db per tenant
1.0.0
此存儲庫包含一個用於AI驅動應用程序的可擴展體系結構的示例。從表面上看,這是一個AI應用程序,用戶可以上傳PDF並與他們聊天。但是,在引擎蓋下,每個用戶都會獲得一個專用的矢量數據庫實例(postgres with pgvector上的霓虹燈)。
您可以在https://db-per-tenant.up.railway.app/上查看實時版本
該應用是使用以下技術構建的:
您沒有將所有向量嵌入存儲在單個Postgres數據庫中,而是提供每個租戶(用戶,組織,工作區或任何其他需要隔離的實體)的租戶使用其自己的專用Postgres數據庫實例,您可以在其中存儲和查詢其嵌入。
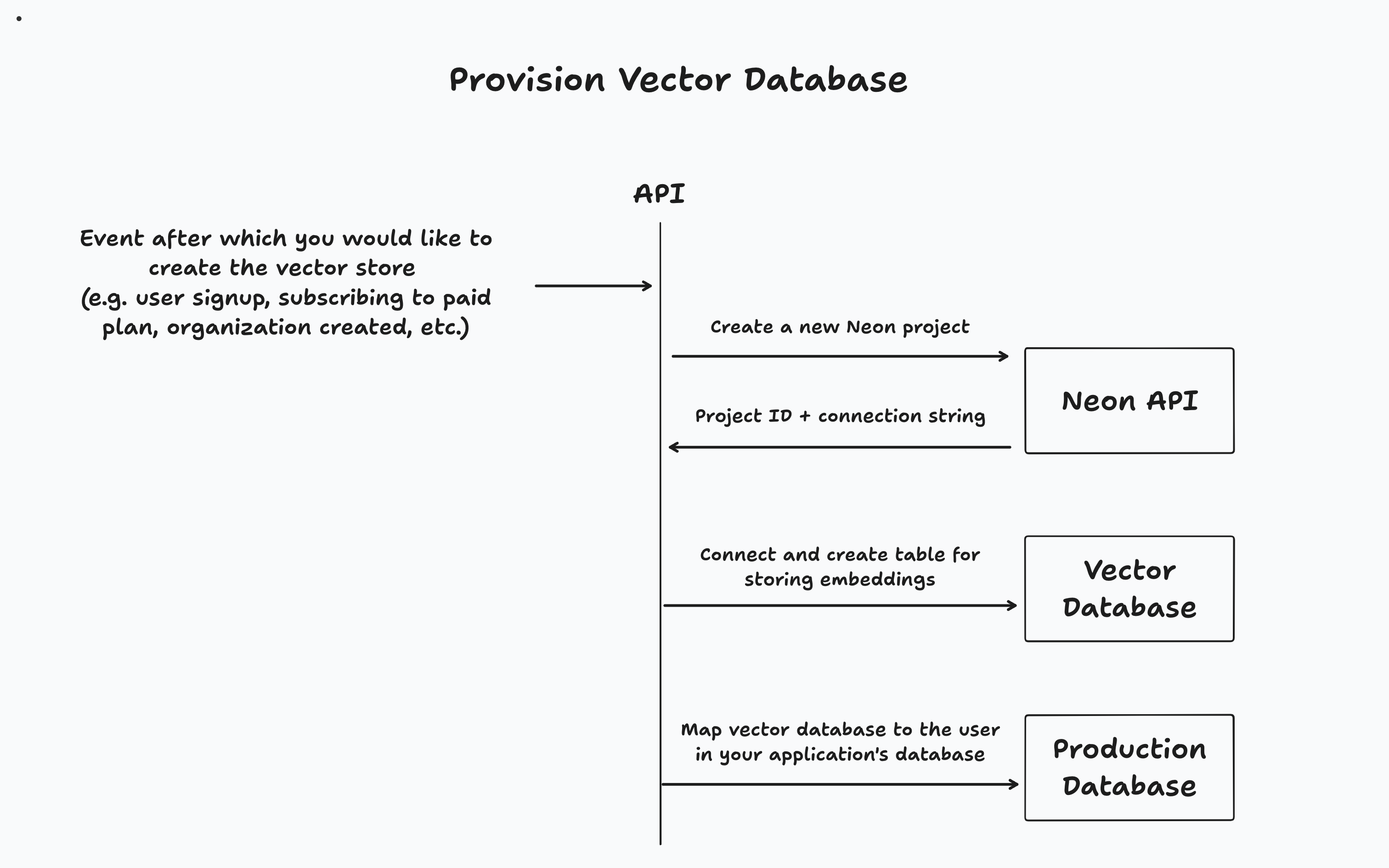
根據您的應用程序,您將在特定事件發生後(例如,用戶註冊,組織創建或升級到付費層)後提供矢量數據庫。然後,您將在應用程序的主數據庫中跟踪租戶及其關聯的矢量數據庫。
這種方法提供了幾個好處:
這是此存儲庫中的演示應用程序的數據庫體系結構圖:
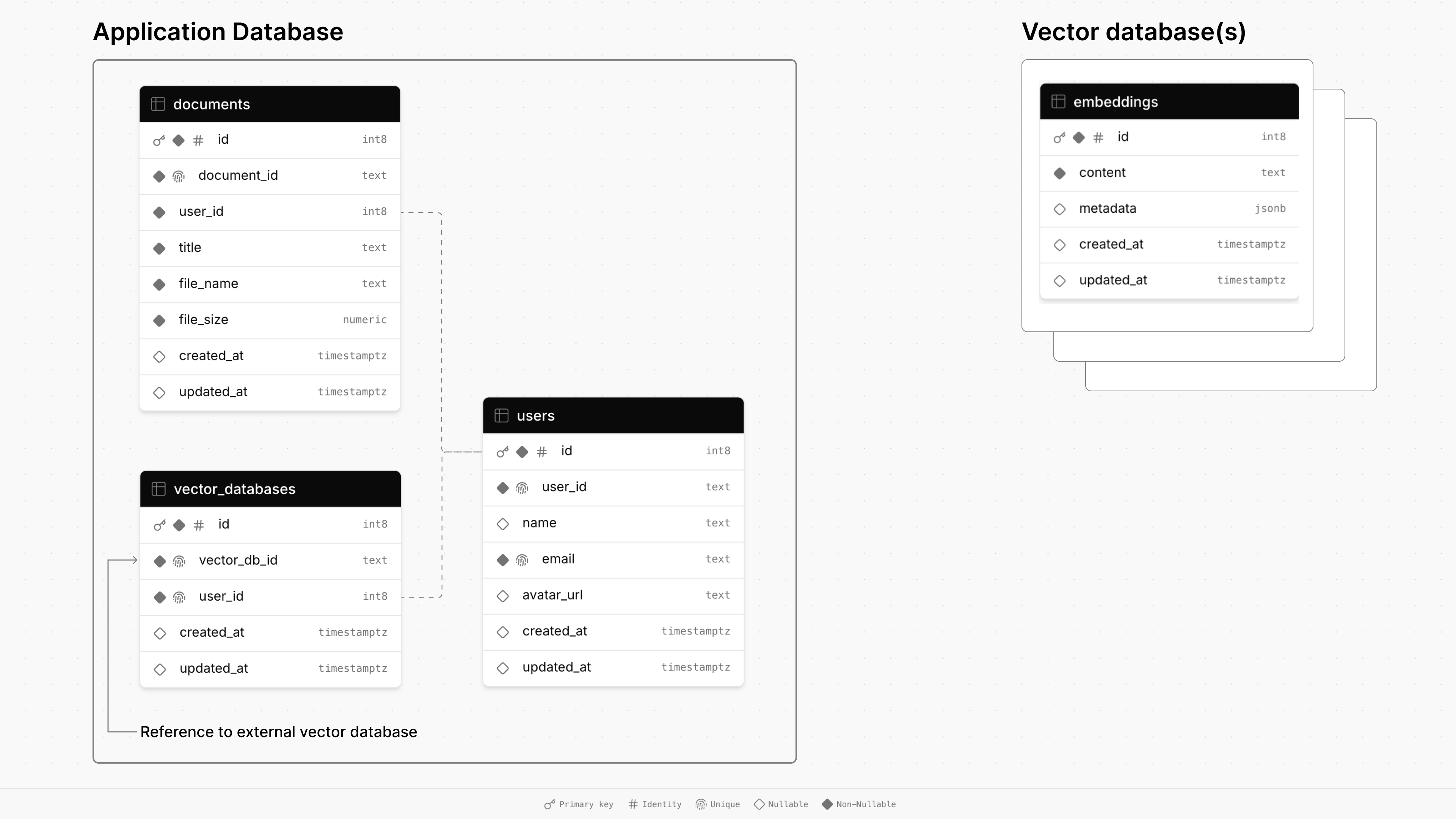
主應用程序的數據庫由三個表組成: documents , users和vector_databases 。
documents表存儲有關文件的信息,包括其標題,大小和時間戳,並通過外鍵鏈接到用戶。users表維護用戶配置文件,包括名稱,電子郵件和頭像URL。vector_databases表跟踪哪個向量數據庫屬於哪個用戶。然後,每個配置的矢量數據庫都有一個用於存儲文檔塊的embeddings表,以進行檢索 - 演示生成(RAG)。
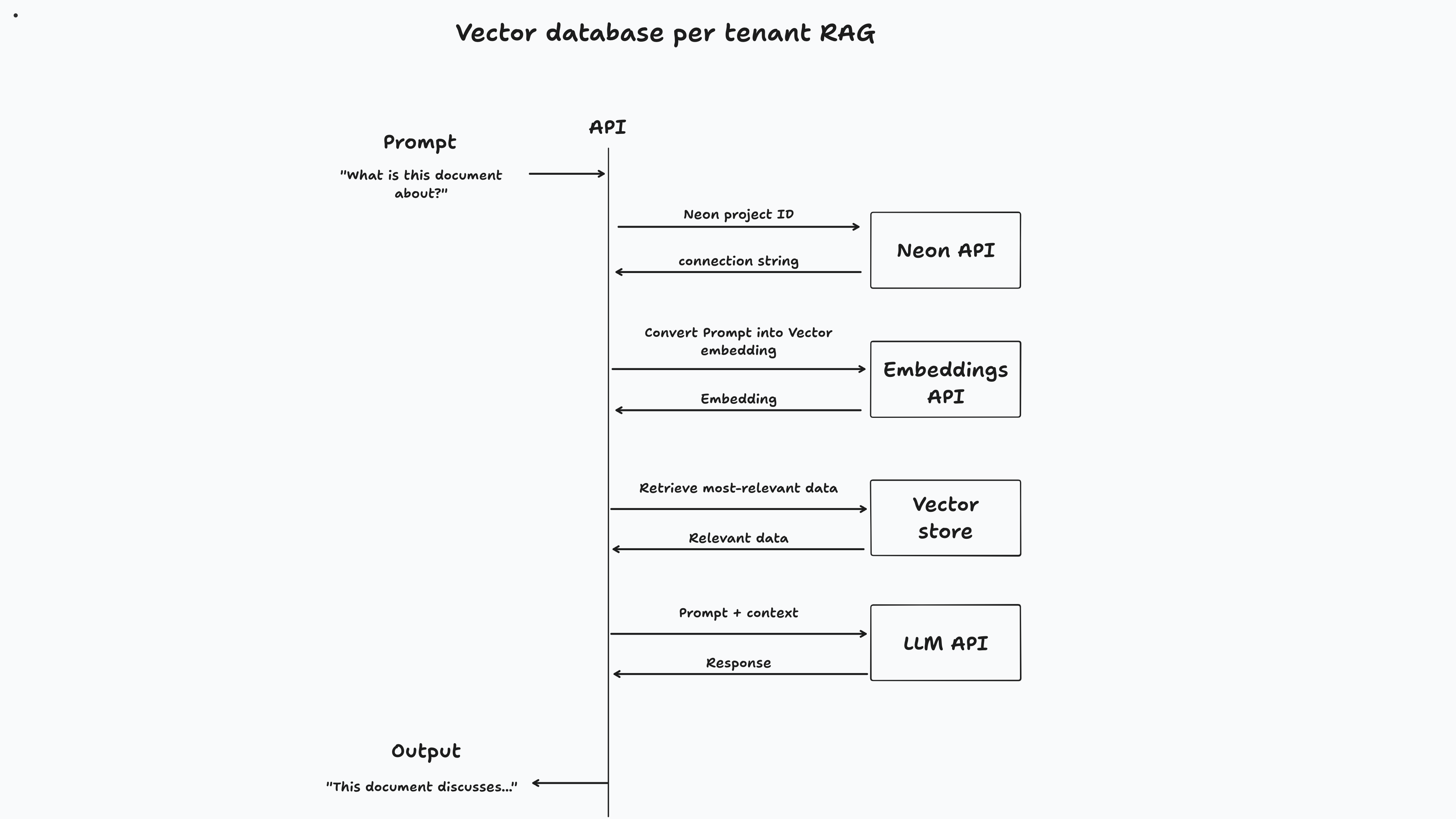
對於此應用程序,用戶登錄時將提供矢量數據庫。一旦上傳文檔,它就會塊並存儲在其專用矢量數據庫中。最後,一旦用戶與文檔聊天,矢量相似性搜索將在其數據庫中運行以檢索相關信息以回答其提示。
// Code from app/lib/auth.ts
authenticator . use (
new GoogleStrategy (
{
clientID : process . env . GOOGLE_CLIENT_ID ,
clientSecret : process . env . GOOGLE_CLIENT_SECRET ,
callbackURL : process . env . GOOGLE_CALLBACK_URL ,
} ,
async ( { profile } ) => {
const email = profile . emails [ 0 ] . value ;
try {
const userData = await db
. select ( {
user : users ,
vectorDatabase : vectorDatabases ,
} )
. from ( users )
. leftJoin ( vectorDatabases , eq ( users . id , vectorDatabases . userId ) )
. where ( eq ( users . email , email ) ) ;
if (
userData . length === 0 ||
! userData [ 0 ] . vectorDatabase ||
! userData [ 0 ] . user
) {
const { data , error } = await neonApiClient . POST ( "/projects" , {
body : {
project : { } ,
} ,
} ) ;
if ( error ) {
throw new Error ( `Failed to create Neon project, ${ error } ` ) ;
}
const vectorDbId = data ?. project . id ;
const vectorDbConnectionUri = data . connection_uris [ 0 ] ?. connection_uri ;
const sql = postgres ( vectorDbConnectionUri ) ;
await sql `CREATE EXTENSION IF NOT EXISTS vector;` ;
await migrate ( drizzle ( sql ) , { migrationsFolder : "./drizzle" } ) ;
const newUser = await db
. insert ( users )
. values ( {
email ,
name : profile . displayName ,
avatarUrl : profile . photos [ 0 ] . value ,
userId : generateId ( { object : "user" } ) ,
} )
. onConflictDoNothing ( )
. returning ( ) ;
await db
. insert ( vectorDatabases )
. values ( {
vectorDbId ,
userId : newUser [ 0 ] . id ,
} )
. returning ( ) ;
const result = {
... newUser [ 0 ] ,
vectorDbId ,
} ;
return result ;
}
return {
... userData [ 0 ] . user ,
vectorDbId : userData [ 0 ] . vectorDatabase . vectorDbId ,
} ;
} catch ( error ) {
console . error ( "User creation error:" , error ) ;
throw new Error ( getErrorMessage ( error ) ) ;
}
} ,
) ,
) ;
// Code from app/routes/api/document/chat
// Get the user's messages and the document ID from the request body.
const {
messages ,
documentId ,
} : {
messages : Message [ ] ;
documentId : string ;
} = await request . json ( ) ;
const { content : prompt } = messages [ messages . length - 1 ] ;
const { data , error } = await neonApiClient . GET (
"/projects/{project_id}/connection_uri" ,
{
params : {
path : {
project_id : user . vectorDbId ,
} ,
query : {
role_name : "neondb_owner" ,
database_name : "neondb" ,
} ,
} ,
} ,
) ;
if ( error ) {
return json ( {
error : error ,
} ) ;
}
const embeddings = new OpenAIEmbeddings ( {
apiKey : process . env . OPENAI_API_KEY ,
dimensions : 1536 ,
model : "text-embedding-3-small" ,
} ) ;
const vectorStore = await NeonPostgres . initialize ( embeddings , {
connectionString : data . uri ,
tableName : "embeddings" ,
columns : {
contentColumnName : "content" ,
metadataColumnName : "metadata" ,
vectorColumnName : "embedding" ,
} ,
} ) ;
const result = await vectorStore . similaritySearch ( prompt , 2 , {
documentId ,
} ) ;
const model = new ChatOpenAI ( {
apiKey : process . env . OPENAI_API_KEY ,
model : "gpt-4o-mini" ,
temperature : 0 ,
} ) ;
const allMessages = messages . map ( ( message ) =>
message . role === "user"
? new HumanMessage ( message . content )
: new AIMessage ( message . content ) ,
) ;
const systemMessage = new SystemMessage (
`You are a helpful assistant, here's some extra additional context that you can use to answer questions. Only use this information if it's relevant:
${ result . map ( ( r ) => r . pageContent ) . join ( " " ) } ` ,
) ;
allMessages . push ( systemMessage ) ;
const stream = await model . stream ( allMessages ) ;
return LangChainAdapter . toDataStreamResponse ( stream ) ;儘管這種方法是有益的,但實施也可能具有挑戰性。您需要管理每個數據庫的生命週期,包括配置,擴展和脫機。幸運的是,霓虹燈上的Postgres的設置不同:
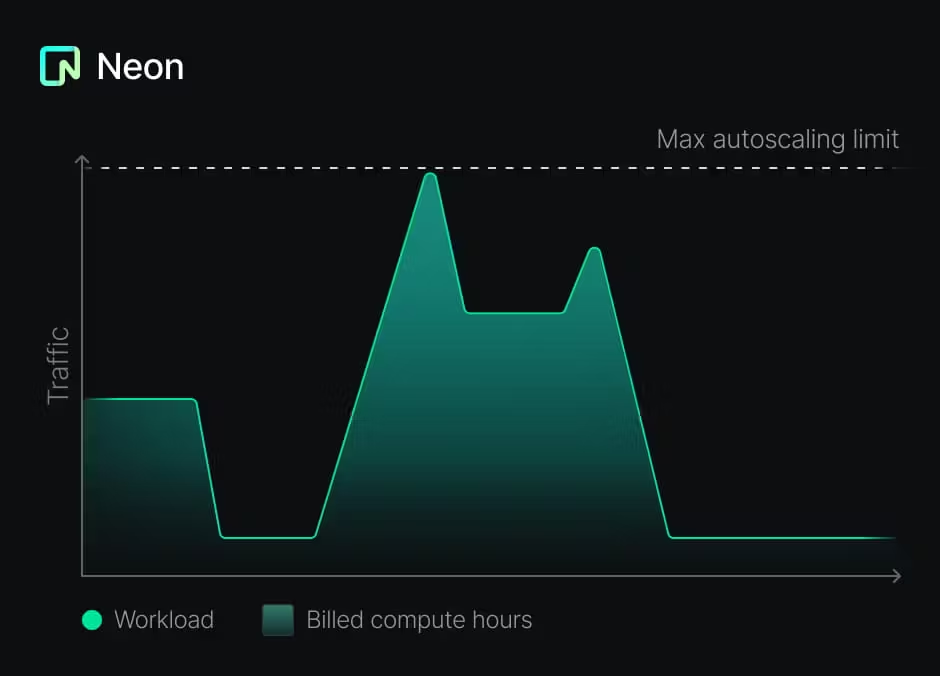
這使得為每個租戶創建數據庫的建議模式不僅可能,而且具有成本效益。
當您有每個租戶的數據庫時,您需要管理每個數據庫的遷移。該項目使用毛毛雨:
/app/lib/vector-db/schema.ts中定義的。bun run vector-db:generate並存儲在/app/lib/vector-db/migrations中來生成遷移。bun run vector-db:migrate 。此命令將運行一個連接到每個租戶數據庫並應用遷移的腳本。重要的是要注意,您想引入的任何模式更改都應該向後兼容。否則,您需要以不同的方式處理模式遷移。
儘管此模式可用於構建AI應用程序,但您只需使用它即可為每個租戶提供自己的數據庫。您也可以在主應用程序的數據庫中使用Postgres以外的數據庫(例如MySQL,MongoDB,MSSQL Server等)。
如果您有任何疑問,請隨時與霓虹燈不和諧聯繫或與霓虹燈銷售團隊聯繫。我們很想听聽您的來信。


