db per tenant
1.0.0
此存储库包含一个用于AI驱动应用程序的可扩展体系结构的示例。从表面上看,这是一个AI应用程序,用户可以上传PDF并与他们聊天。但是,在引擎盖下,每个用户都会获得一个专用的矢量数据库实例(postgres with pgvector上的霓虹灯)。
您可以在https://db-per-tenant.up.railway.app/上查看实时版本
该应用是使用以下技术构建的:
您没有将所有向量嵌入存储在单个Postgres数据库中,而是提供每个租户(用户,组织,工作区或任何其他需要隔离的实体)的租户使用其自己的专用Postgres数据库实例,您可以在其中存储和查询其嵌入。
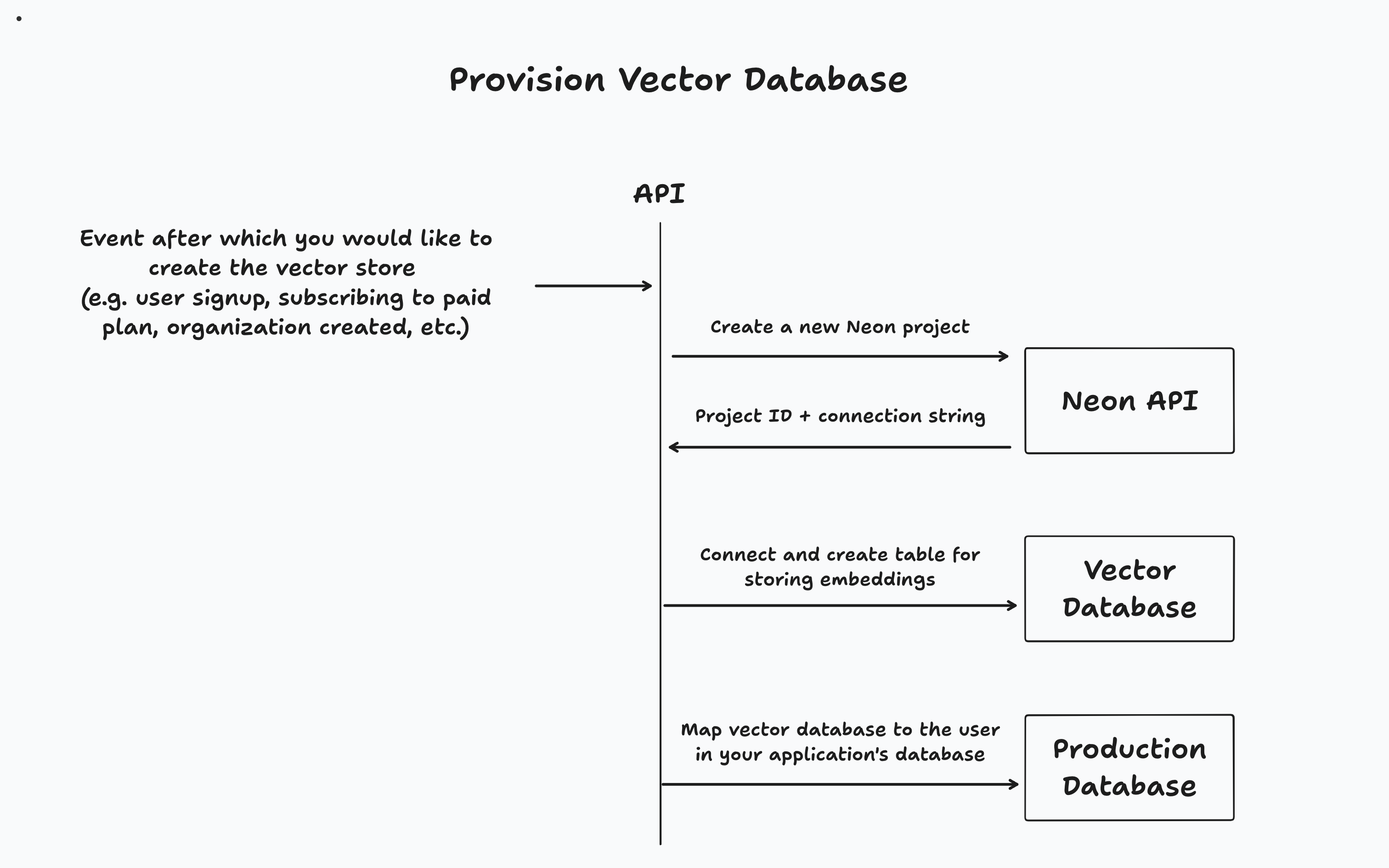
根据您的应用程序,您将在特定事件发生后(例如,用户注册,组织创建或升级到付费层)后提供矢量数据库。然后,您将在应用程序的主数据库中跟踪租户及其关联的矢量数据库。
这种方法提供了几个好处:
这是此存储库中的演示应用程序的数据库体系结构图:
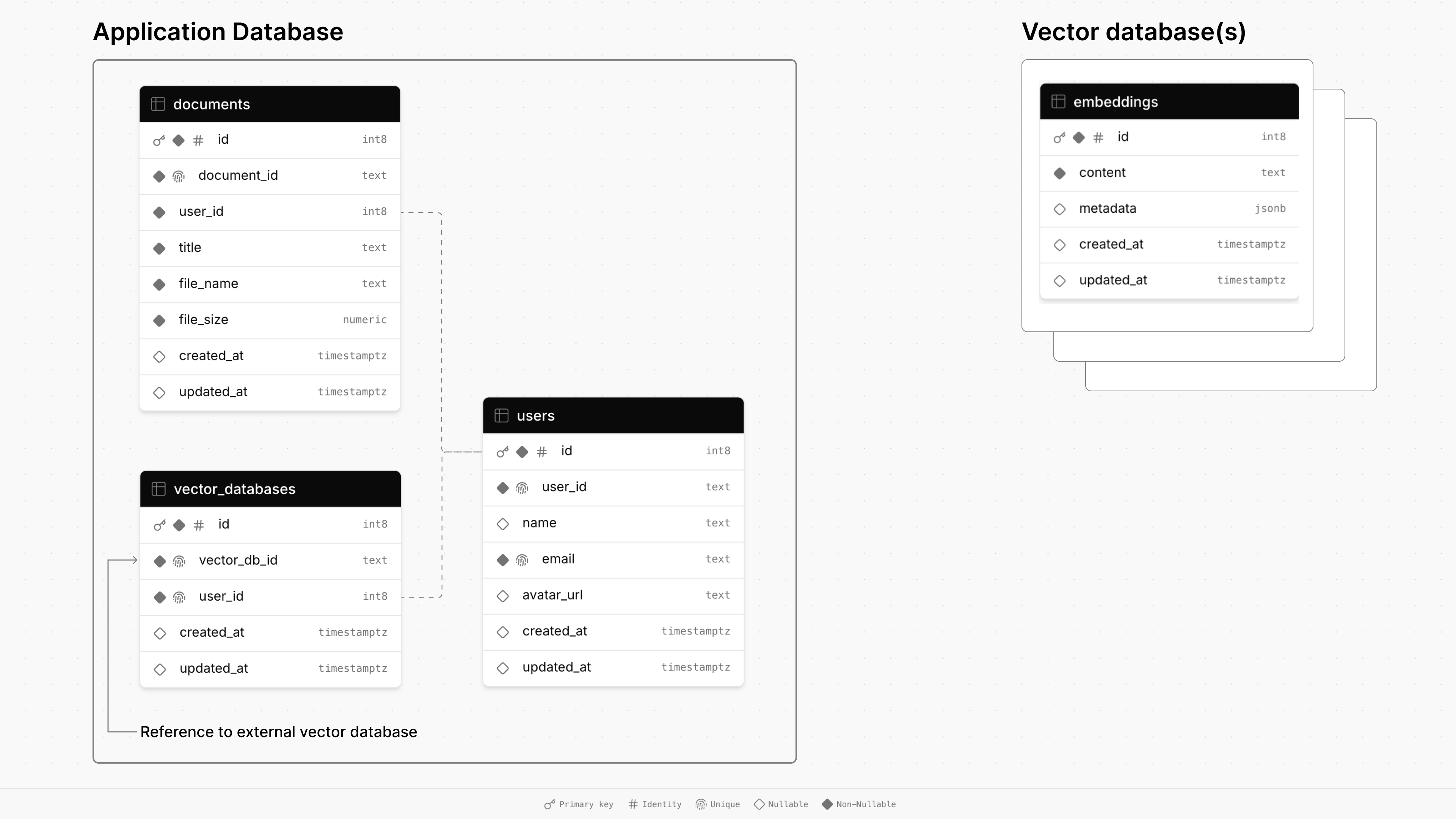
主应用程序的数据库由三个表组成: documents , users和vector_databases 。
documents表存储有关文件的信息,包括其标题,大小和时间戳,并通过外键链接到用户。users表维护用户配置文件,包括名称,电子邮件和头像URL。vector_databases表跟踪哪个向量数据库属于哪个用户。然后,每个配置的矢量数据库都有一个用于存储文档块的embeddings表,以进行检索 - 演示生成(RAG)。
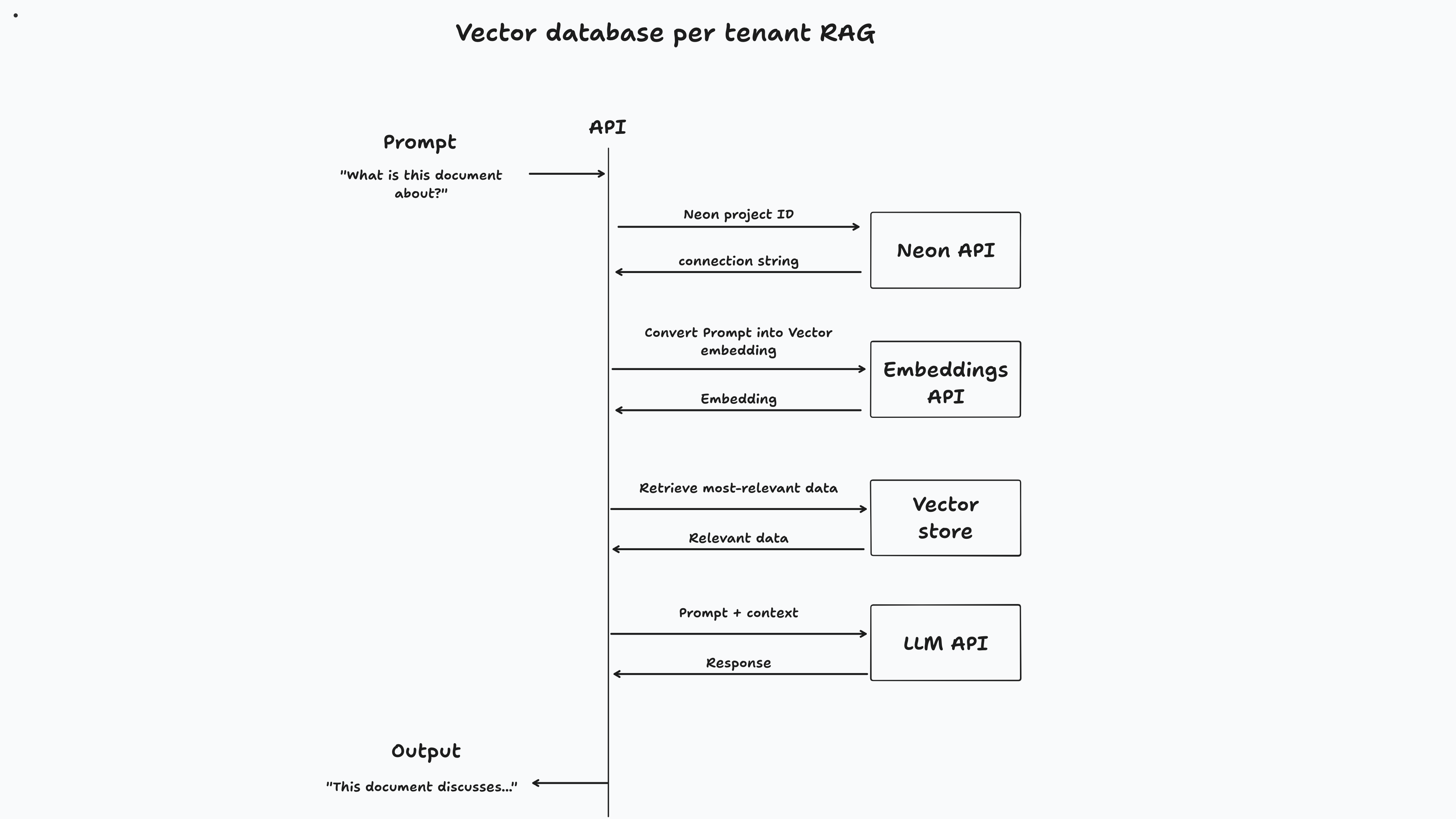
对于此应用程序,用户登录时将提供矢量数据库。一旦上传文档,它就会块并存储在其专用矢量数据库中。最后,一旦用户与文档聊天,矢量相似性搜索将在其数据库中运行以检索相关信息以回答其提示。
// Code from app/lib/auth.ts
authenticator . use (
new GoogleStrategy (
{
clientID : process . env . GOOGLE_CLIENT_ID ,
clientSecret : process . env . GOOGLE_CLIENT_SECRET ,
callbackURL : process . env . GOOGLE_CALLBACK_URL ,
} ,
async ( { profile } ) => {
const email = profile . emails [ 0 ] . value ;
try {
const userData = await db
. select ( {
user : users ,
vectorDatabase : vectorDatabases ,
} )
. from ( users )
. leftJoin ( vectorDatabases , eq ( users . id , vectorDatabases . userId ) )
. where ( eq ( users . email , email ) ) ;
if (
userData . length === 0 ||
! userData [ 0 ] . vectorDatabase ||
! userData [ 0 ] . user
) {
const { data , error } = await neonApiClient . POST ( "/projects" , {
body : {
project : { } ,
} ,
} ) ;
if ( error ) {
throw new Error ( `Failed to create Neon project, ${ error } ` ) ;
}
const vectorDbId = data ?. project . id ;
const vectorDbConnectionUri = data . connection_uris [ 0 ] ?. connection_uri ;
const sql = postgres ( vectorDbConnectionUri ) ;
await sql `CREATE EXTENSION IF NOT EXISTS vector;` ;
await migrate ( drizzle ( sql ) , { migrationsFolder : "./drizzle" } ) ;
const newUser = await db
. insert ( users )
. values ( {
email ,
name : profile . displayName ,
avatarUrl : profile . photos [ 0 ] . value ,
userId : generateId ( { object : "user" } ) ,
} )
. onConflictDoNothing ( )
. returning ( ) ;
await db
. insert ( vectorDatabases )
. values ( {
vectorDbId ,
userId : newUser [ 0 ] . id ,
} )
. returning ( ) ;
const result = {
... newUser [ 0 ] ,
vectorDbId ,
} ;
return result ;
}
return {
... userData [ 0 ] . user ,
vectorDbId : userData [ 0 ] . vectorDatabase . vectorDbId ,
} ;
} catch ( error ) {
console . error ( "User creation error:" , error ) ;
throw new Error ( getErrorMessage ( error ) ) ;
}
} ,
) ,
) ;
// Code from app/routes/api/document/chat
// Get the user's messages and the document ID from the request body.
const {
messages ,
documentId ,
} : {
messages : Message [ ] ;
documentId : string ;
} = await request . json ( ) ;
const { content : prompt } = messages [ messages . length - 1 ] ;
const { data , error } = await neonApiClient . GET (
"/projects/{project_id}/connection_uri" ,
{
params : {
path : {
project_id : user . vectorDbId ,
} ,
query : {
role_name : "neondb_owner" ,
database_name : "neondb" ,
} ,
} ,
} ,
) ;
if ( error ) {
return json ( {
error : error ,
} ) ;
}
const embeddings = new OpenAIEmbeddings ( {
apiKey : process . env . OPENAI_API_KEY ,
dimensions : 1536 ,
model : "text-embedding-3-small" ,
} ) ;
const vectorStore = await NeonPostgres . initialize ( embeddings , {
connectionString : data . uri ,
tableName : "embeddings" ,
columns : {
contentColumnName : "content" ,
metadataColumnName : "metadata" ,
vectorColumnName : "embedding" ,
} ,
} ) ;
const result = await vectorStore . similaritySearch ( prompt , 2 , {
documentId ,
} ) ;
const model = new ChatOpenAI ( {
apiKey : process . env . OPENAI_API_KEY ,
model : "gpt-4o-mini" ,
temperature : 0 ,
} ) ;
const allMessages = messages . map ( ( message ) =>
message . role === "user"
? new HumanMessage ( message . content )
: new AIMessage ( message . content ) ,
) ;
const systemMessage = new SystemMessage (
`You are a helpful assistant, here's some extra additional context that you can use to answer questions. Only use this information if it's relevant:
${ result . map ( ( r ) => r . pageContent ) . join ( " " ) } ` ,
) ;
allMessages . push ( systemMessage ) ;
const stream = await model . stream ( allMessages ) ;
return LangChainAdapter . toDataStreamResponse ( stream ) ;尽管这种方法是有益的,但实施也可能具有挑战性。您需要管理每个数据库的生命周期,包括配置,扩展和脱机。幸运的是,霓虹灯上的Postgres的设置不同:
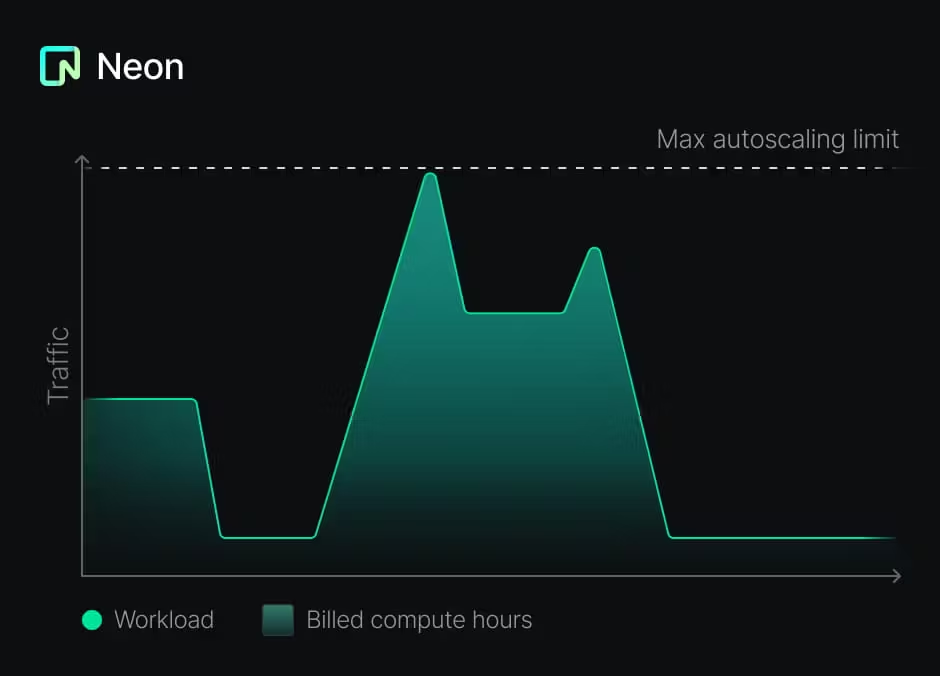
这使得为每个租户创建数据库的建议模式不仅可能,而且具有成本效益。
当您有每个租户的数据库时,您需要管理每个数据库的迁移。该项目使用毛毛雨:
/app/lib/vector-db/schema.ts中定义的。bun run vector-db:generate并存储在/app/lib/vector-db/migrations中来生成迁移。bun run vector-db:migrate 。此命令将运行一个连接到每个租户数据库并应用迁移的脚本。重要的是要注意,您想引入的任何模式更改都应该向后兼容。否则,您需要以不同的方式处理模式迁移。
尽管此模式可用于构建AI应用程序,但您只需使用它即可为每个租户提供自己的数据库。您也可以在主应用程序的数据库中使用Postgres以外的数据库(例如MySQL,MongoDB,MSSQL Server等)。
如果您有任何疑问,请随时与霓虹灯不和谐联系或与霓虹灯销售团队联系。我们很想听听您的来信。


