情感识别的任务。这是一个新框架,结合了常识性的不同要素,例如精神状态,事件和因果关系,并在他们基础上学习参加对话的对话者之间的互动。当前的最新方法通常在上下文传播,情感转移检测以及相关情绪类别之间遇到困难。通过学习不同的常识性表示,宇宙解决了这些挑战,并在四个不同的基准对话数据集上实现了新的最新结果,以识别情感。

首先在此处下载Roberta和Comet功能,并将其保留在COSMIC/erc-training中的适当目录中。然后,对四个数据集进行培训和评估应如下完成:
python train_iemocap.py --active-listenerpython train_dailydialog.py --active-listener --class-weight --residualpython train_meld.py --active-listener --attention simple --dropout 0.5 --rec_dropout 0.3 --lr 0.0001 --mode1 2 --classify emotion --mu 0 --l2 0.00003 --epochs 60python train_meld.py --active-listener --class-weight --residual --classify sentimentpython train_emorynlp.py --active-listener --class-weight --residualpython train_emorynlp.py --active-listener --class-weight --residual --classify sentiment如果您发现此代码对您的工作有用,请引用以下论文。
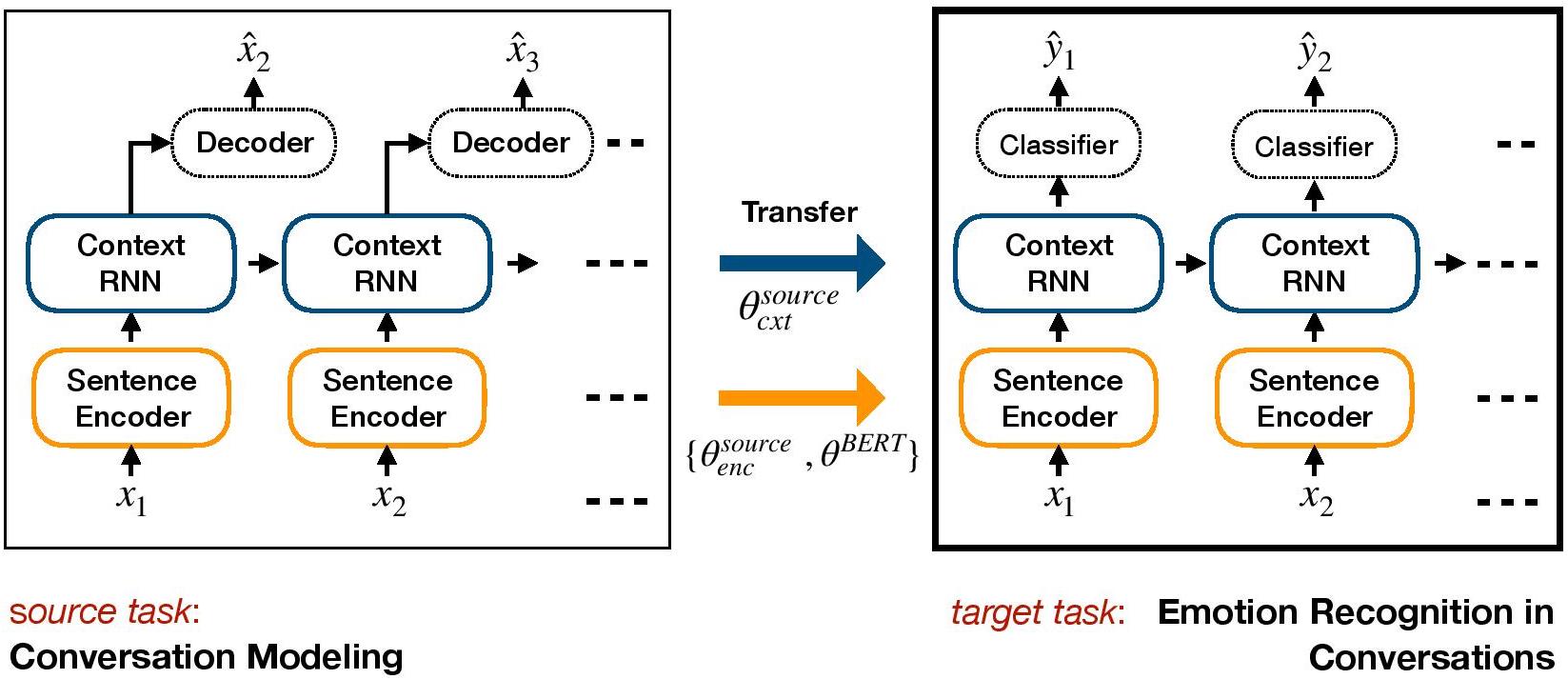
COSMIC: COmmonSense knowledge for eMotion Identification in Conversations. D. Ghosal, N. Majumder, A. Gelbukh, R. Mihalcea, & S. Poria. Findings of EMNLP 2020.TL-ERC是ERC的基于转移学习的框架。它可以预先培训生成对话模型,并将上下文级别的权重传输,这些权重包括情感知识到ERC的目标判别模型中。
使用Conda设置环境:
conda env create -f environment.yml
conda activate TL_ERC
cd TL_ERC
python setup.py下载数据集文件IEMocap,DailyDialog并将其存储在./datasets/中。
下载康奈尔和Ubuntu数据集上HRED的预./generative_weights/的重量
[可选]:要训练对话模型的新生成权重,请参阅https://github.com/ctr4si/a-hierarchical-latent-sonstructure-for-variational-conversation-modeling。
cd bert_modelpython train.py --load_checkpoint=../generative_weights/cornell_weights.pkl --data=iemocap 。cornell更改为ubuntu和iemocap ,以dailydialog其他数据集组合。load_checkpoint以避免初始化上下文权重。configs.pypython iemocap_preprocess.py 。同样适用于dailydialog 。如果您发现此代码对您的工作有用,请引用以下论文。
Conversational transfer learning for emotion recognition. Hazarika, D., Poria, S., Zimmermann, R., & Mihalcea, R. (2020). Information Fusion.对话GCN (对话图卷积网络)是基于图神经网络的ERC方法。我们利用对话者的自我和言论扬声器的依赖性来模拟情绪识别的对话环境。通过图表网络,对话核能解决了当前基于RNN的方法中存在的上下文传播问题。对话GCN自然适合多方对话。

注意:Pytorch几何形状大量使用了CUDA原子操作,并且是非确定性的来源。为了复制论文中报告的结果,我们建议使用以下执行命令。请注意,此脚本将在CPU中执行。我们使用以下命令遵守机器中的加权平均F1分数为64.67,而Iemocap数据集的Google合作制作中有64.44个。
python train_IEMOCAP.py --base-model 'LSTM' --graph-model --nodal-attention --dropout 0.4 --lr 0.0003 --batch-size 32 --class-weight --l2 0.0 --no-cuda如果您发现此代码对您的工作有用,请引用以下论文。
DialogueGCN: A Graph Convolutional Neural Network for Emotion Recognition in Conversation. D. Ghosal, N. Majumder, S. Poria, N. Chhaya, & A. Gelbukh. EMNLP-IJCNLP (2019), Hong Kong, China.Pytorch实施到“对话:对话中情感识别的图形卷积神经网络”。
您可以很容易地运行整个过程。以Iemocap语料库为例:
./scripts/iemocap.sh preprocess./scripts/iemocap.sh train| - | 数据集 | 加权F1 |
|---|---|---|
| 原来的 | Iemocap | 64.18% |
| 这个实现 | Iemocap | 64.10% |
Mian Zhang(Github:Mianzhang)
如果您发现此代码对您的工作有用,请引用以下论文。
DialogueGCN: A Graph Convolutional Neural Network for Emotion Recognition in Conversation. D. Ghosal, N. Majumder, S. Poria, N. Chhaya, & A. Gelbukh. EMNLP-IJCNLP (2019), Hong Kong, China.Dialoguernn基本上是一种自定义的复发性神经网络(RNN),它在即时的对话/对话中介绍了每个说话者,而同时对话的上下文进行了建模。该模型可以轻松地扩展到多方方案。同样,它可以用作循环训练的模型,用于产生同理心对话。
注意:代码中的默认设置(超参数和命令行参数)用于bidialoguernn+att。用户需要优化其他变体和更改的设置。 
请提取DialogueRNN_features.zip的内容。
python train_IEMOCAP.py <command-line arguments>python train_AVEC.py <command-line arguments>--no-cuda :不使用GPU--lr :学习率--l2 :L2正则重量--rec-dropout :recurrent辍学--dropout :辍学--batch-size :批量大小--epochs :时代的数量--class-weight :班级体重(不适用于AVEC)--active-listener :明确的Lisnener模式--attention :注意类型--tensorboard :启用张板日志--attribute :属性1至4(仅适用于AVEC; 1 = VAINCE,2 =激活/唤醒,3 =预期/期望,4 =功率)如果您发现此代码对您的工作有用,请引用以下论文。
DialogueRNN: An Attentive RNN for Emotion Detection in Conversations. N. Majumder, S. Poria, D. Hazarika, R. Mihalcea, E. Cambria, and G. Alexander. AAAI (2019), Honolulu, Hawaii, USA交互式对话记忆网络(ICON)是一个多模式的情感检测框架,从对话视频中提取多模式特征,并层次对 textit {self}和 textit {self textit {speacher}情感影响到全球记忆。这些记忆产生了上下文摘要,有助于预测话语视频的情感取向。
cd ICON
解压缩数据如下:
/ICON/IEMOCAP/data/ 。示例命令要实现这一目标: unzip {path_to_zip_file} -d ./IEMOCAP/训练图标模型:
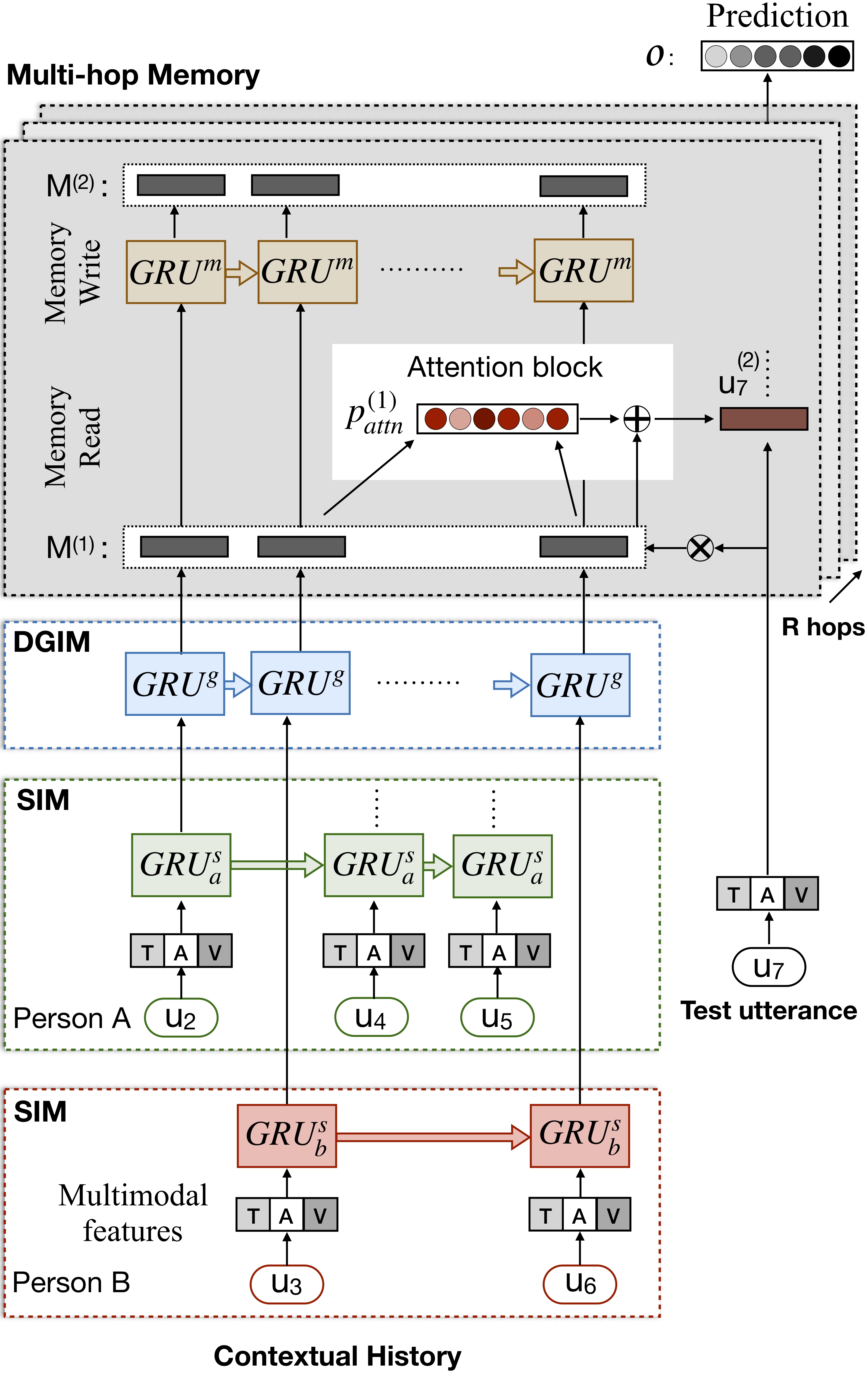
python train_iemocap.py for IemocapICON: Interactive Conversational Memory Networkfor Multimodal Emotion Detection. D. Hazarika, S. Poria, R. Mihalcea, E. Cambria, and R. Zimmermann. EMNLP (2018), Brussels, Belgium CMN是二元对话中情感检测的神经框架。它利用文本,音频和视觉方式的mutlimodal信号。它专门将特定于说话者的依赖项纳入其体系结构以进行上下文建模。然后使用多跳存储网络从此上下文中生成摘要。 
cd CMN
解压缩数据如下:
/CMN/IEMOCAP/data/ 。示例命令要实现这一目标: unzip {path_to_zip_file} -d ./IEMOCAP/训练图标模型:
python train_iemocap.py for Iemocap如果您发现此代码对您的工作有用,请引用以下论文。
Hazarika, D., Poria, S., Zadeh, A., Cambria, E., Morency, L.P. and Zimmermann, R., 2018. Conversational Memory Network for Emotion Recognition in Dyadic Dialogue Videos. In Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long Papers) (Vol. 1, pp. 2122-2132).BC-LSTM-PYTORCH是一个网络,用于使用上下文来检测对话中的话语。该模型是简单但有效的,它仅使用LSTM来建模话语之间的时间关系。在此存储库中,我们提供了Semeval 2019 Task 3的数据。我们使用并提供了Semeval 2019 Task 3发布的数据3-“情感识别”组织者。在此任务中,只提供了3个话语-Tustance1(user1),Tusterance2(user2),Tusterance3(user1)连续。任务是预测话语的情感标签3。尚未提供每种话语的情感标签。但是,如果您的数据包含每个话语的情感标签,则您仍然可以使用此代码并相应地调整它。因此,此代码对于Mosi,Mosei,Iemocap,AVEC,DailyDialogue等数据集仍然可以合理化。BC-LSTM不利用诸如CMN,ICON和DIALOGUERERNN之类的扬声器信息。
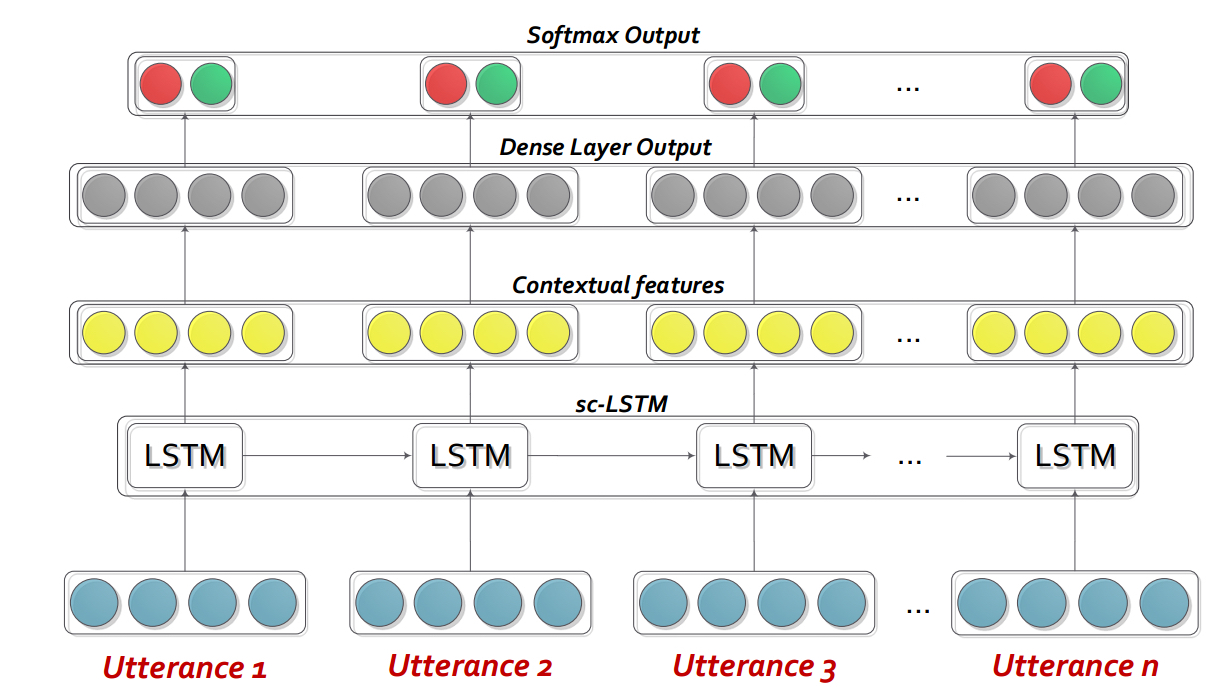
cd bc-LSTM-pytorch
训练BC-LSTM模型:
python train_IEMOCAP.py for Iemocap如果您发现此代码对您的工作有用,请引用以下论文。
Poria, S., Cambria, E., Hazarika, D., Majumder, N., Zadeh, A. and Morency, L.P., 2017. Context-dependent sentiment analysis in user-generated videos. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) (Vol. 1, pp. 873-883).KERAS实施BC-LSTM 。
cd bc-LSTM
训练BC-LSTM模型:
python baseline.py -config testBaseline.config如果您发现此代码对您的工作有用,请引用以下论文。
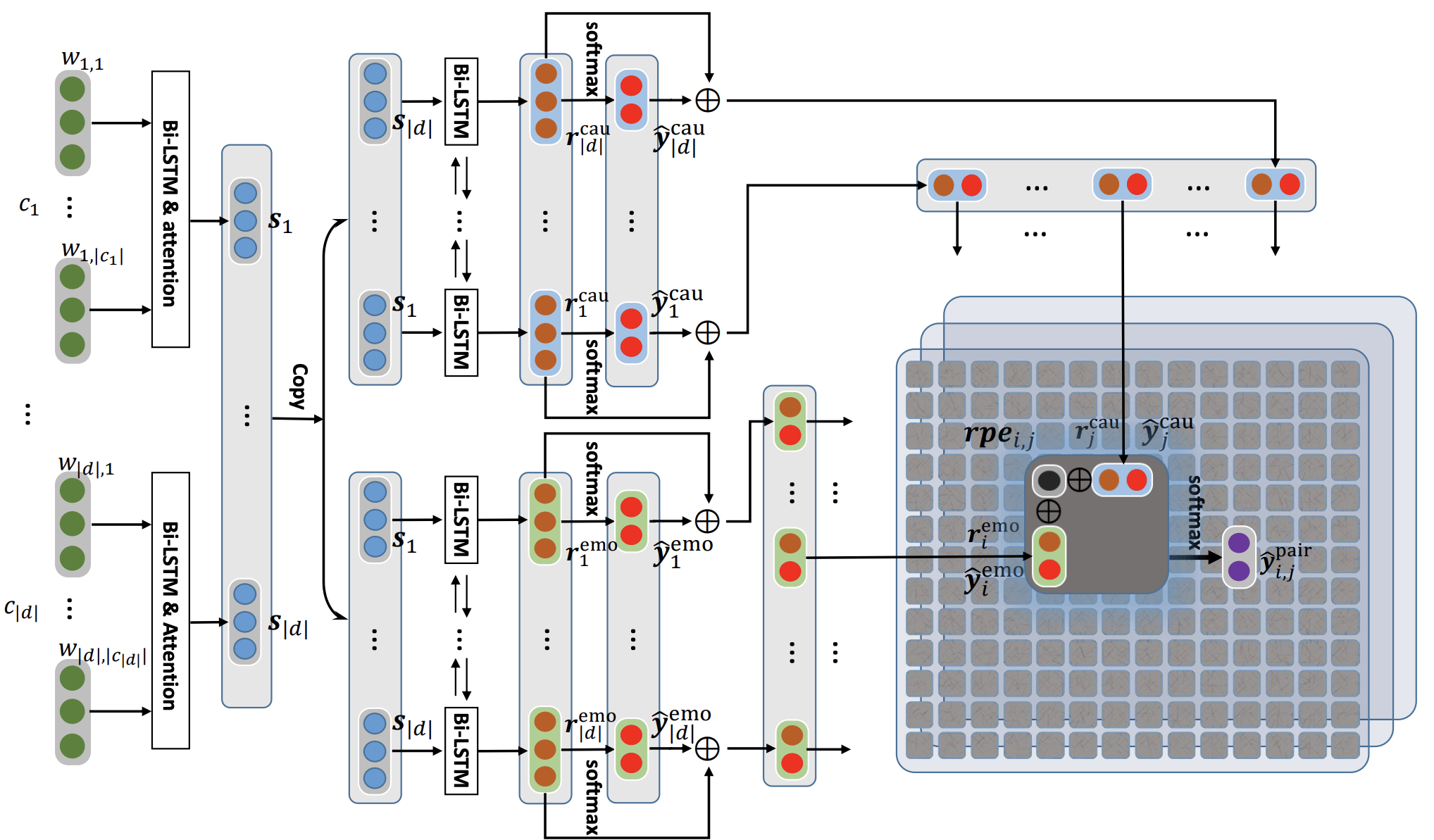
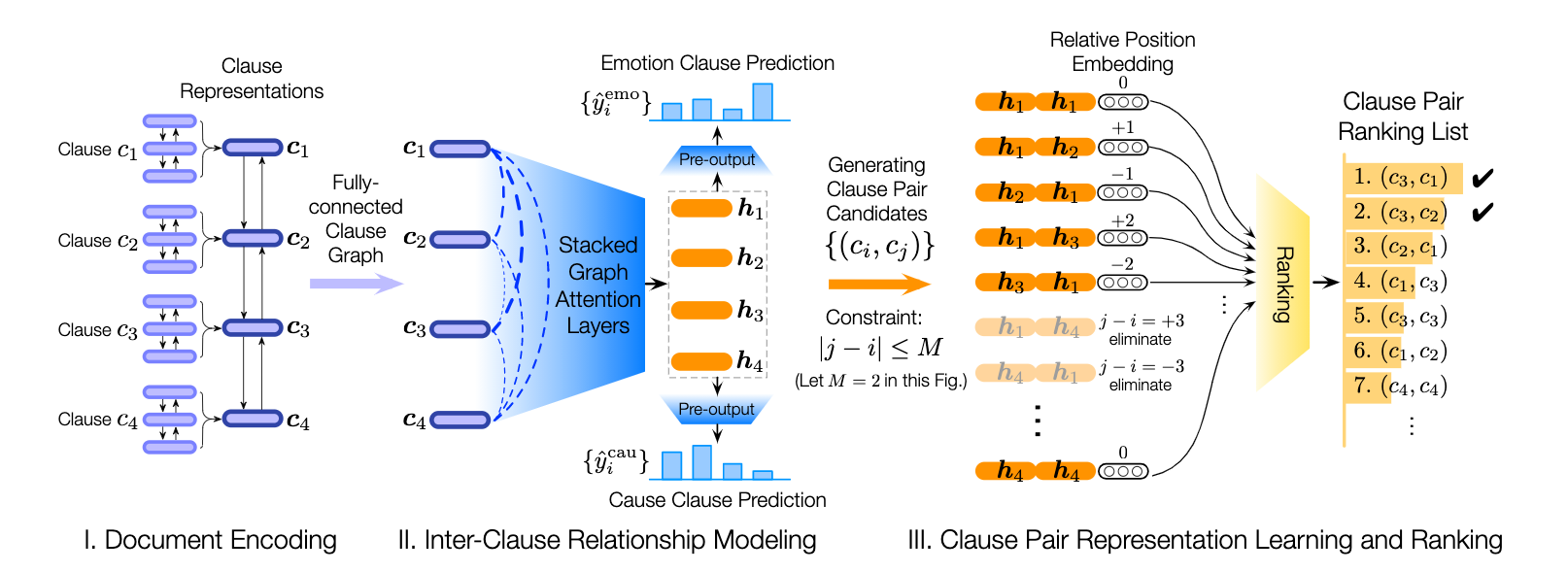
Poria, S., Cambria, E., Hazarika, D., Majumder, N., Zadeh, A. and Morency, L.P., 2017. Context-dependent sentiment analysis in user-generated videos. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) (Vol. 1, pp. 873-883).该存储库还包含不同体系结构的实现,以检测对话中的情感原因。

| 模型 | emo_f1 | POS_F1 | neg_f1 | macro_avg |
|---|---|---|---|---|
| ECPE-2D Cross_Rad (0变换层) | 52.76 | 52.39 | 95.86 | 73.62 |
| ECPE-2D窗口_受限 (1个变换层) | 70.48 | 48.80 | 93.85 | 71.32 |
| ECPE-2D Cross_Rad (2变换层) | 52.76 | 55.50 | 94.96 | 75.23 |
| ECPE-MLL | - | 48.48 | 94.68 | 71.58 |
| 排名情感原因 | - | 33.00 | 97.30 | 65.15 |
| 罗伯塔基地 | - | 64.28 | 88.74 | 76.51 |
| 罗伯塔·莱尔格(Roberta-Large) | - | 66.23 | 87.89 | 77.06 |
引用:如果您使用此代码,请引用以下论文。
引用:如果您使用此代码,请引用以下论文。
引用:如果您使用此代码,请引用以下论文。
原始Reccon论文中解释了罗伯塔和Spanbert Baselines。请参考。
引用:如果您使用此代码,请引用以下论文。


