db per tenant
1.0.0
이 repo에는 AI 기반 애플리케이션을위한 확장 가능한 아키텍처의 예가 포함되어 있습니다. 표면적으로는 사용자가 PDF를 업로드하고 채팅 할 수있는 AI 앱입니다. 그러나 후드 아래에서 각 사용자는 전용 벡터 데이터베이스 인스턴스 (PGVECTOR를 사용한 NEON의 Postgres)를받습니다.
https://db-per-tenant.up.railway.app/에서 라이브 버전을 확인할 수 있습니다.
이 앱은 다음 기술을 사용하여 구축됩니다.
모든 벡터 임베드가 단일 우편물 데이터베이스에 저장되는 대신 각 테넌트 (사용자, 조직, 작업 영역 또는 격리가 필요한 다른 엔터티)에 자체 전용 Postgres 데이터베이스 인스턴스를 제공 할 수있는 전용 Postgres 데이터베이스 인스턴스를 제공합니다.
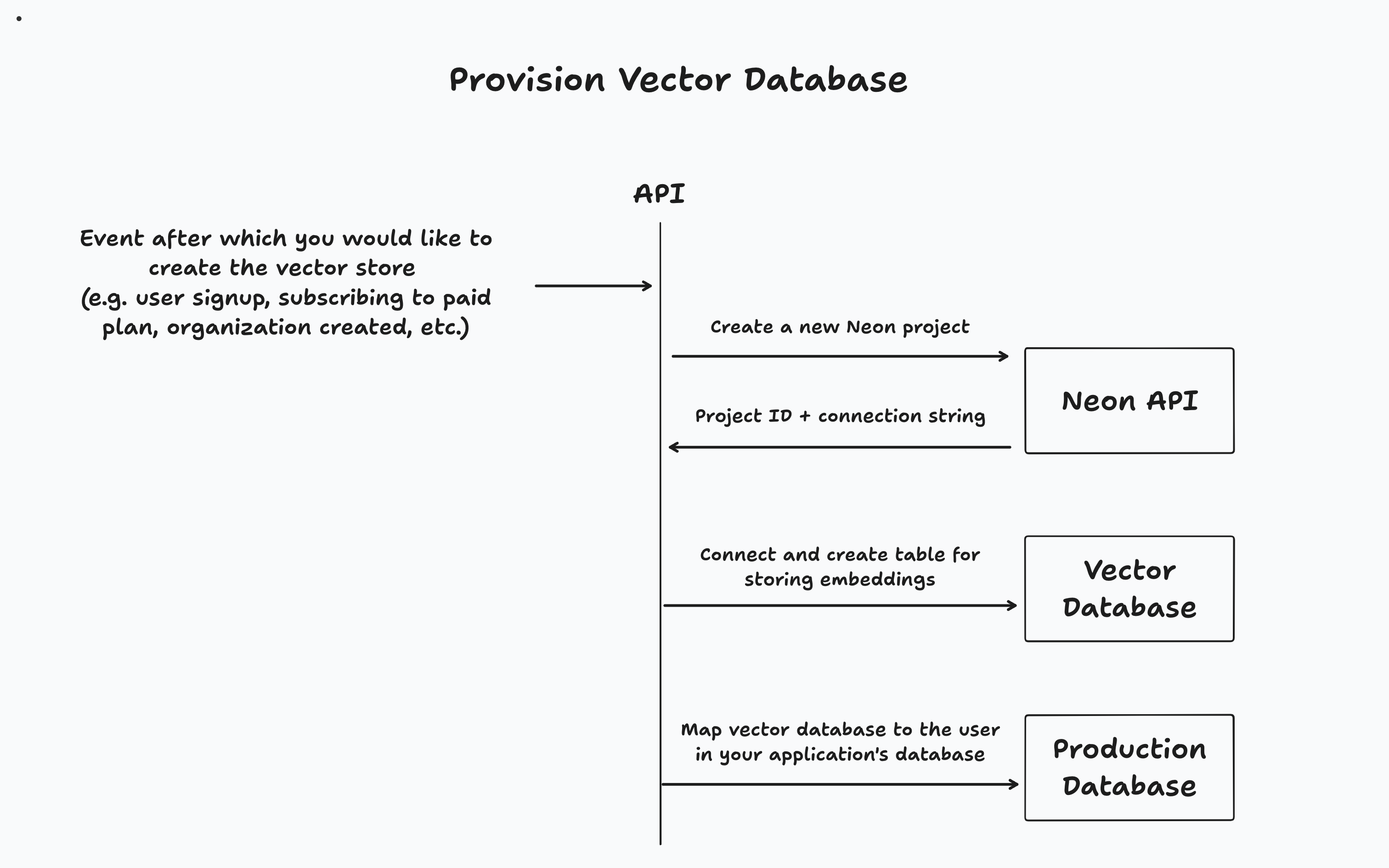
응용 프로그램에 따라 특정 이벤트 (예 : 사용자 가입, 조직 작성 또는 유료 계층으로의 업그레이드) 후 벡터 데이터베이스를 제공합니다. 그런 다음 응용 프로그램의 기본 데이터베이스에서 임차인과 관련 벡터 데이터베이스를 추적합니다.
이 접근법은 몇 가지 이점을 제공합니다.
다음은이 repo에있는 데모 앱의 데이터베이스 아키텍처 다이어그램입니다.
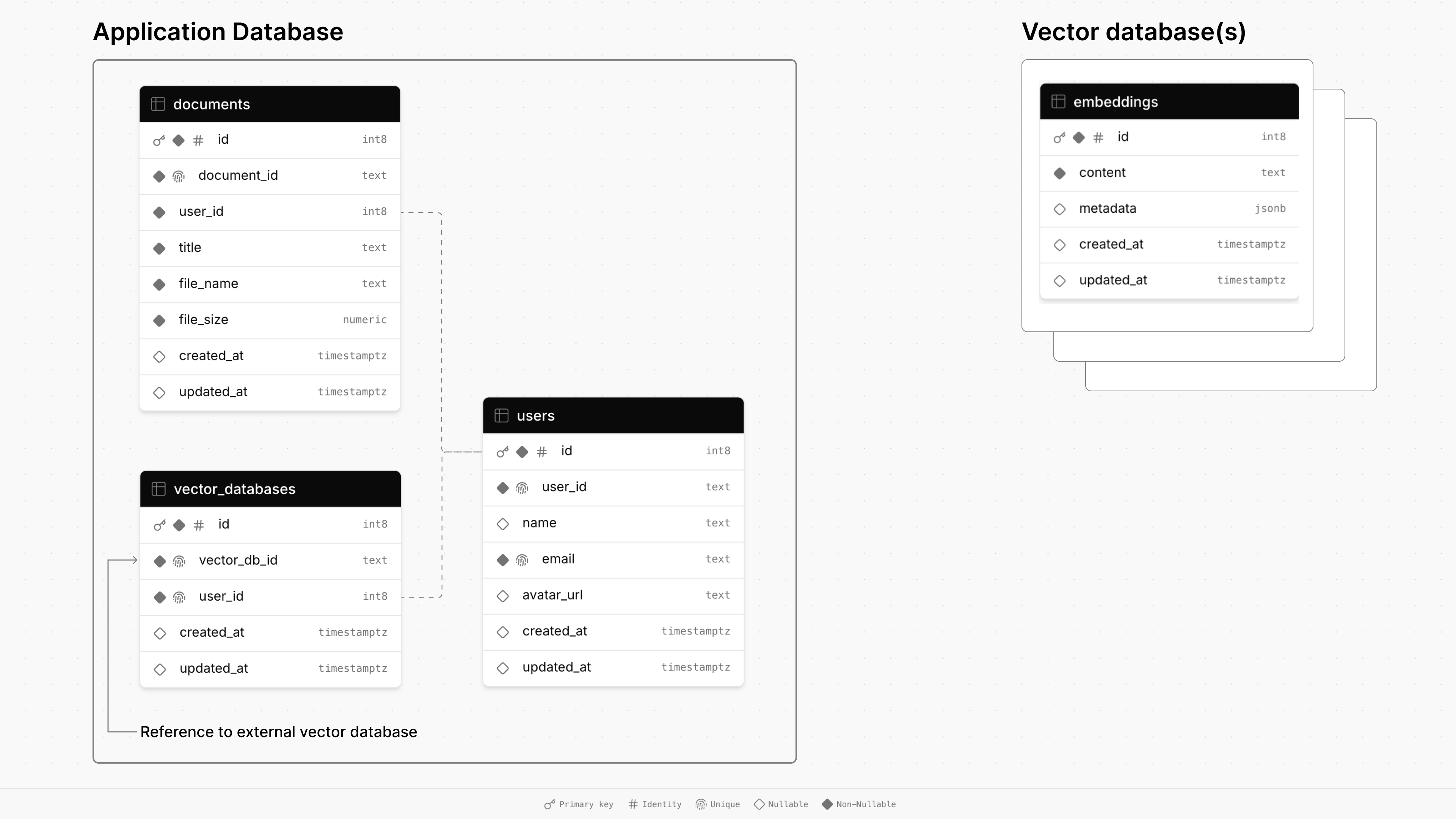
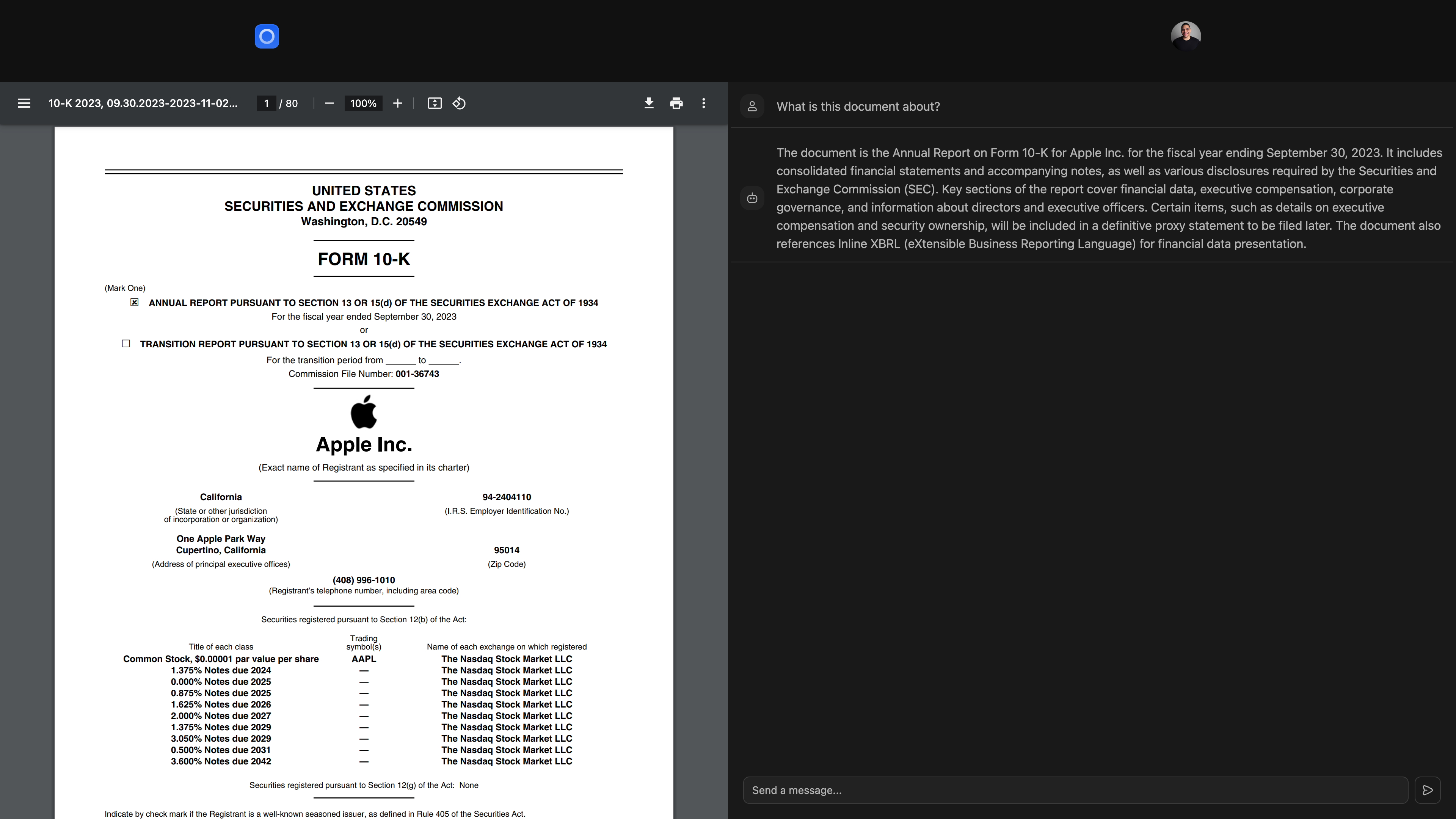
기본 응용 프로그램의 데이터베이스는 documents , users 및 vector_databases 의 세 가지 테이블로 구성됩니다.
documents 테이블은 제목, 크기 및 타임 스탬프를 포함하여 파일에 대한 정보를 저장하며 외국 키를 통해 사용자에게 연결됩니다.users 테이블은 이름, 이메일 및 아바타 URL을 포함한 사용자 프로필을 유지합니다.vector_databases 테이블은 어떤 벡터 데이터베이스가 어떤 사용자에 속하는지 추적합니다. 그런 다음 프로비저닝을받는 각 벡터 데이터베이스에는 검색 된 생성 생성 (RAG)을위한 문서 청크를 저장하기위한 embeddings 테이블이 있습니다.
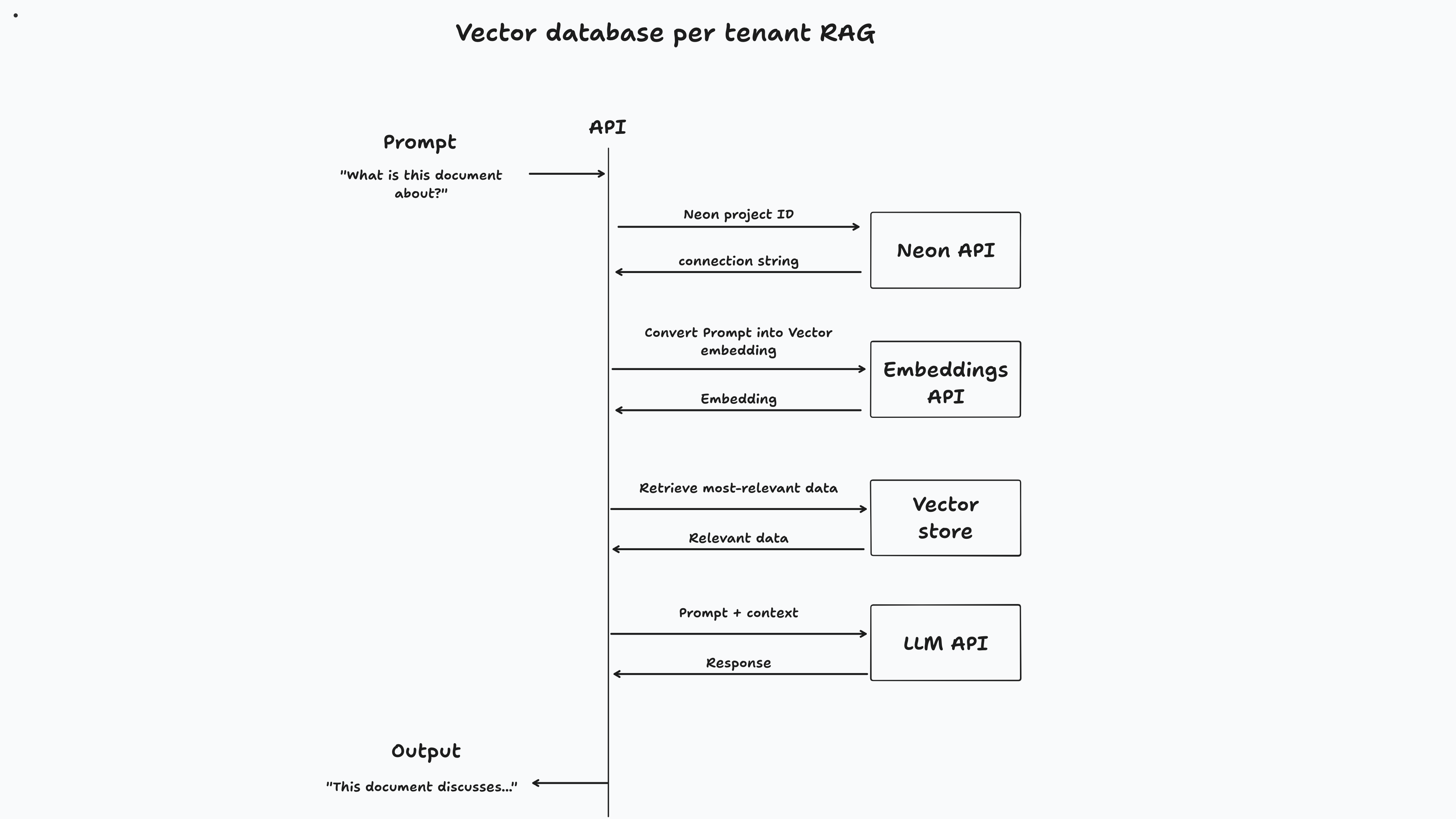
이 앱의 경우 벡터 데이터베이스는 사용자가 가입 할 때 프로비저닝됩니다. 문서를 업로드하면 전용 벡터 데이터베이스에 청크를하고 저장됩니다. 마지막으로, 사용자가 문서와 채팅하면 벡터 유사성 검색은 데이터베이스에 대해 실행되어 관련 정보를 검색하여 프롬프트에 답변합니다.
// Code from app/lib/auth.ts
authenticator . use (
new GoogleStrategy (
{
clientID : process . env . GOOGLE_CLIENT_ID ,
clientSecret : process . env . GOOGLE_CLIENT_SECRET ,
callbackURL : process . env . GOOGLE_CALLBACK_URL ,
} ,
async ( { profile } ) => {
const email = profile . emails [ 0 ] . value ;
try {
const userData = await db
. select ( {
user : users ,
vectorDatabase : vectorDatabases ,
} )
. from ( users )
. leftJoin ( vectorDatabases , eq ( users . id , vectorDatabases . userId ) )
. where ( eq ( users . email , email ) ) ;
if (
userData . length === 0 ||
! userData [ 0 ] . vectorDatabase ||
! userData [ 0 ] . user
) {
const { data , error } = await neonApiClient . POST ( "/projects" , {
body : {
project : { } ,
} ,
} ) ;
if ( error ) {
throw new Error ( `Failed to create Neon project, ${ error } ` ) ;
}
const vectorDbId = data ?. project . id ;
const vectorDbConnectionUri = data . connection_uris [ 0 ] ?. connection_uri ;
const sql = postgres ( vectorDbConnectionUri ) ;
await sql `CREATE EXTENSION IF NOT EXISTS vector;` ;
await migrate ( drizzle ( sql ) , { migrationsFolder : "./drizzle" } ) ;
const newUser = await db
. insert ( users )
. values ( {
email ,
name : profile . displayName ,
avatarUrl : profile . photos [ 0 ] . value ,
userId : generateId ( { object : "user" } ) ,
} )
. onConflictDoNothing ( )
. returning ( ) ;
await db
. insert ( vectorDatabases )
. values ( {
vectorDbId ,
userId : newUser [ 0 ] . id ,
} )
. returning ( ) ;
const result = {
... newUser [ 0 ] ,
vectorDbId ,
} ;
return result ;
}
return {
... userData [ 0 ] . user ,
vectorDbId : userData [ 0 ] . vectorDatabase . vectorDbId ,
} ;
} catch ( error ) {
console . error ( "User creation error:" , error ) ;
throw new Error ( getErrorMessage ( error ) ) ;
}
} ,
) ,
) ;
// Code from app/routes/api/document/chat
// Get the user's messages and the document ID from the request body.
const {
messages ,
documentId ,
} : {
messages : Message [ ] ;
documentId : string ;
} = await request . json ( ) ;
const { content : prompt } = messages [ messages . length - 1 ] ;
const { data , error } = await neonApiClient . GET (
"/projects/{project_id}/connection_uri" ,
{
params : {
path : {
project_id : user . vectorDbId ,
} ,
query : {
role_name : "neondb_owner" ,
database_name : "neondb" ,
} ,
} ,
} ,
) ;
if ( error ) {
return json ( {
error : error ,
} ) ;
}
const embeddings = new OpenAIEmbeddings ( {
apiKey : process . env . OPENAI_API_KEY ,
dimensions : 1536 ,
model : "text-embedding-3-small" ,
} ) ;
const vectorStore = await NeonPostgres . initialize ( embeddings , {
connectionString : data . uri ,
tableName : "embeddings" ,
columns : {
contentColumnName : "content" ,
metadataColumnName : "metadata" ,
vectorColumnName : "embedding" ,
} ,
} ) ;
const result = await vectorStore . similaritySearch ( prompt , 2 , {
documentId ,
} ) ;
const model = new ChatOpenAI ( {
apiKey : process . env . OPENAI_API_KEY ,
model : "gpt-4o-mini" ,
temperature : 0 ,
} ) ;
const allMessages = messages . map ( ( message ) =>
message . role === "user"
? new HumanMessage ( message . content )
: new AIMessage ( message . content ) ,
) ;
const systemMessage = new SystemMessage (
`You are a helpful assistant, here's some extra additional context that you can use to answer questions. Only use this information if it's relevant:
${ result . map ( ( r ) => r . pageContent ) . join ( " " ) } ` ,
) ;
allMessages . push ( systemMessage ) ;
const stream = await model . stream ( allMessages ) ;
return LangChainAdapter . toDataStreamResponse ( stream ) ;이 접근법은 유익하지만 구현하기가 어려울 수도 있습니다. 프로비저닝, 스케일링 및 해제를 포함하여 각 데이터베이스의 수명주기를 관리해야합니다. 다행히도 Neon의 Postgres는 다르게 설정됩니다.
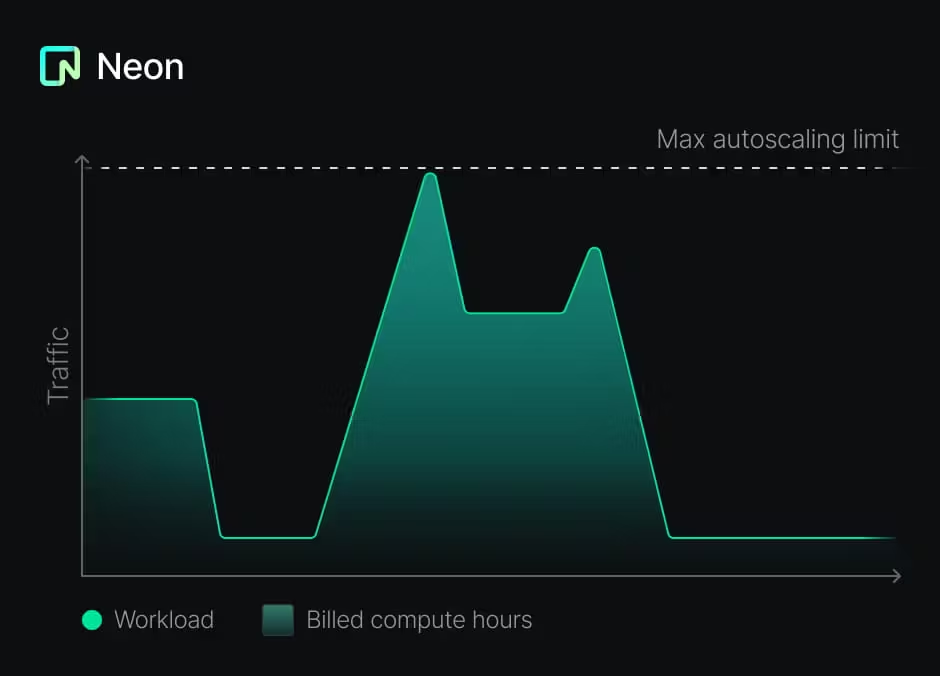
이를 통해 임차인 당 데이터베이스를 작성하는 제안 된 패턴은 가능할뿐만 아니라 비용 효율적입니다.
테넌트 당 데이터베이스가 있으면 각 데이터베이스의 마이그레이션을 관리해야합니다. 이 프로젝트는 이슬비를 사용합니다.
/app/lib/vector-db/schema.ts 에 정의됩니다.bun run vector-db:generate /app/lib/vector-db/migrations 에 저장합니다.bun run vector-db:migrate 실행할 수 있습니다. 이 명령은 각 임차인의 데이터베이스에 연결하고 마이그레이션을 적용하는 스크립트를 실행합니다.소개하려는 스키마 변경은 뒤로 호환되어야한다는 점에 유의해야합니다. 그렇지 않으면 스키마 마이그레이션을 다르게 처리해야합니다.
이 패턴은 AI 애플리케이션을 구축하는 데 유용하지만 각 임차인에게 자체 데이터베이스를 제공하는 데 간단히 사용할 수 있습니다. 메인 애플리케이션 데이터베이스 (예 : MySQL, MongoDB, MSSQL 서버 등)에 Postgres 이외의 데이터베이스를 사용할 수도 있습니다.
궁금한 점이 있으시면 Neon Discord에 문의하거나 Neon Sales 팀에 문의하십시오. 우리는 당신의 의견을 듣고 싶습니다.


