db per tenant
1.0.0
Ce dépôt contient un exemple d'architecture évolutive pour les applications alimentées par l'IA. En surface, c'est une application AI où les utilisateurs peuvent télécharger des PDF et discuter avec eux. Cependant, sous le capot, chaque utilisateur obtient une instance de base de données vectorielle dédiée (Postgres sur Neon avec PGVector).
Vous pouvez consulter la version en direct sur https://db-per-tenant.up.railway.app/
L'application est construite en utilisant les technologies suivantes:
Plutôt que d'avoir toutes les intégres vectoriels stockés dans une seule base de données Postgres, vous fournissez à chaque locataire (un utilisateur, une organisation, un espace de travail ou toute autre entité nécessitant un isolement) avec sa propre instance de base de données Postgres dédiée où vous pouvez stocker et interroger ses incorporations.
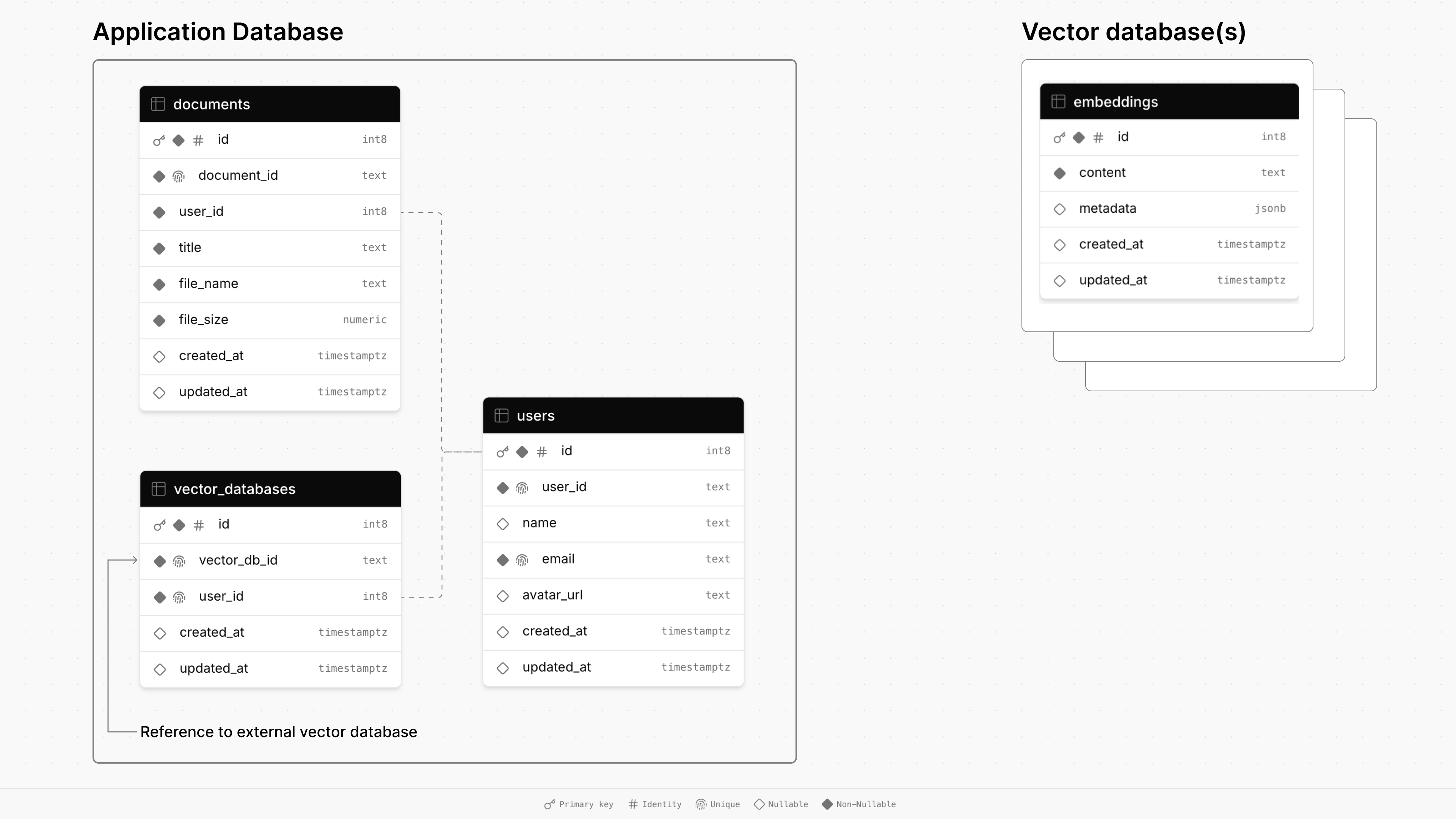
Selon votre application, vous provisionnerez une base de données vectorielle après un événement spécifique (par exemple, l'inscription des utilisateurs, la création d'organisation ou la mise à niveau vers un niveau payant). Vous suivrez ensuite les locataires et leurs bases de données vectorielles associées dans la base de données principale de votre application.
Cette approche offre plusieurs avantages:
Voici le diagramme d'architecture de la base de données de l'application de démonstration qui se trouve dans ce dépôt:
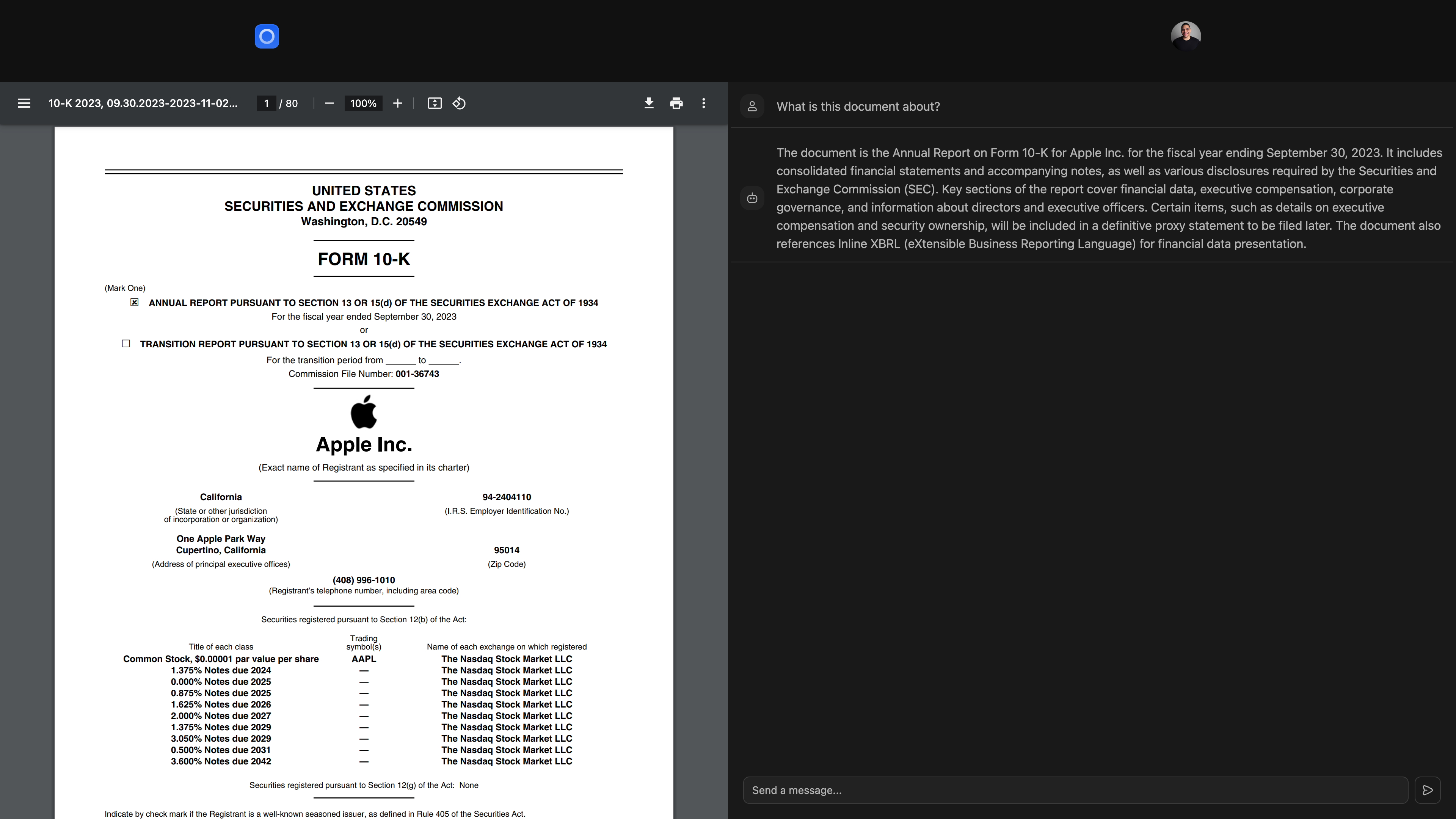
La base de données de l'application principale se compose de trois tableaux: documents , users et vector_databases .
documents tablettent des informations sur les fichiers, y compris leurs titres, tailles et horodatages, et est lié aux utilisateurs via une clé étrangère.users maintient les profils d'utilisateurs, y compris les noms, les e-mails et les URL d'avatar.vector_databases suit quelle base de données Vector appartient à quel utilisateur. Ensuite, chaque base de données vectorielle qui est provisionnée a une table embeddings pour stocker des morceaux de document pour la génération (RAG) de la récupération.
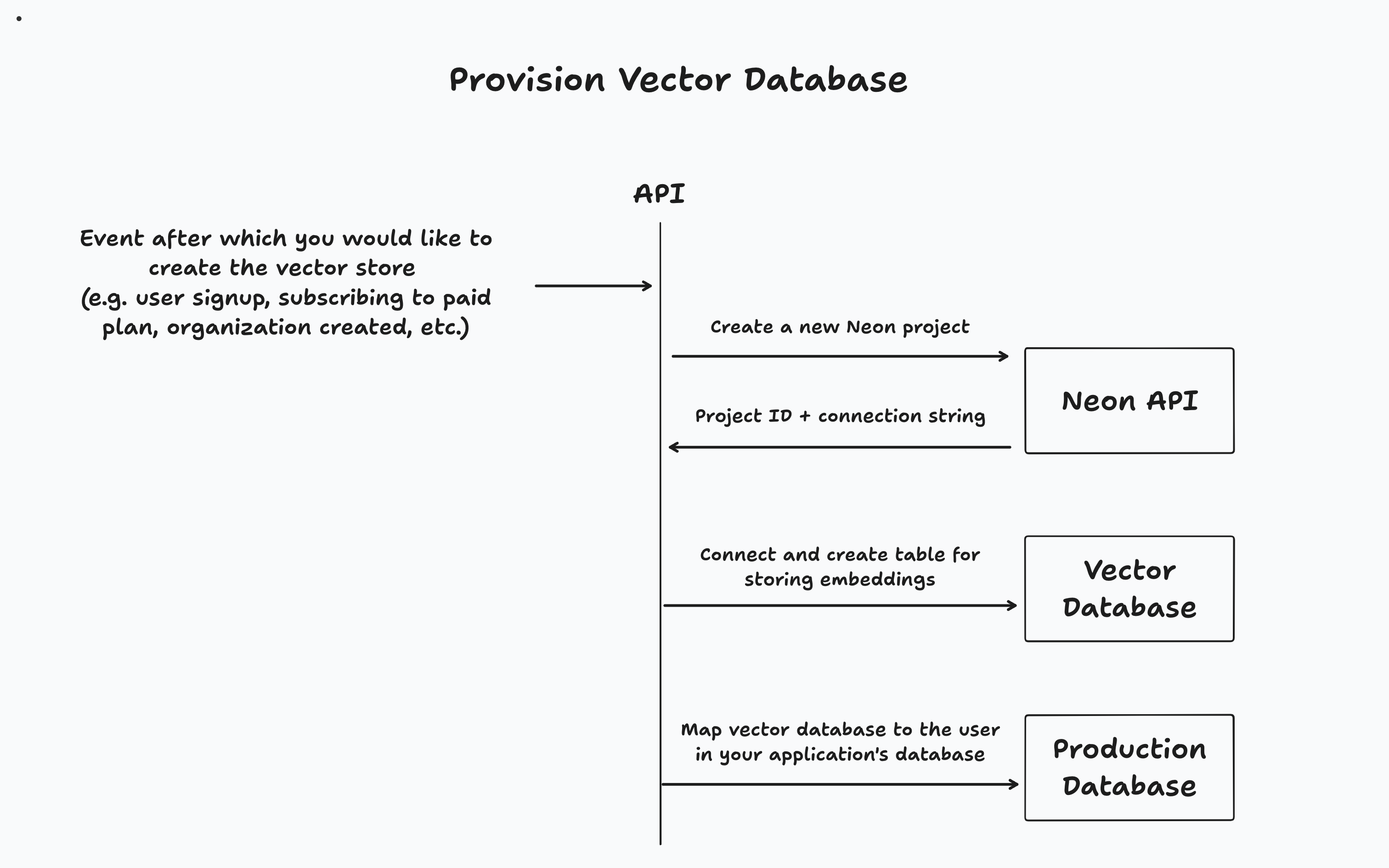
Pour cette application, les bases de données vectorielles sont provisionnées lorsqu'un utilisateur s'inscrit. Une fois qu'ils ont téléchargé un document, il est enraciné et stocké dans leur base de données vectorielle dédiée. Enfin, une fois que l'utilisateur discute avec son document, la recherche de similitude vectorielle s'exécute contre sa base de données pour récupérer les informations pertinentes pour répondre à leur invite.
// Code from app/lib/auth.ts
authenticator . use (
new GoogleStrategy (
{
clientID : process . env . GOOGLE_CLIENT_ID ,
clientSecret : process . env . GOOGLE_CLIENT_SECRET ,
callbackURL : process . env . GOOGLE_CALLBACK_URL ,
} ,
async ( { profile } ) => {
const email = profile . emails [ 0 ] . value ;
try {
const userData = await db
. select ( {
user : users ,
vectorDatabase : vectorDatabases ,
} )
. from ( users )
. leftJoin ( vectorDatabases , eq ( users . id , vectorDatabases . userId ) )
. where ( eq ( users . email , email ) ) ;
if (
userData . length === 0 ||
! userData [ 0 ] . vectorDatabase ||
! userData [ 0 ] . user
) {
const { data , error } = await neonApiClient . POST ( "/projects" , {
body : {
project : { } ,
} ,
} ) ;
if ( error ) {
throw new Error ( `Failed to create Neon project, ${ error } ` ) ;
}
const vectorDbId = data ?. project . id ;
const vectorDbConnectionUri = data . connection_uris [ 0 ] ?. connection_uri ;
const sql = postgres ( vectorDbConnectionUri ) ;
await sql `CREATE EXTENSION IF NOT EXISTS vector;` ;
await migrate ( drizzle ( sql ) , { migrationsFolder : "./drizzle" } ) ;
const newUser = await db
. insert ( users )
. values ( {
email ,
name : profile . displayName ,
avatarUrl : profile . photos [ 0 ] . value ,
userId : generateId ( { object : "user" } ) ,
} )
. onConflictDoNothing ( )
. returning ( ) ;
await db
. insert ( vectorDatabases )
. values ( {
vectorDbId ,
userId : newUser [ 0 ] . id ,
} )
. returning ( ) ;
const result = {
... newUser [ 0 ] ,
vectorDbId ,
} ;
return result ;
}
return {
... userData [ 0 ] . user ,
vectorDbId : userData [ 0 ] . vectorDatabase . vectorDbId ,
} ;
} catch ( error ) {
console . error ( "User creation error:" , error ) ;
throw new Error ( getErrorMessage ( error ) ) ;
}
} ,
) ,
) ;
// Code from app/routes/api/document/chat
// Get the user's messages and the document ID from the request body.
const {
messages ,
documentId ,
} : {
messages : Message [ ] ;
documentId : string ;
} = await request . json ( ) ;
const { content : prompt } = messages [ messages . length - 1 ] ;
const { data , error } = await neonApiClient . GET (
"/projects/{project_id}/connection_uri" ,
{
params : {
path : {
project_id : user . vectorDbId ,
} ,
query : {
role_name : "neondb_owner" ,
database_name : "neondb" ,
} ,
} ,
} ,
) ;
if ( error ) {
return json ( {
error : error ,
} ) ;
}
const embeddings = new OpenAIEmbeddings ( {
apiKey : process . env . OPENAI_API_KEY ,
dimensions : 1536 ,
model : "text-embedding-3-small" ,
} ) ;
const vectorStore = await NeonPostgres . initialize ( embeddings , {
connectionString : data . uri ,
tableName : "embeddings" ,
columns : {
contentColumnName : "content" ,
metadataColumnName : "metadata" ,
vectorColumnName : "embedding" ,
} ,
} ) ;
const result = await vectorStore . similaritySearch ( prompt , 2 , {
documentId ,
} ) ;
const model = new ChatOpenAI ( {
apiKey : process . env . OPENAI_API_KEY ,
model : "gpt-4o-mini" ,
temperature : 0 ,
} ) ;
const allMessages = messages . map ( ( message ) =>
message . role === "user"
? new HumanMessage ( message . content )
: new AIMessage ( message . content ) ,
) ;
const systemMessage = new SystemMessage (
`You are a helpful assistant, here's some extra additional context that you can use to answer questions. Only use this information if it's relevant:
${ result . map ( ( r ) => r . pageContent ) . join ( " " ) } ` ,
) ;
allMessages . push ( systemMessage ) ;
const stream = await model . stream ( allMessages ) ;
return LangChainAdapter . toDataStreamResponse ( stream ) ;Bien que cette approche soit bénéfique, elle peut également être difficile à mettre en œuvre. Vous devez gérer le cycle de vie de chaque base de données, y compris l'approvisionnement, la mise à l'échelle et le département. Heureusement, Postgres sur néon est mis en place différemment:
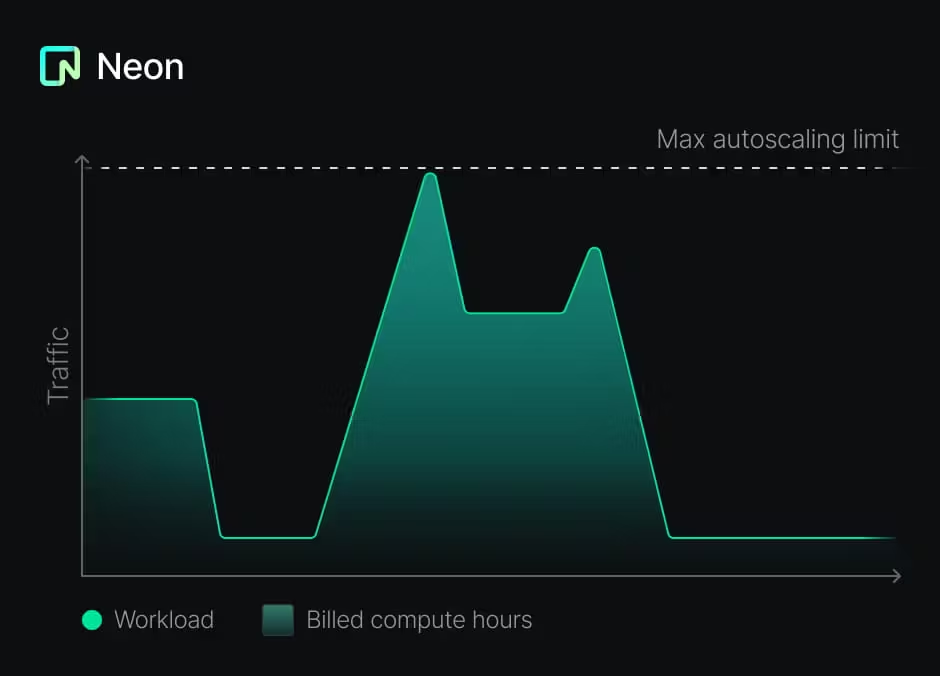
Cela rend le modèle proposé de création d'une base de données par locataire non seulement possible mais également rentable.
Lorsque vous avez une base de données par locataire, vous devez gérer les migrations pour chaque base de données. Ce projet utilise du filet:
/app/lib/vector-db/schema.ts en utilisant TypeScript.bun run vector-db:generate et stocké dans /app/lib/vector-db/migrations .bun run vector-db:migrate . Cette commande exécutera un script qui se connecte à la base de données de chaque locataire et applique les migrations.Il est important de noter que les changements de schéma que vous souhaitez introduire devraient être compatibles en arrière. Sinon, vous devrez gérer différemment les migrations de schéma.
Bien que ce modèle soit utile pour créer des applications d'IA, vous pouvez simplement l'utiliser pour fournir à chaque locataire sa propre base de données. Vous pouvez également utiliser une base de données autre que Postgres pour la base de données de votre application principale (par exemple, MySQL, MongoDB, MSSQL Server, etc.).
Si vous avez des questions, n'hésitez pas à vous contacter dans la discorde Neon ou à contacter l'équipe de vente au néon. Nous serions ravis de vous entendre.


